Processos Pontuais
Aula 07: Teoria e Prática em R
02/02/2026

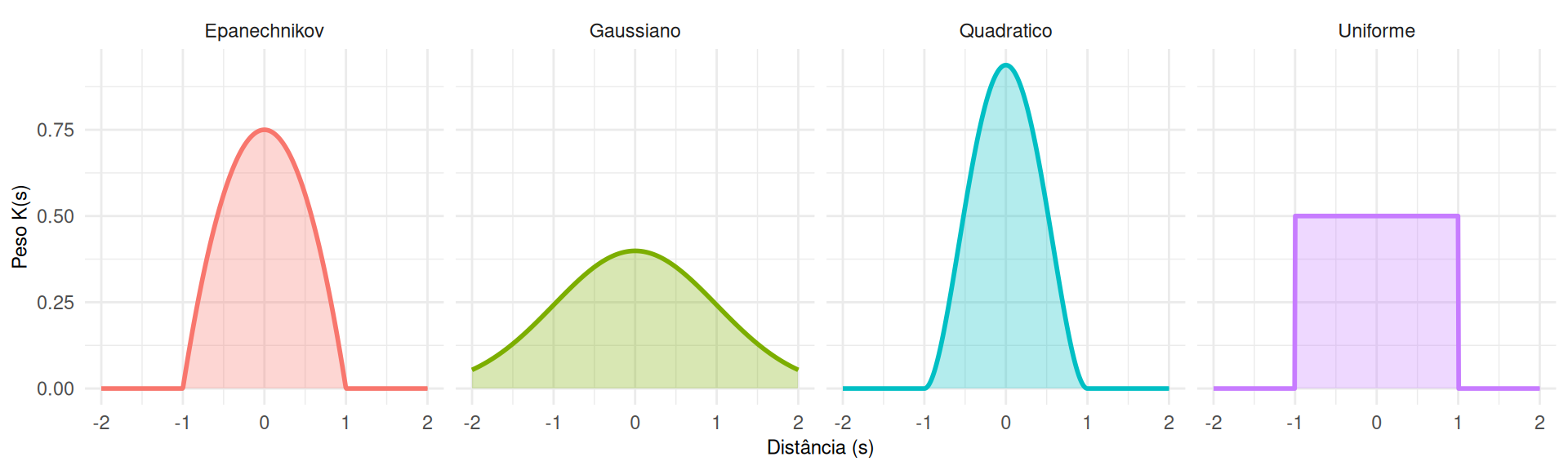




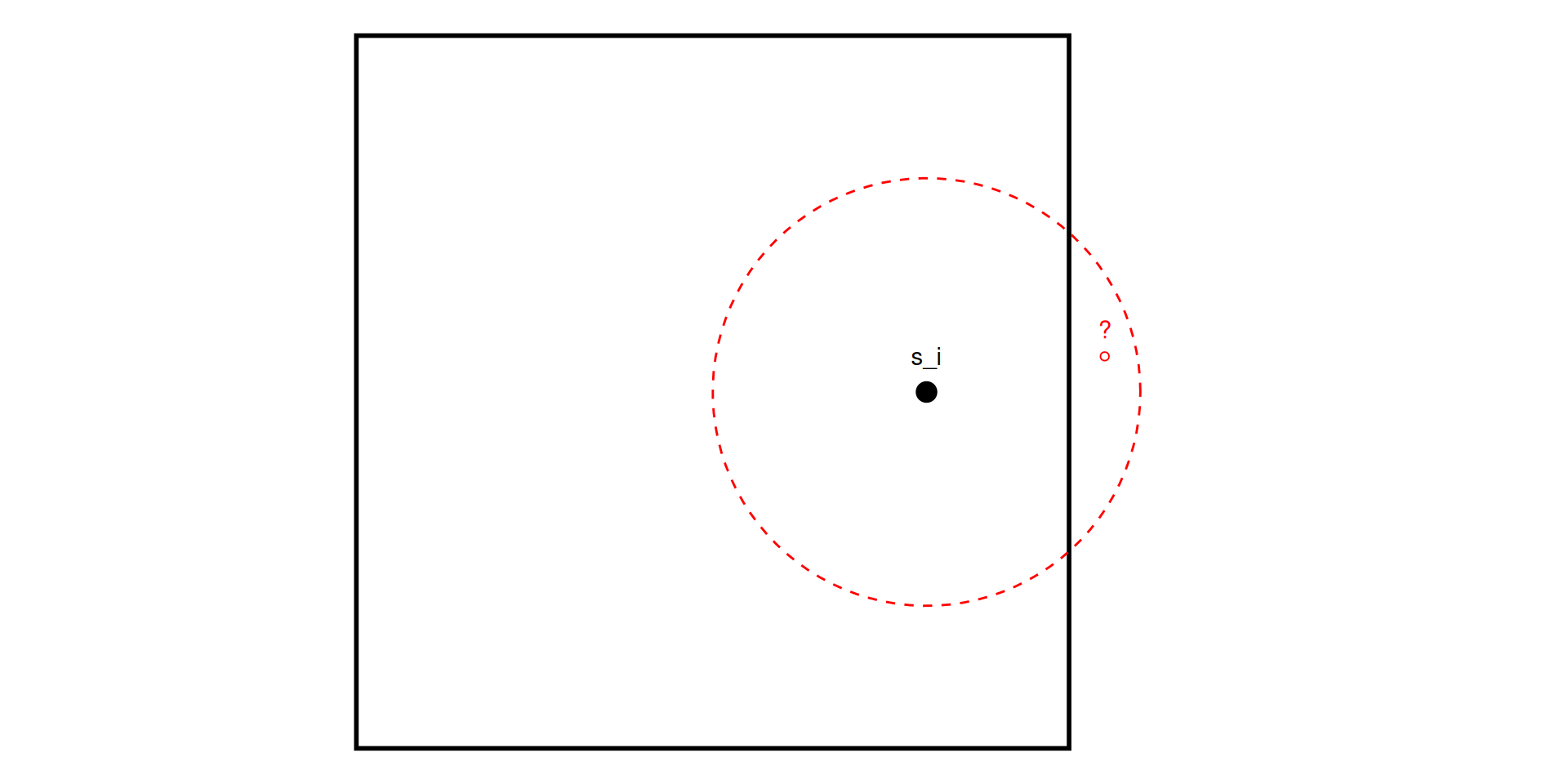
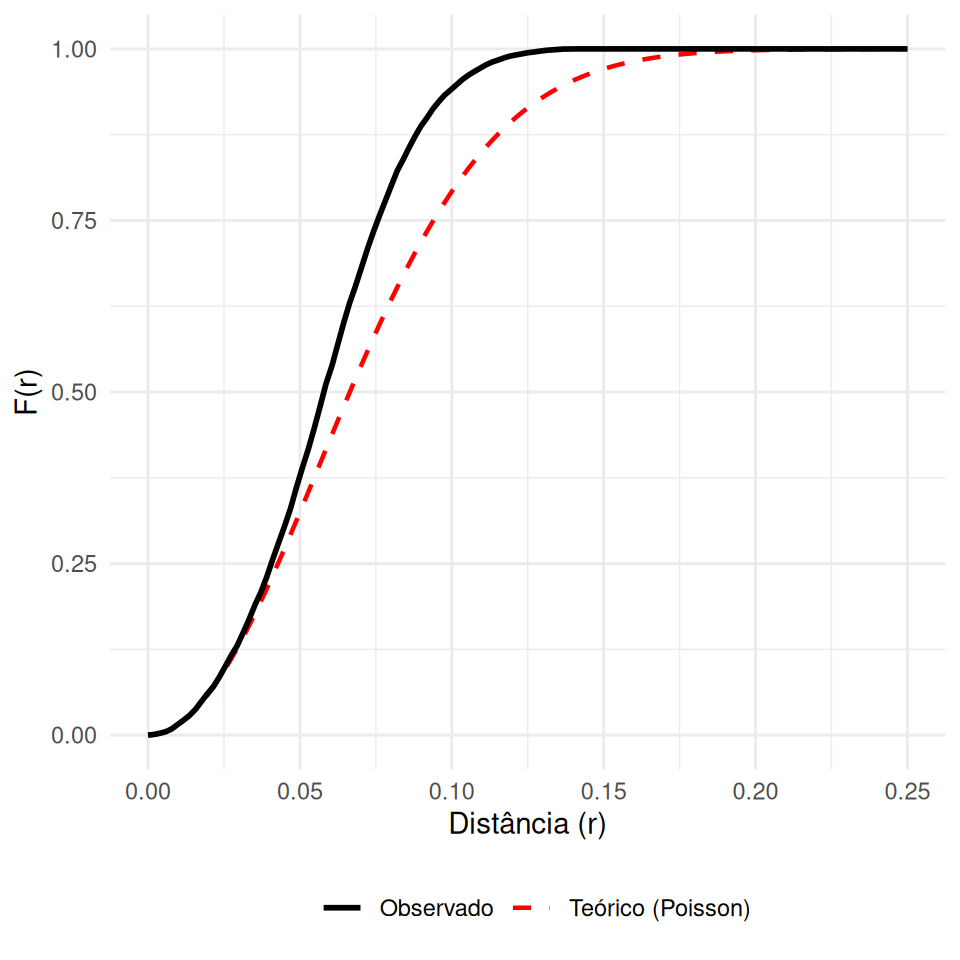
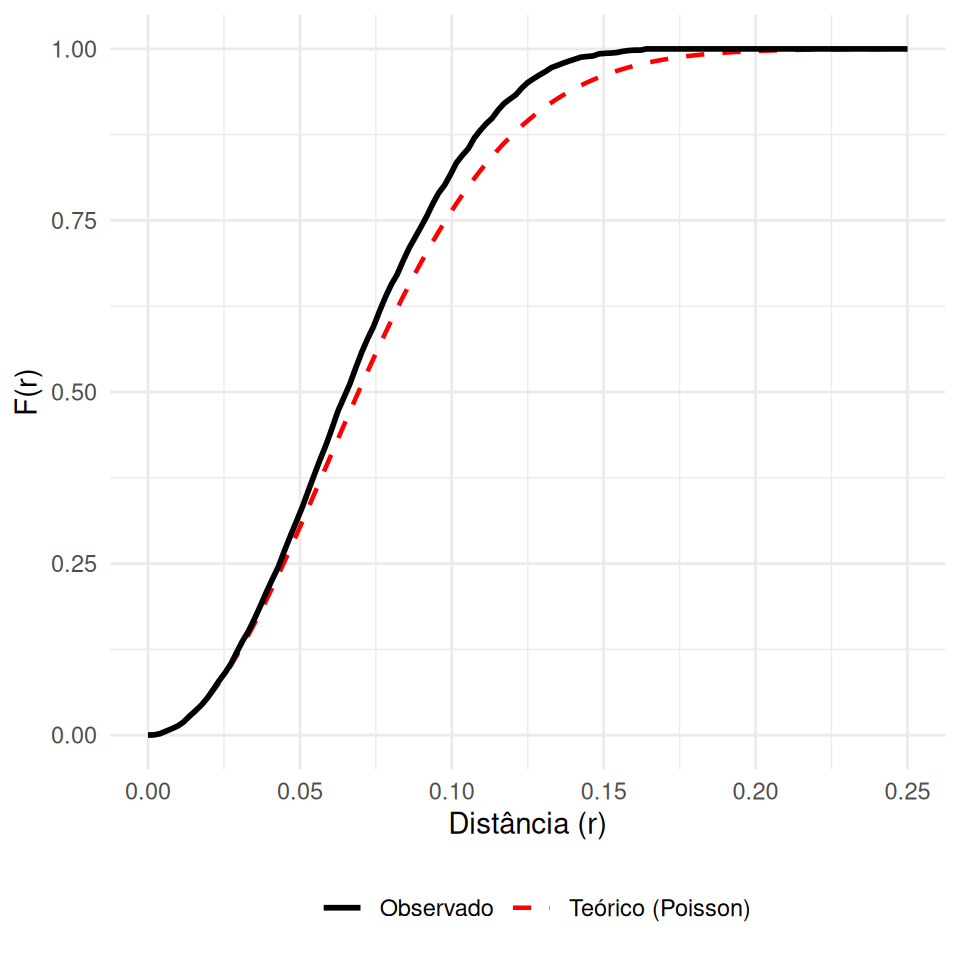
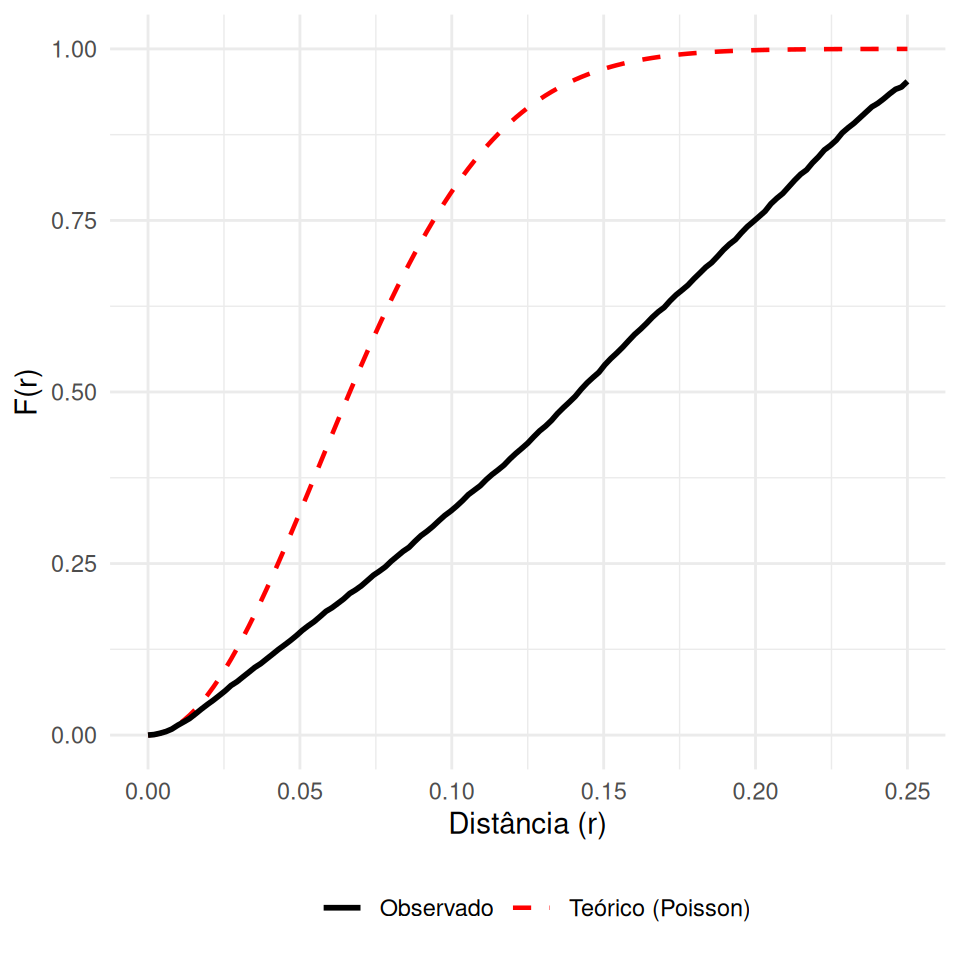
Mede a distribuição das distâncias de um ponto arbitrário \(z\) (no espaço vazio) até o evento mais próximo \(s_i\).
\[ F(r)= P\{d(z, s_{i})\leq r\} \]
Estimador:
\[ \hat{F}(r) = \frac{1}{n(z)} \sum_{k=1}^{K} \mathbb{I}\left\{d(z_{k}, s_{i})\leq r\right\} \]
\(\hat{F}(r) > F_{pois}(r)\): Regular (Menos espaço vazio).
\(\hat{F}(r) < F_{pois}(r)\): Agrupado (Mais espaço vazio, grandes lacunas).
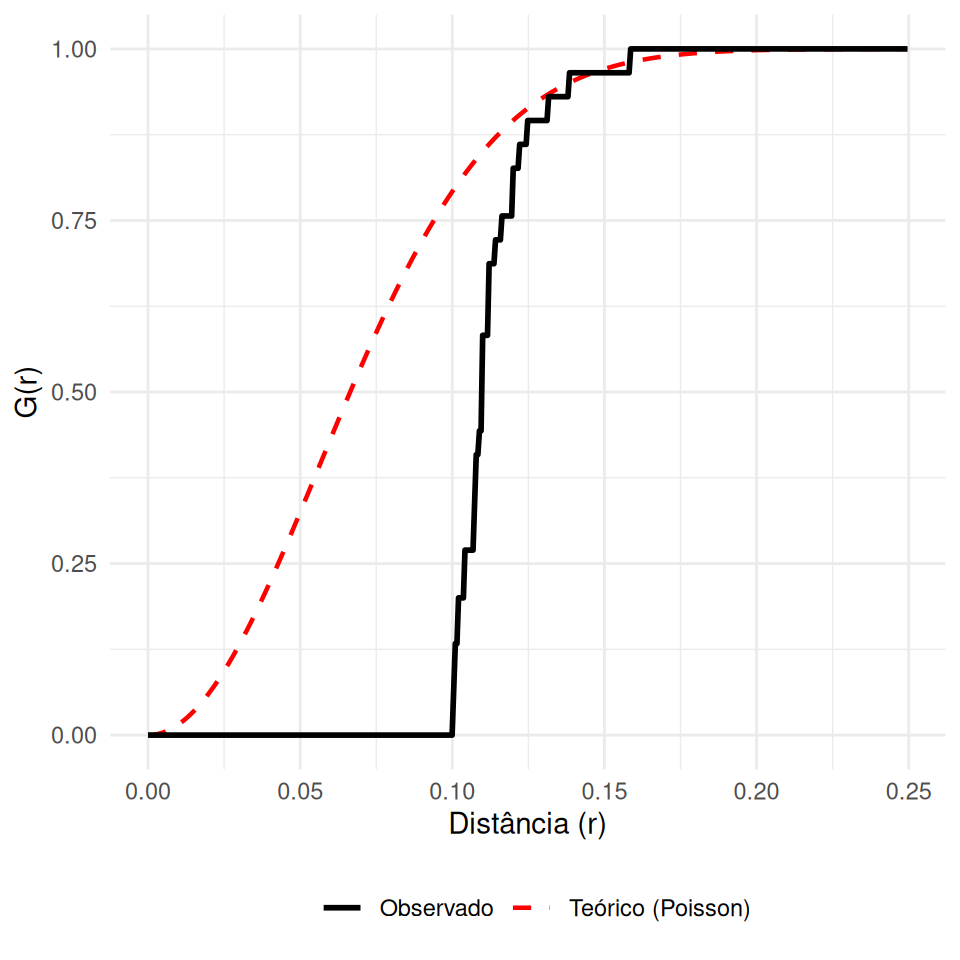
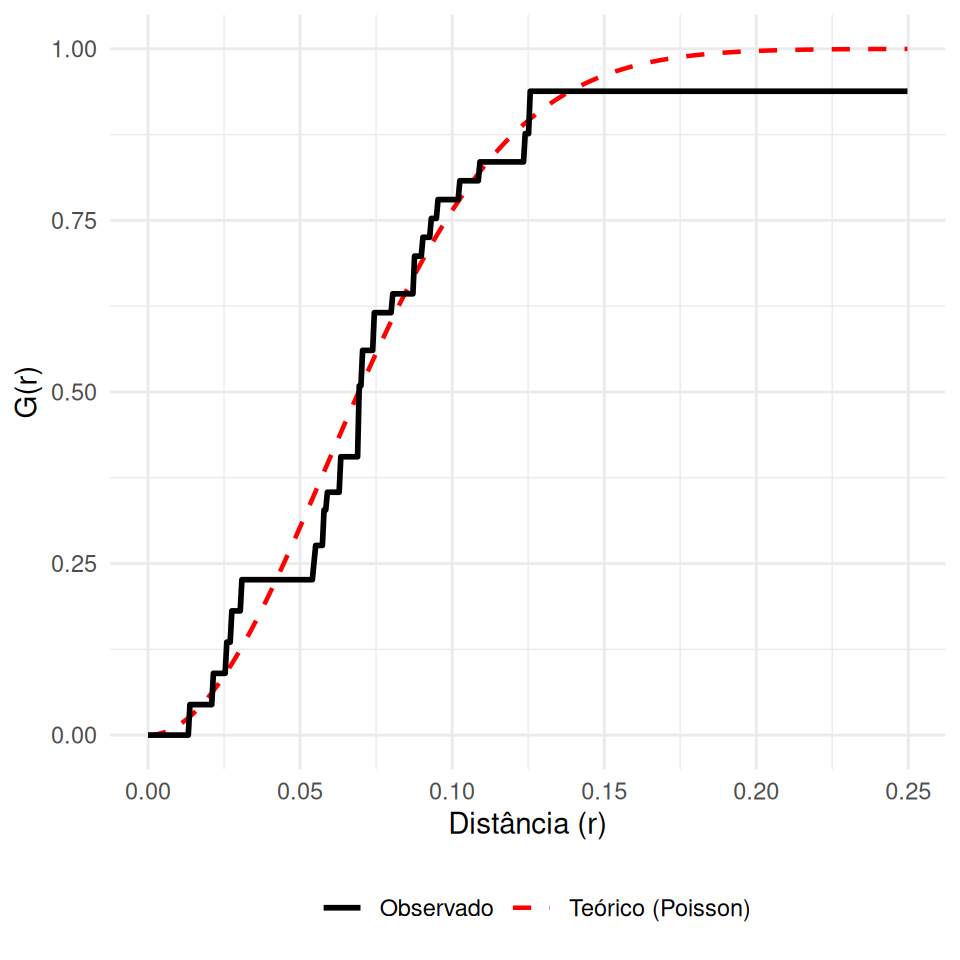
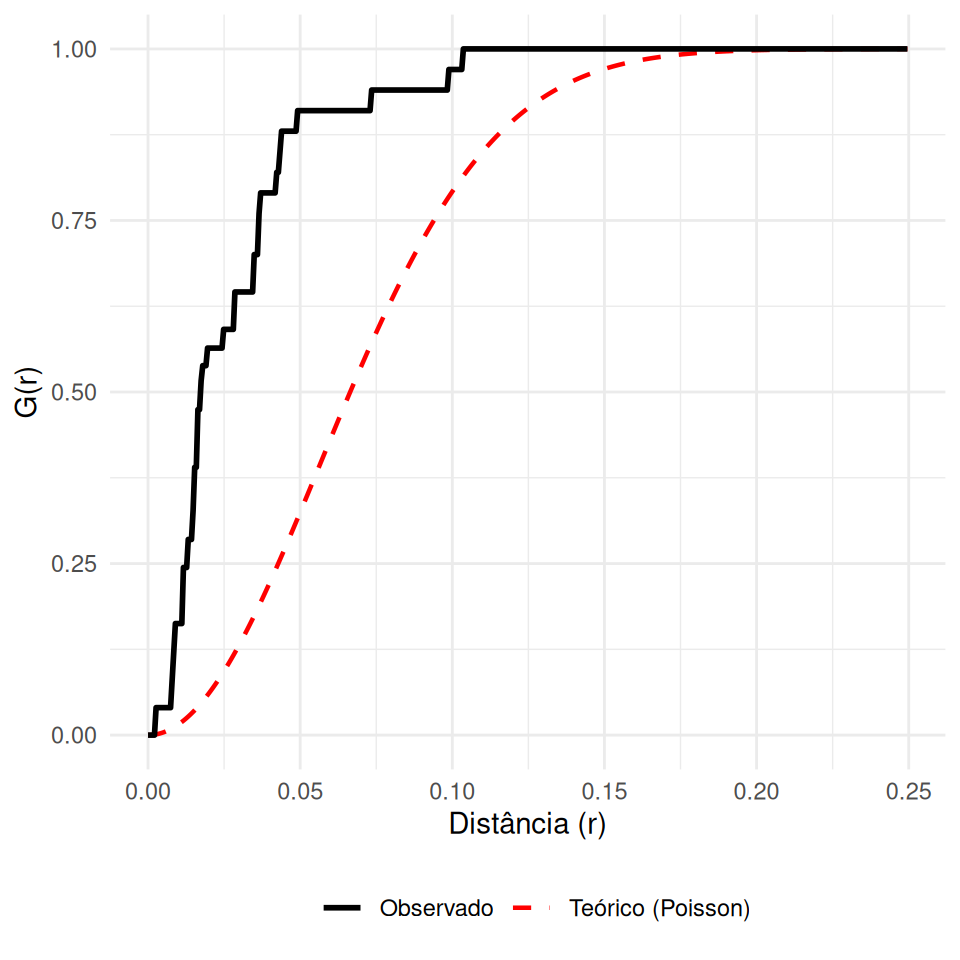
Mede a distribuição das distâncias de um evento \(s_i\) até o seu vizinho mais próximo \(s_j\).
\[G(r)=P\{d(s_{i}, s_{i^{'}} \setminus s_{i})\leq r \}\]
Estimador:
\[\hat{G} (r)=\frac{1}{n(s)} \sum_{i} \mathbb{I}\left\{d_{min}\leq r\right\}\]
\(\hat{G}(r) < G_{pois}(r)\): Regular (Vizinhos afastados).
\(\hat{G}(r) > G_{pois}(r)\): Agrupado (Vizinhos muito próximos).
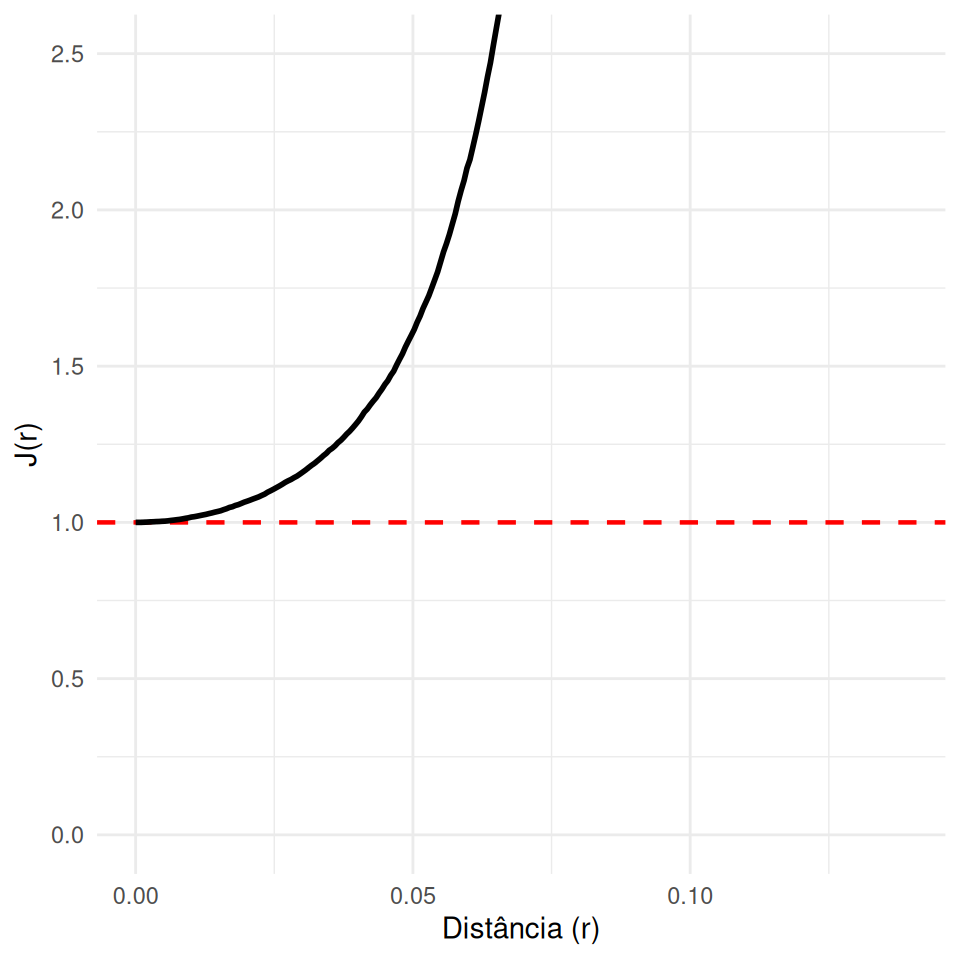
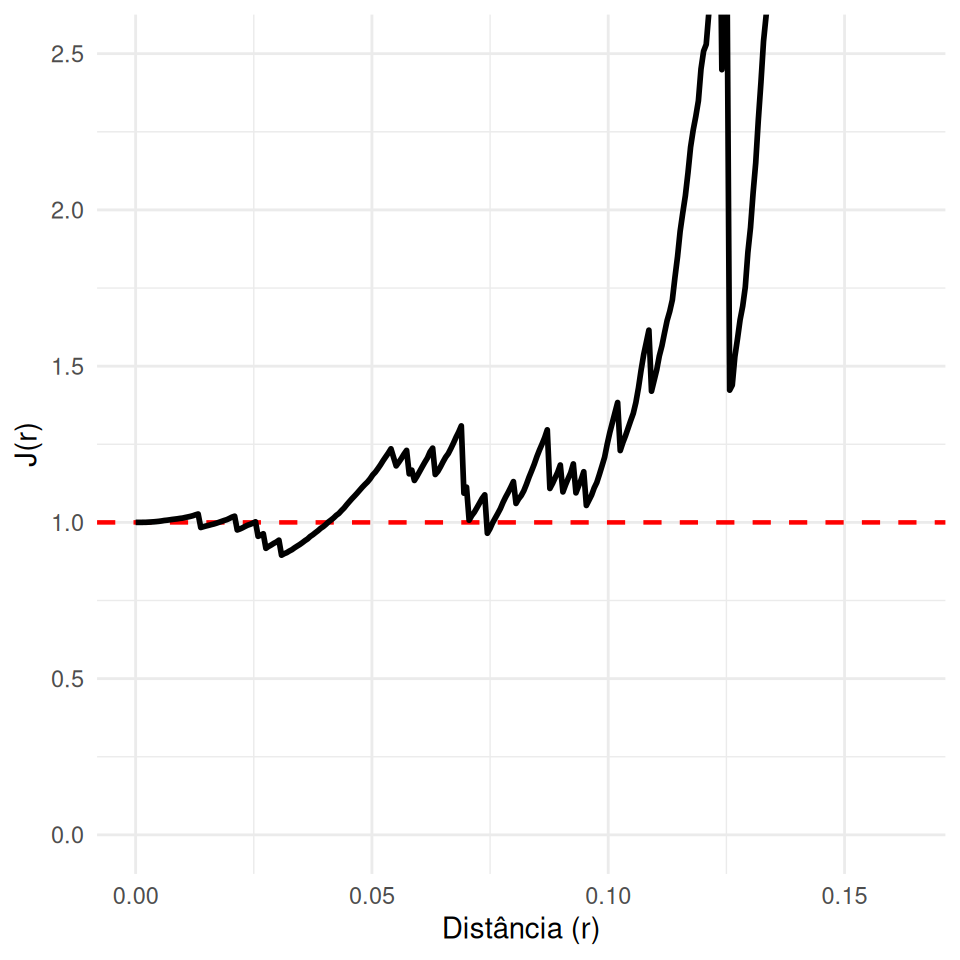
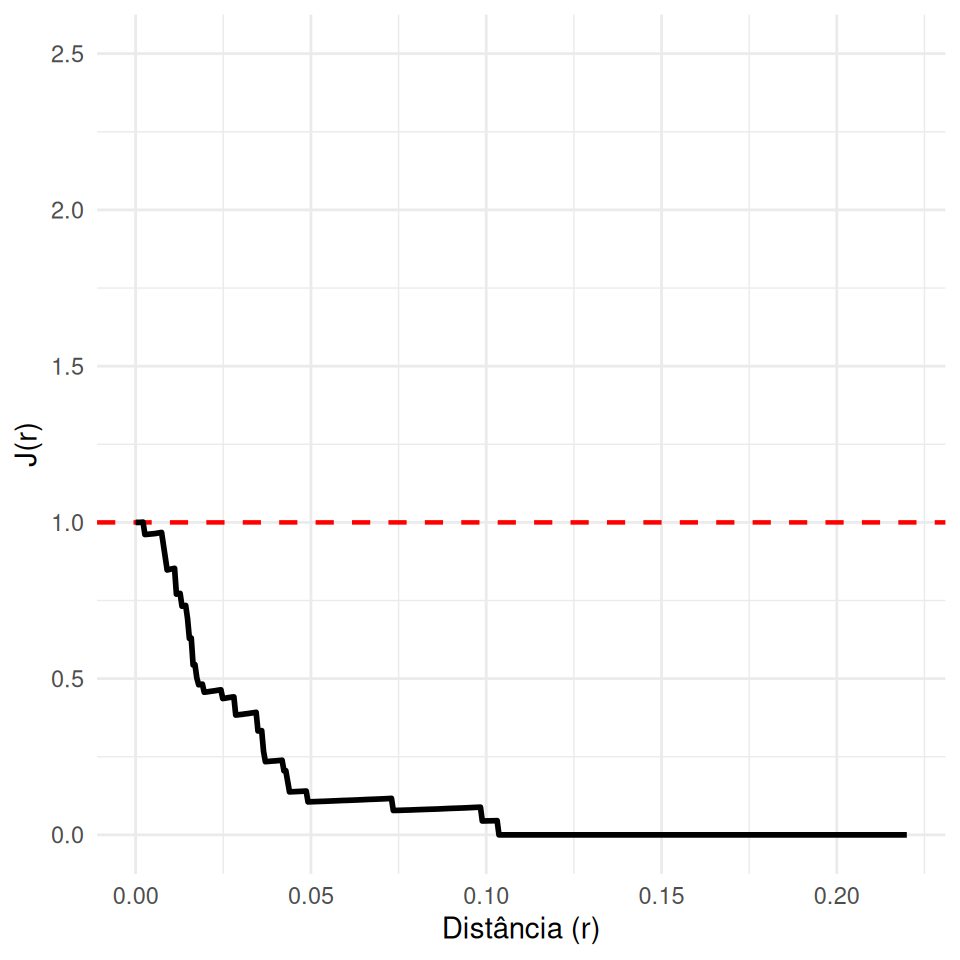
- Combina as informações de espaço vazio (\(F\)) e interação (\(G\)) em um único indicador sem viés.
\[J(r) = \frac{1-G(r)}{1-F(r)}\]
Regular (Inibição): \(J(r) > 1\)
- Eventos evitam ficar próximos, mas preenchem o espaço uniformemente.
Aleatório (Poisson): \(J(r) = 1\)
- Independência total.
Agrupado (Cluster): \(J(r) < 1\)
- Eventos próximos uns dos outros, deixando grandes vazios.
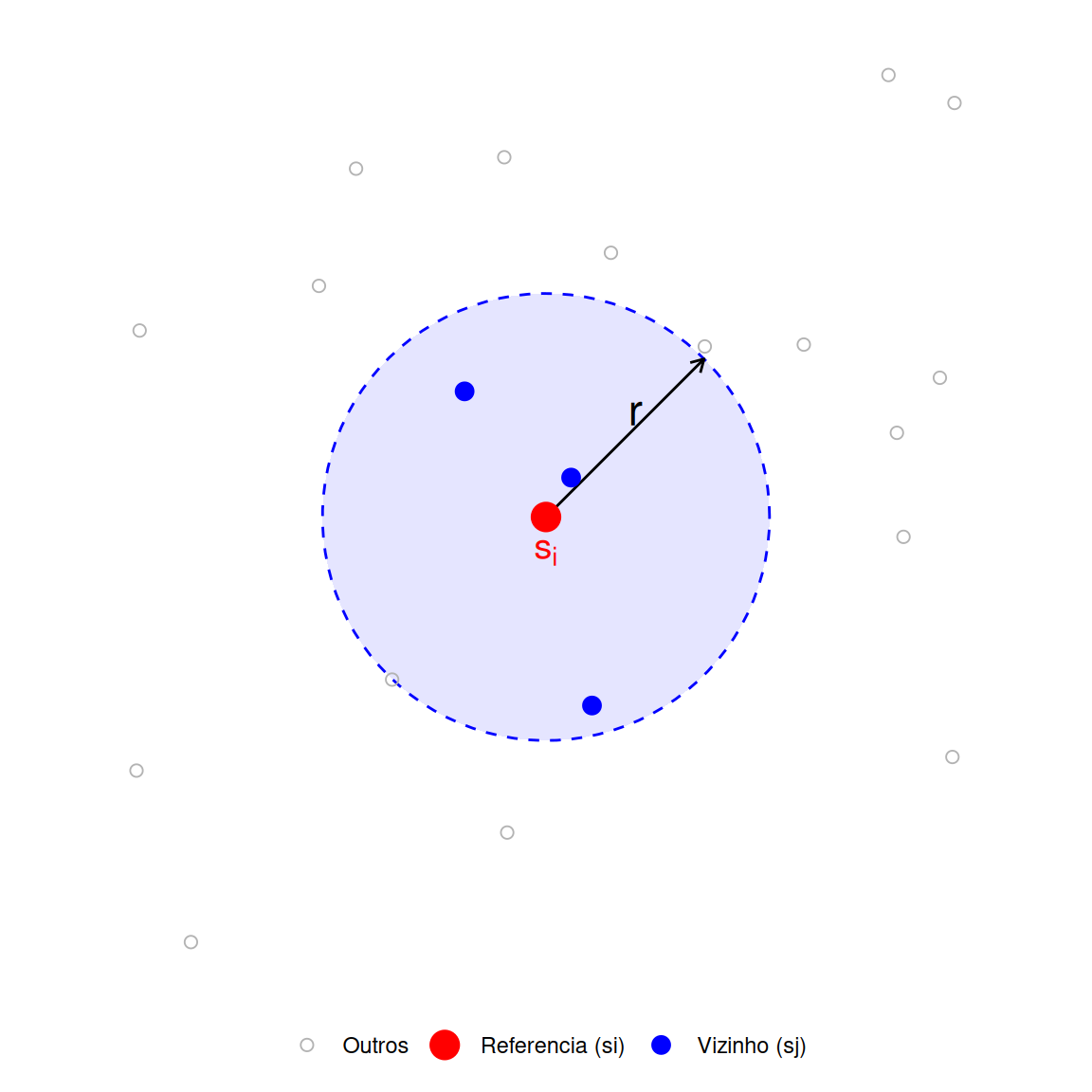
Estimadores de distância sofrem viés nas margens da região de estudo (censura).
A distância observada para o vizinho mais próximo dentro da janela (\(d_{min}\)) pode ser maior do que a distância real para um vizinho fora da janela.
Isso superestima as distâncias e distorce \(F\) e \(G\).
A função \(K(r)\) estima o número esperado de vizinhos extras dentro de uma distância \(r\) de um evento arbitrário, normalizado pela intensidade \(\lambda\).
\[ K(r) = \frac{ \mathbb{E}[\text{Nº de eventos extras dentro da dist. } r]}{\lambda} \]
Estimador:
\[ \hat{K}(r)=\frac{1}{\hat{\lambda}^2 |B|}\sum_{i \neq j} \mathbb{I} (d_{ij} \leq r) e_{ij} \]
\(e_{ij}\): Correção de borda.
\(|B|\): Área da região.
Regular: \(\hat{K}(r) < \pi r^2\) (Menos vizinhos que o esperado).
Aleatório: \(\hat{K}(r) \approx \pi r^2\).
Agrupado: \(\hat{K}(r) > \pi r^2\) (Mais vizinhos que o esperado).
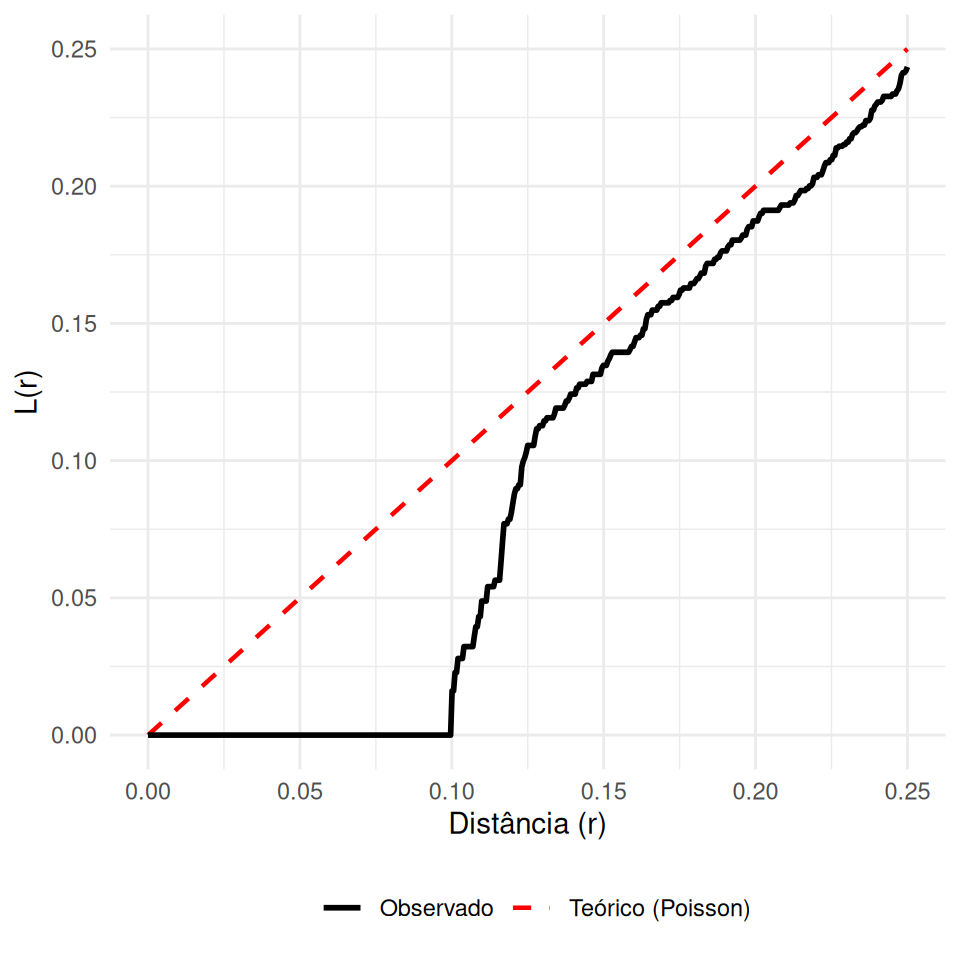
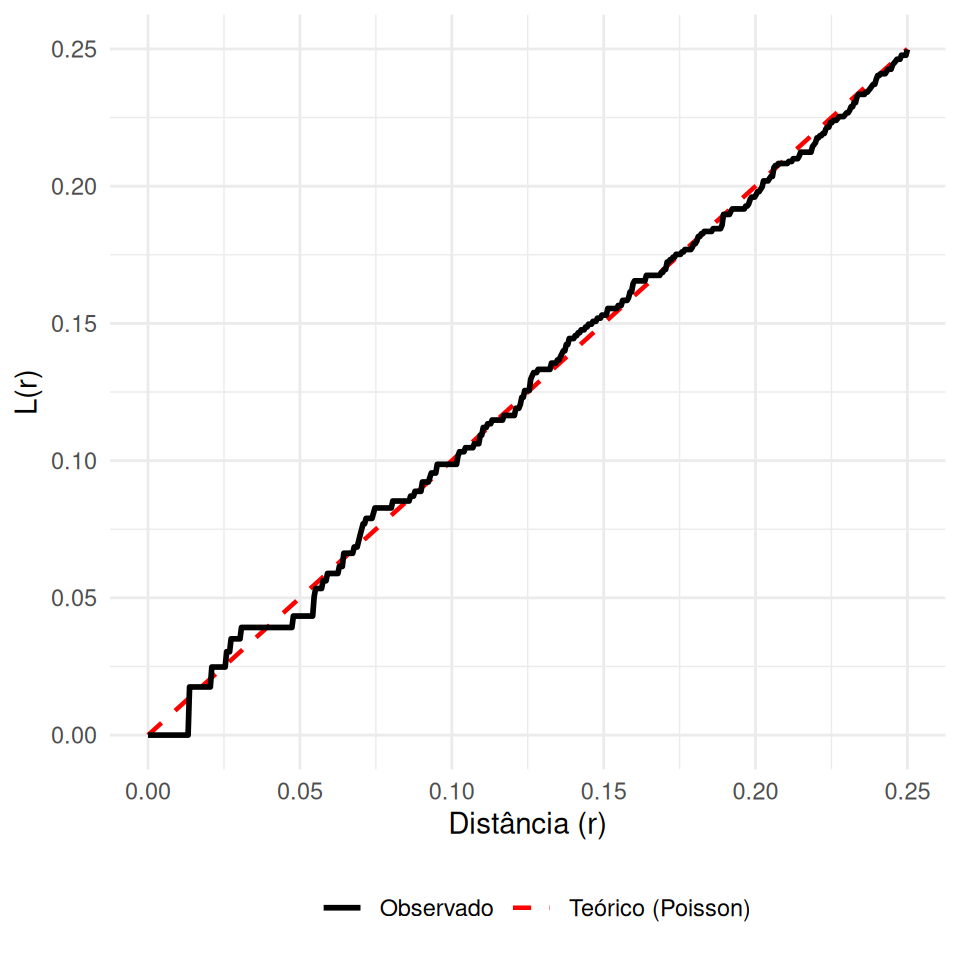
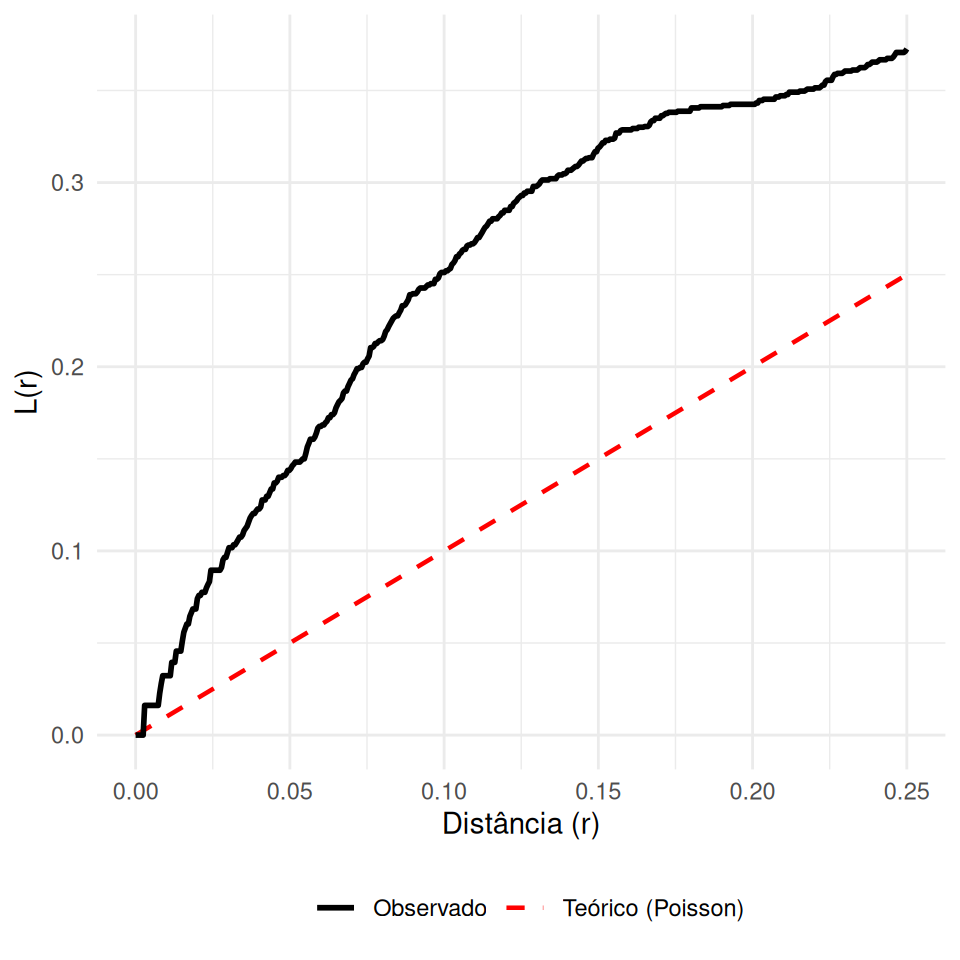
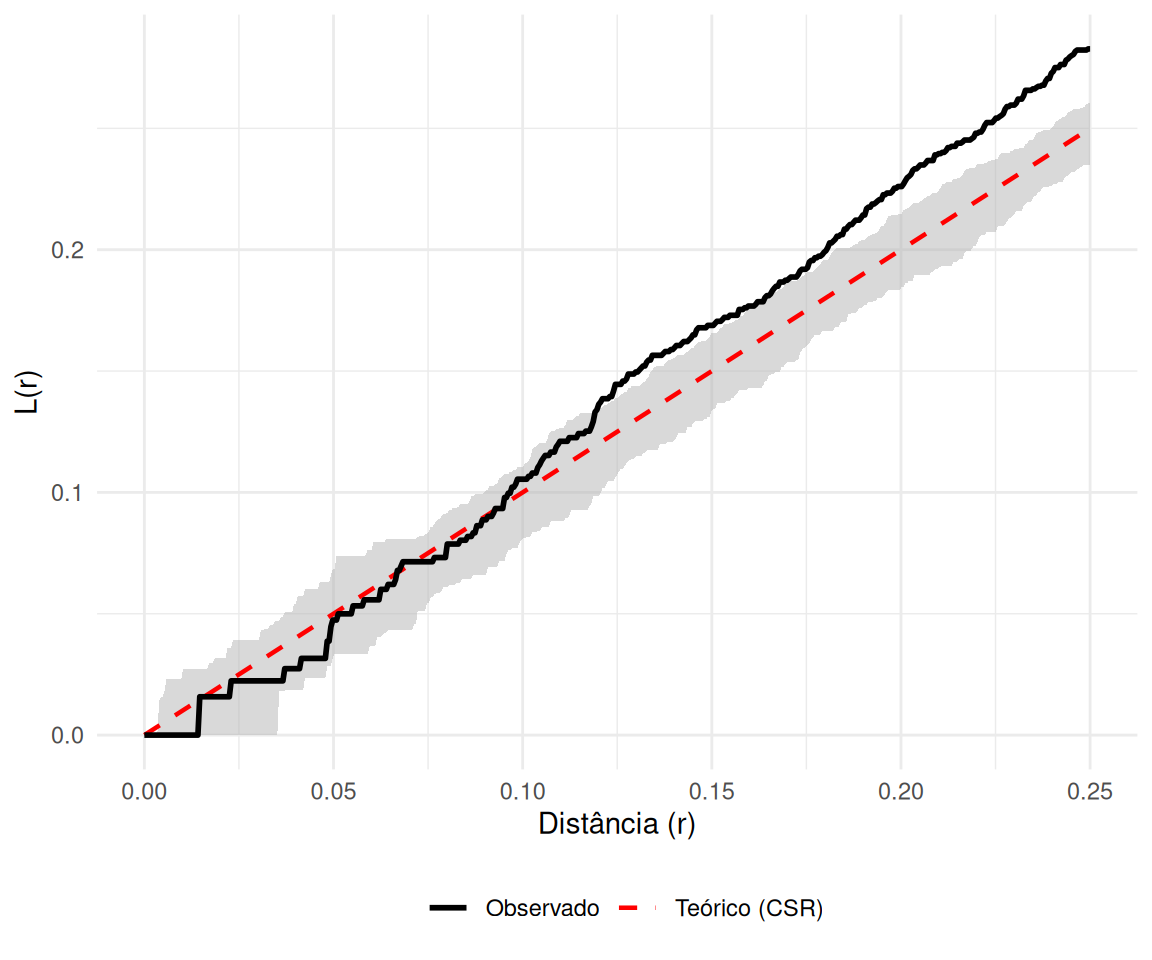
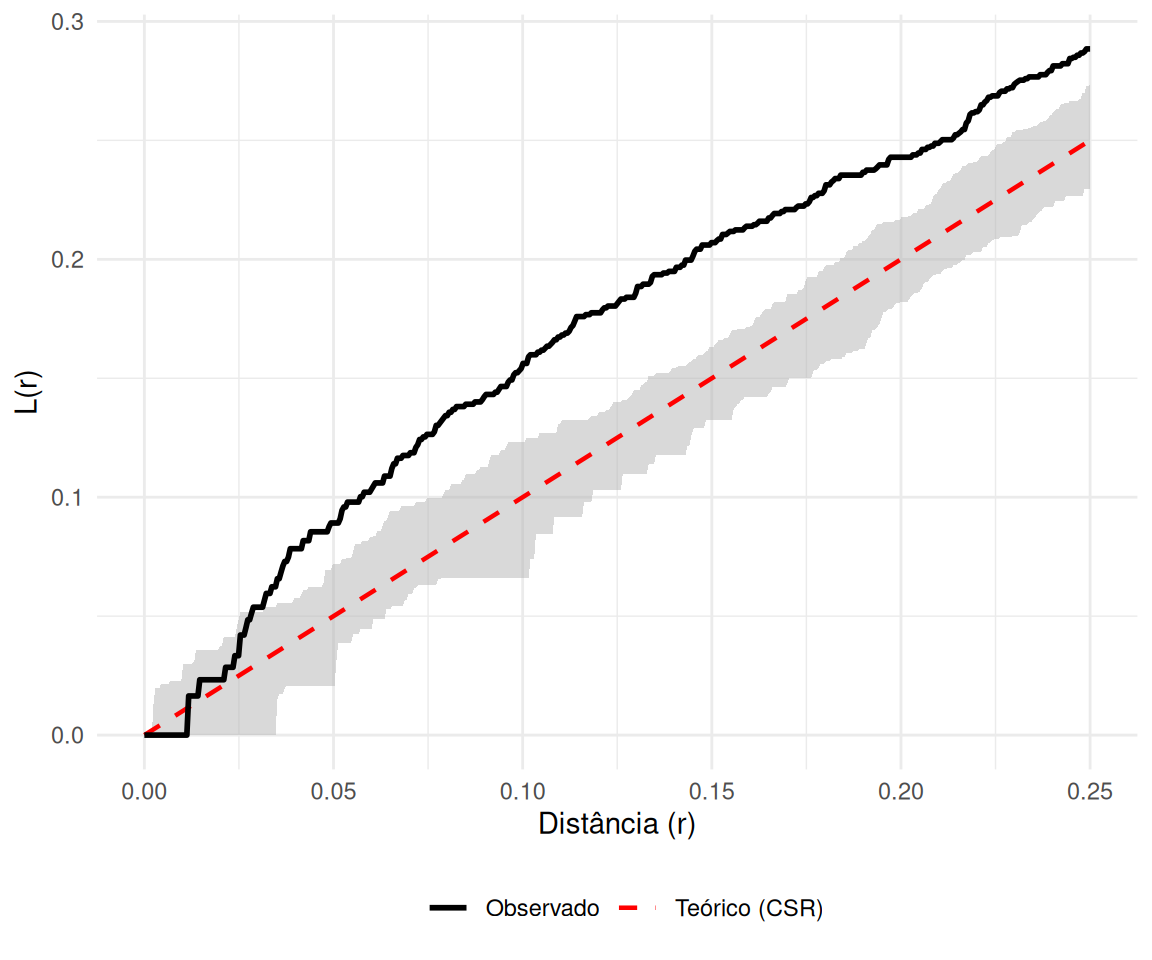
A função \(L(r)\) é uma transformação linearizante da função \(K(r)\), proposta para estabilizar a variância e facilitar a interpretação visual.
\[L(r)=\sqrt{\frac{K(r)}{\pi}}\]
Por que transformar?
- Sob aleatoriedade (Poisson), \(K(r) = \pi r^2\). Ao aplicar a transformação:
\[L_{pois}(r) = \sqrt{\frac{\pi r^2}{\pi}} = r\]
Regular: \(L(r) < r\) (Abaixo da diagonal).
Aleatório: \(L(r) \approx r\) (Sobre a diagonal).
Agrupado: \(L(r) > r\) (Acima da diagonal).
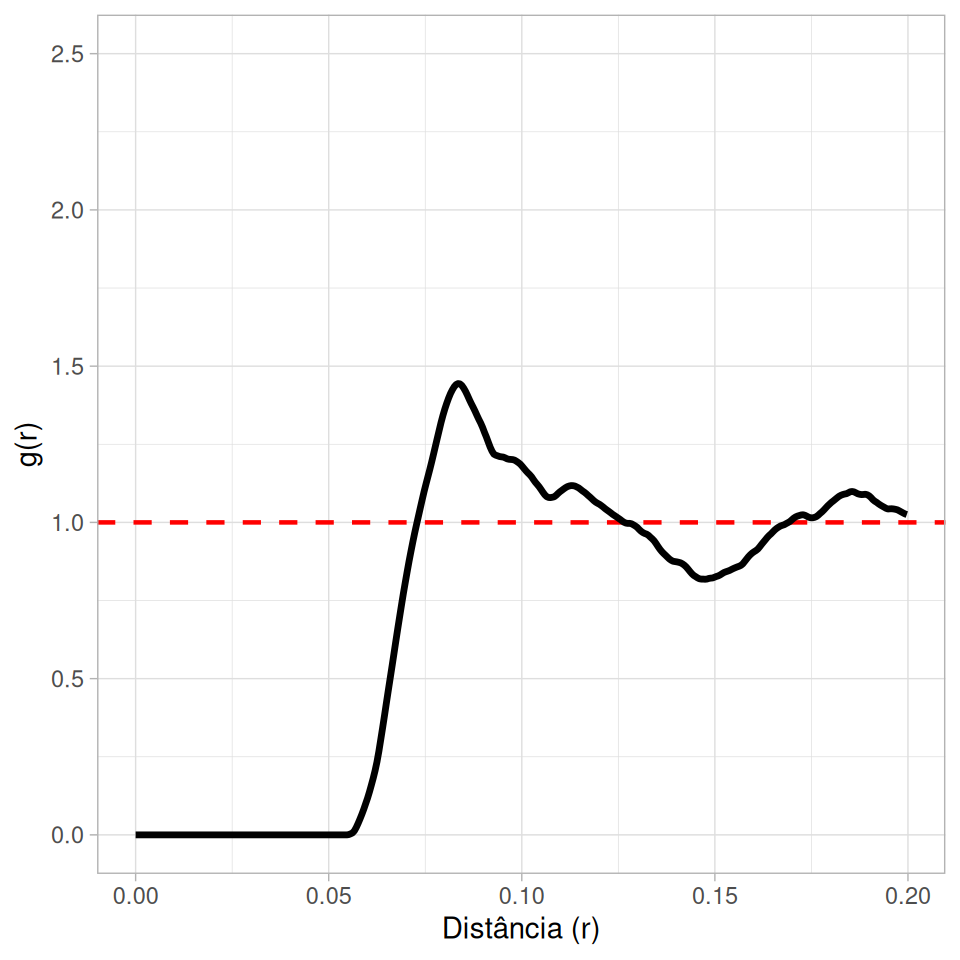
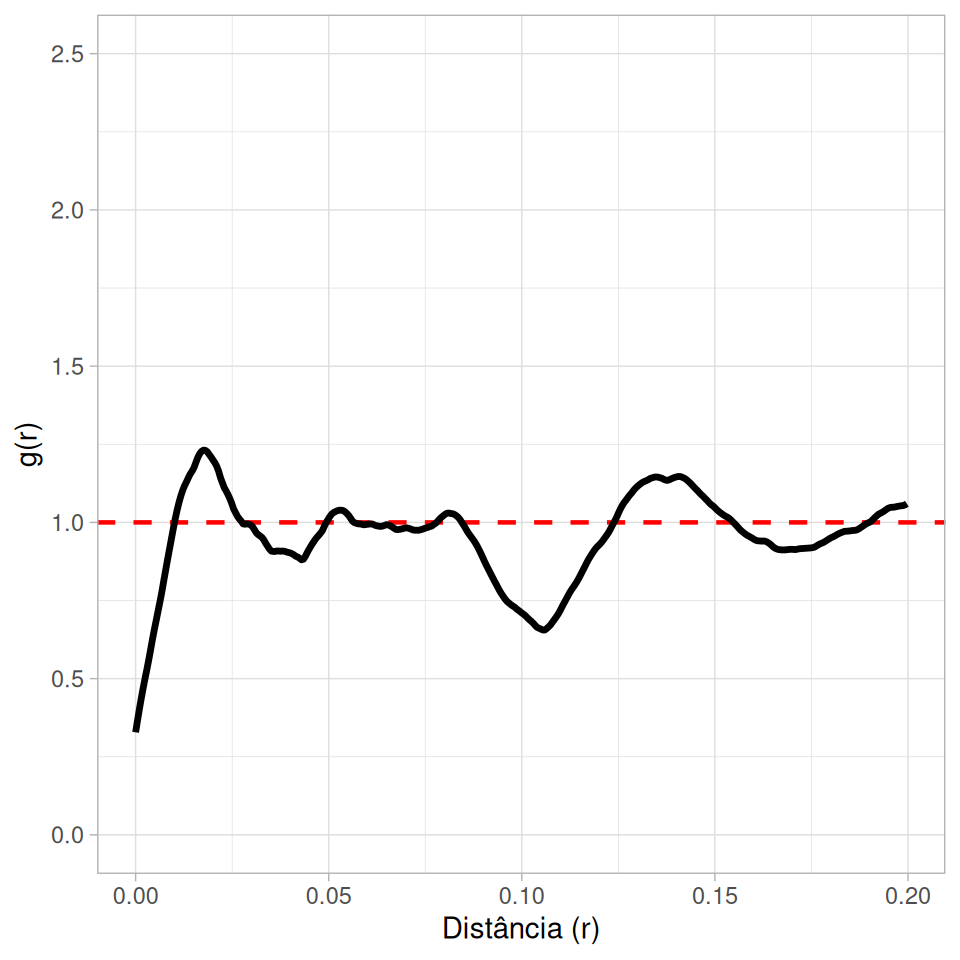
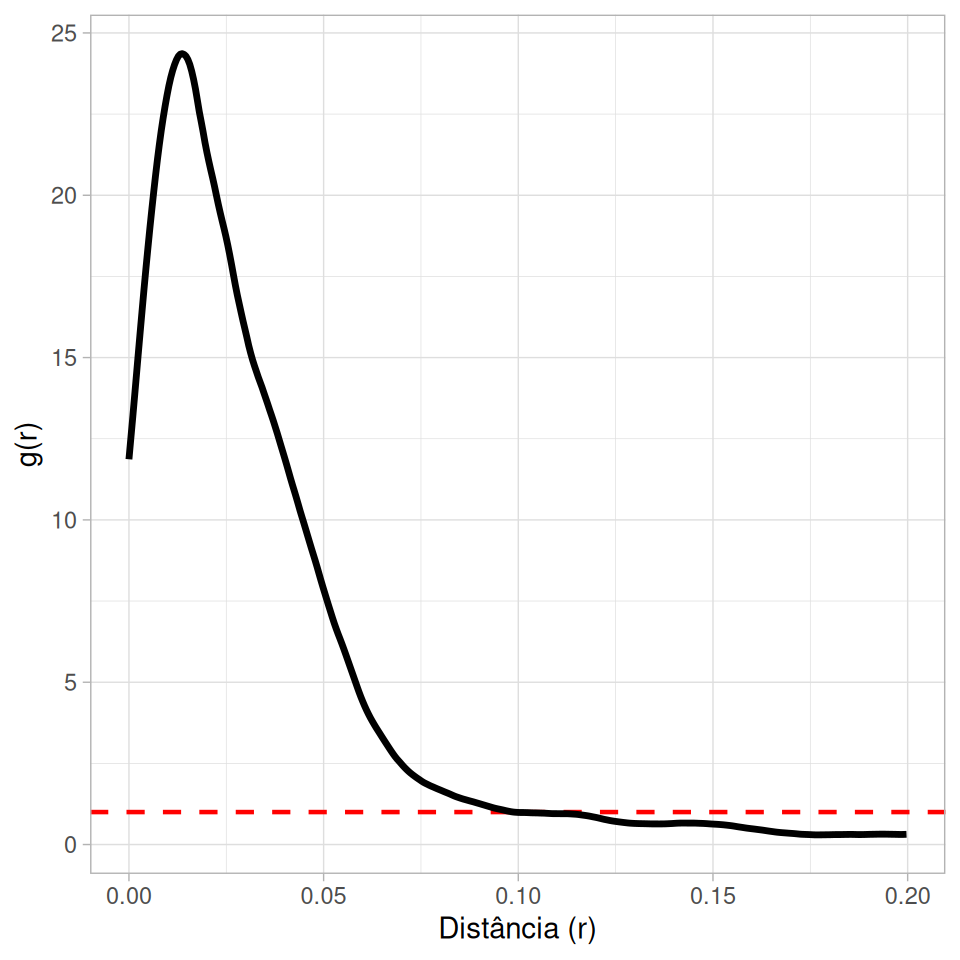
A função \(g(r)\) (Pair Correlation Function - PCF) não é cumulativa. Ela descreve a probabilidade de encontrar um par de pontos separados por uma distância exata \(r\).
\[g(r) = \frac{K'(r)}{2\pi r}\]
É análoga a uma função densidade de probabilidade.
\(g(r) = 1\): Aleatoriedade.
\(g(r) > 1\): Agrupamento na distância \(r\).
\(g(r) < 1\): Inibição na distância \(r\).
Muito útil para detectar escalas específicas de interação (ex: inibição a curta distância mas atração a média distância).
Visualização: Diagnóstico com Envelopes
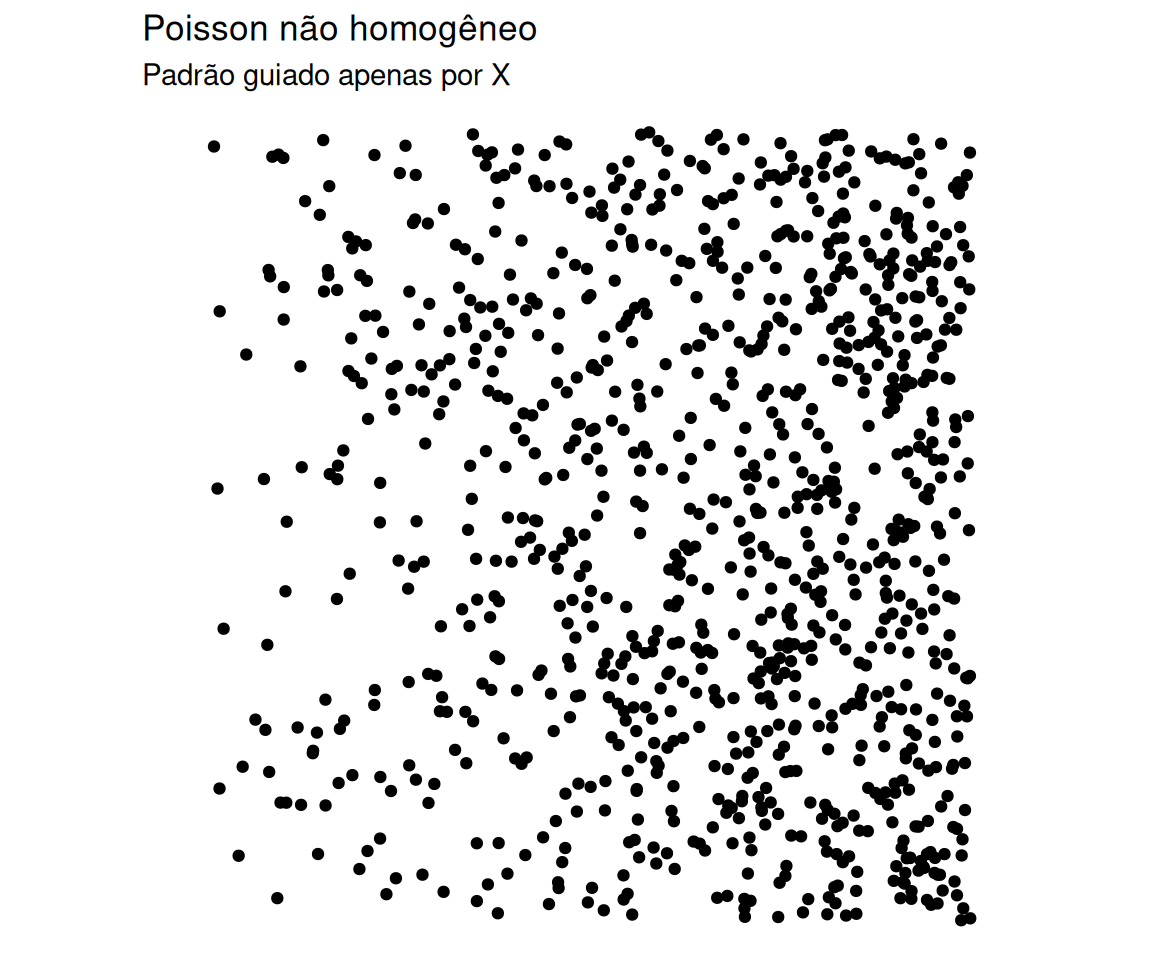
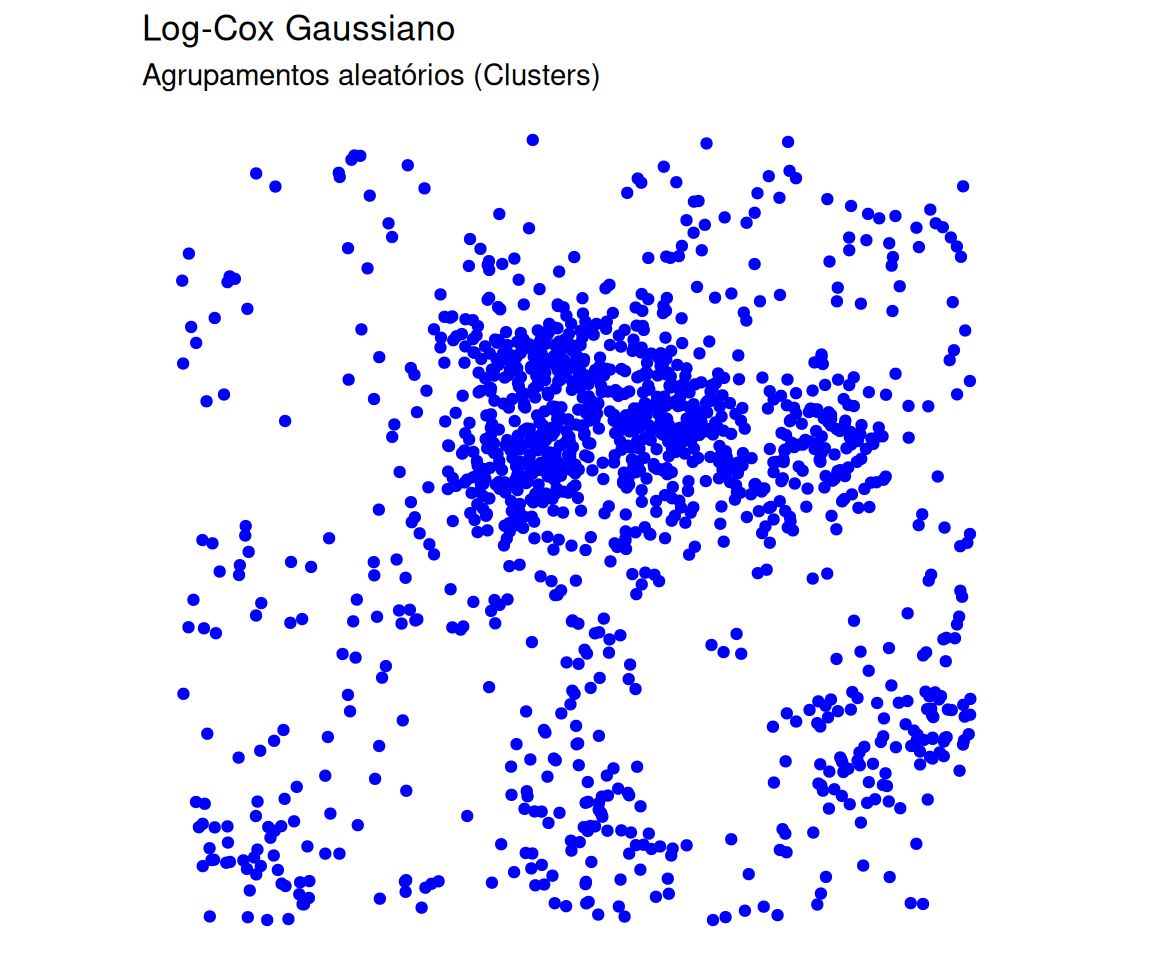
Visualização: Poisson vs Cox
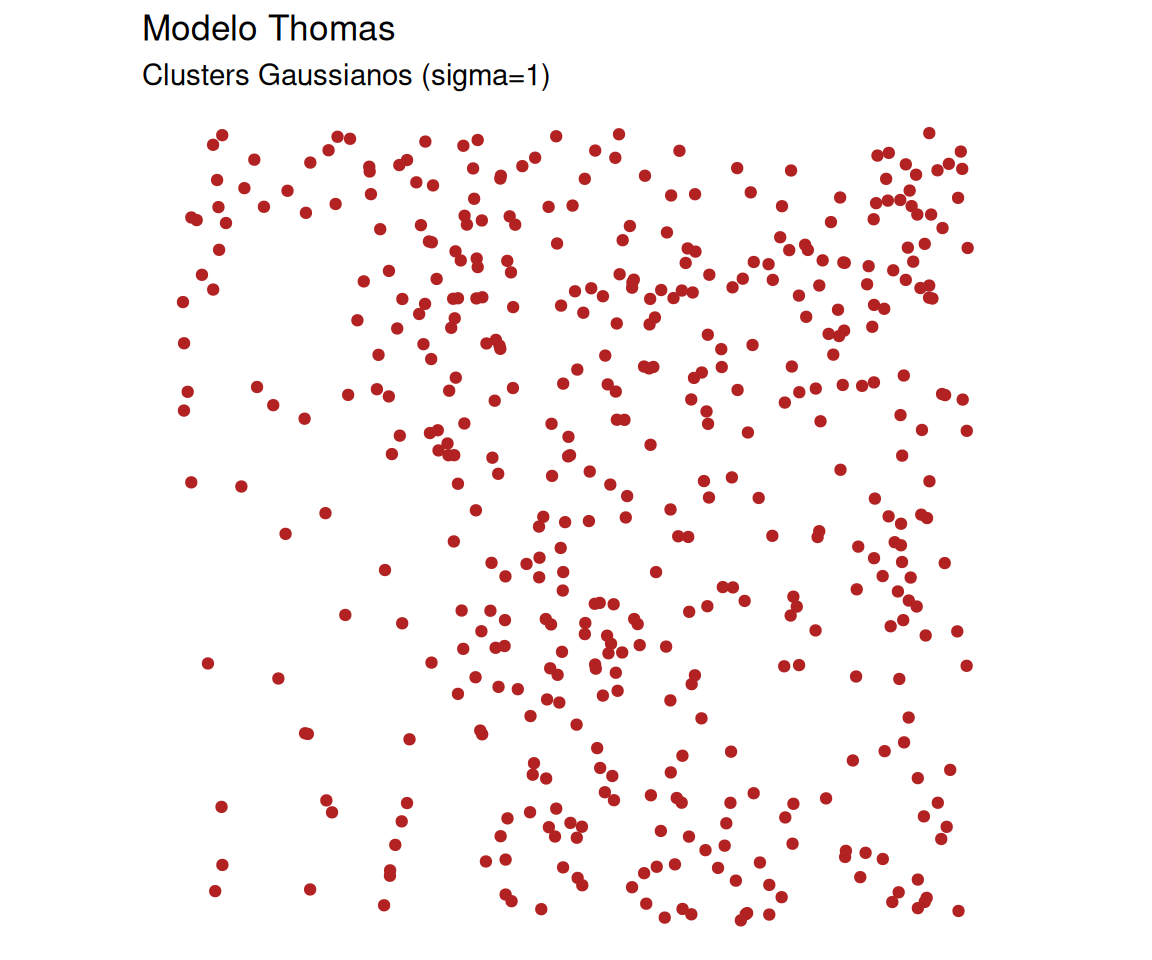
Visualização: Matérn vs Thomas

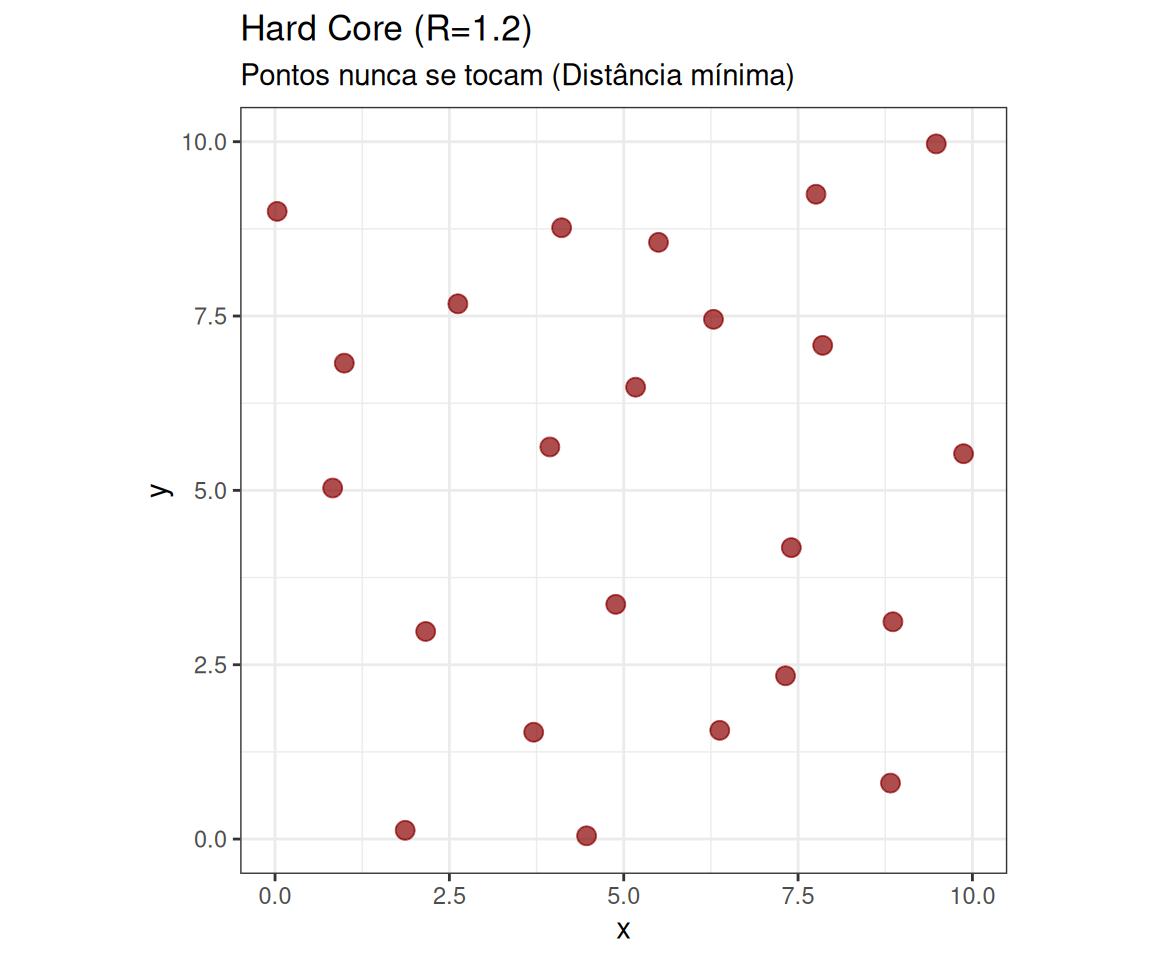
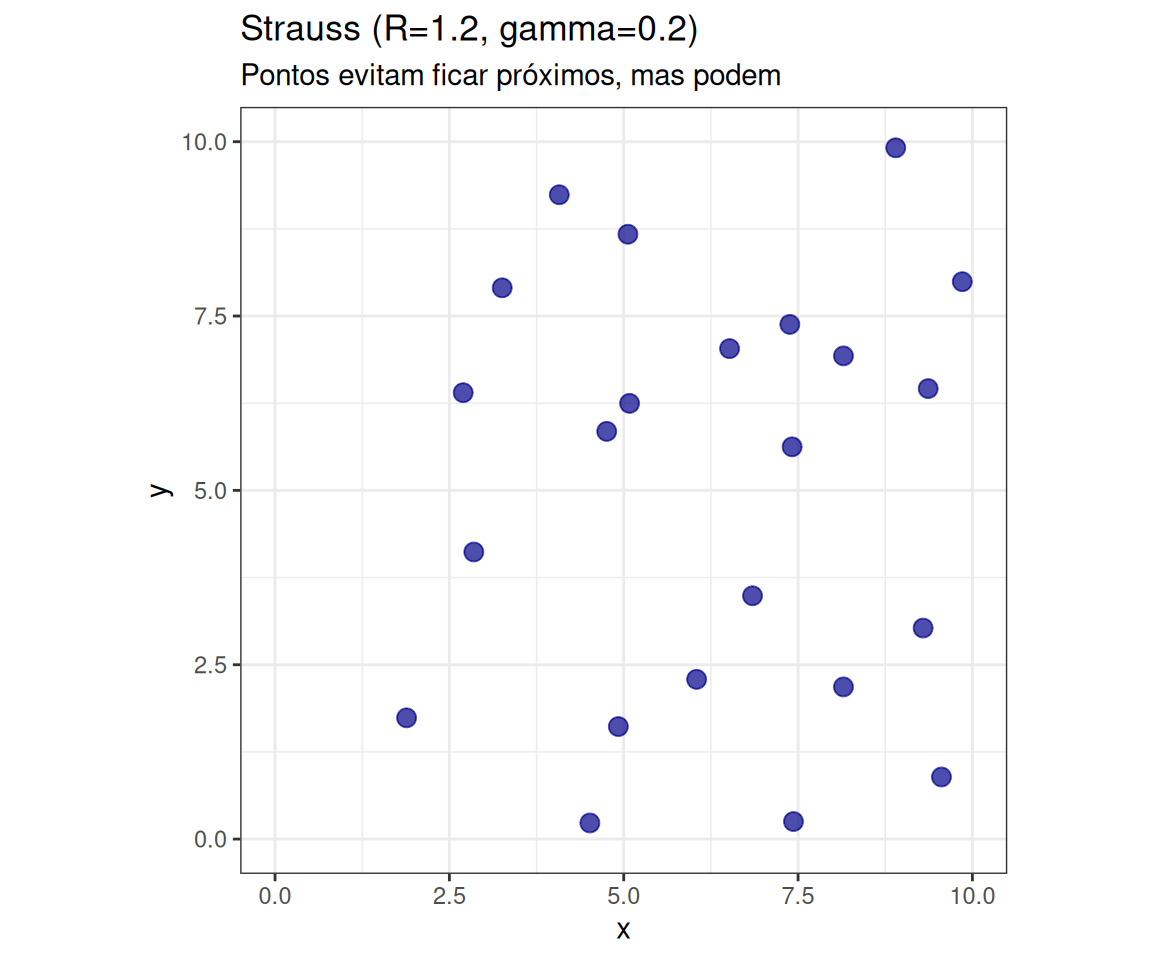
Visualização: Hard Core vs Strauss
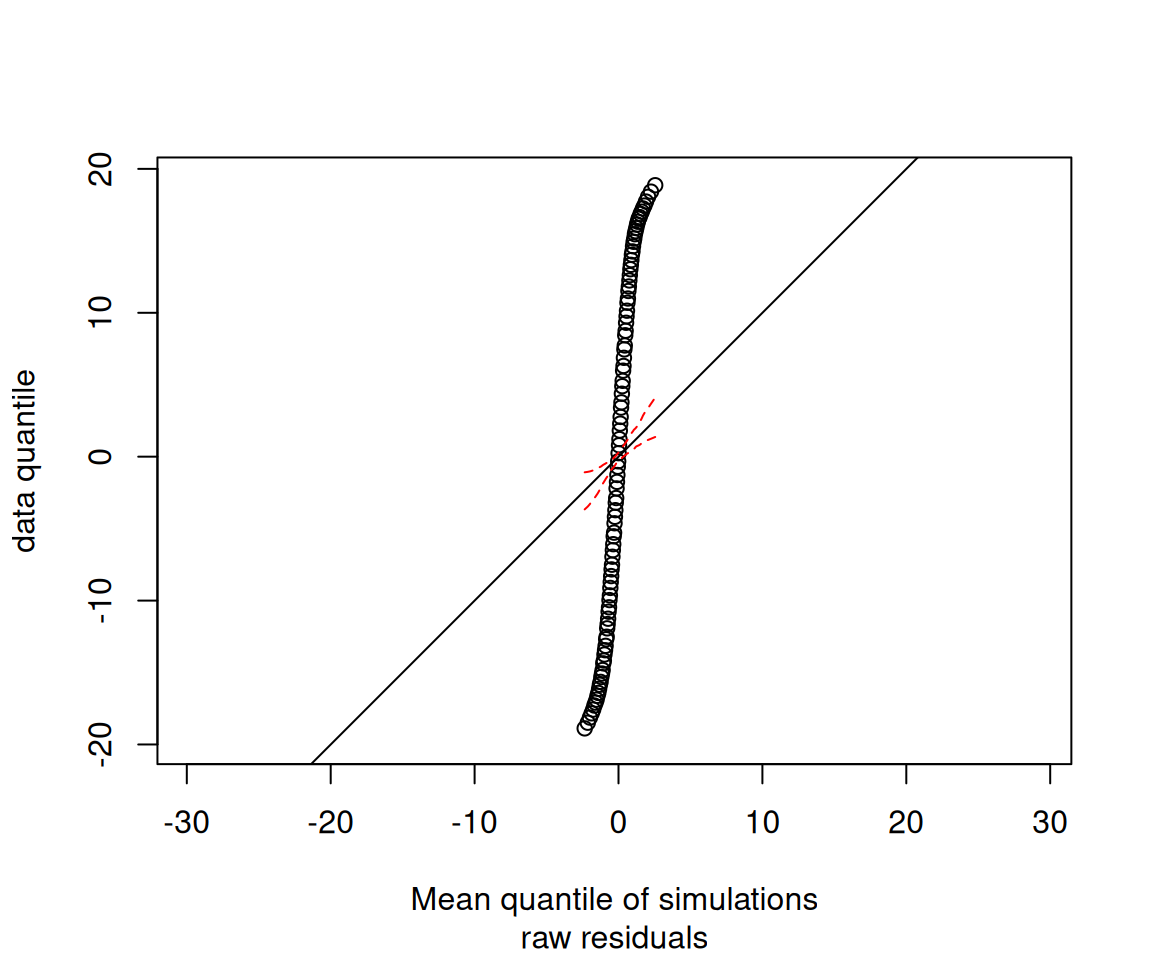
Diagnóstico Visual de Resíduos
Extracting model information...Evaluating trend...done.
Simulating 100 realisations... 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20,
21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40,
41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60,
61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80,
81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99,
100.
Diagnostic info:
simulated patterns contained an average of 2509.92 points.
Calculating quantiles...averaging.....Done.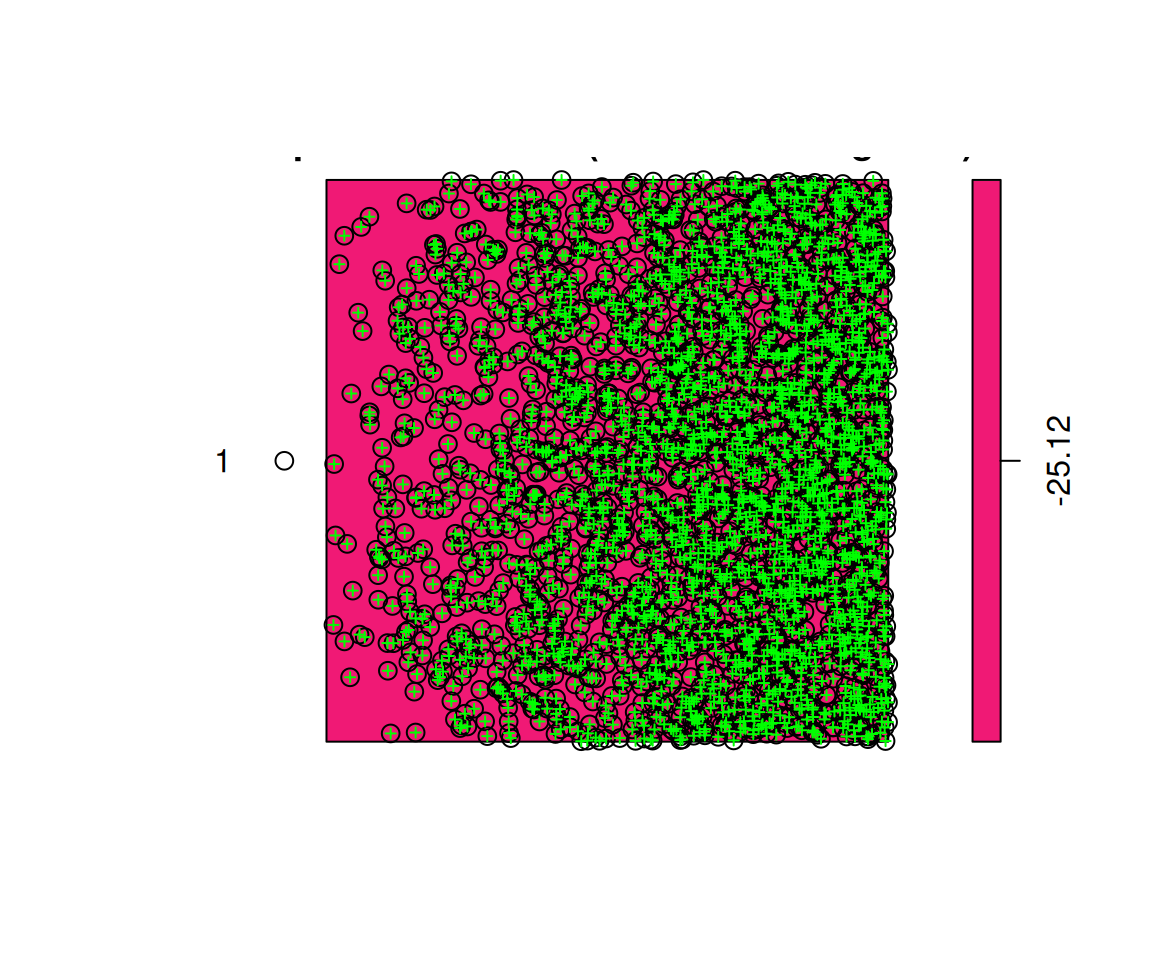
Dica
Se o modelo for bom, o mapa de resíduos deve parecer “ruído branco” (sem padrão óbvio) e o Q-Q plot deve seguir a reta.