A análise de dados de área (ou lattice data) lida com processos estocásticos cujo domínio espacial é fixo, discreto e contável. Denotamos esse domínio por \(D^L\). Enquanto na geoestatística (?@sec-geoest) o suporte é contínuo, permitindo observações em qualquer localização \(\mathbf{s} \in D^G\), nos dados de área as observações estão ancoradas em unidades espaciais predefinidas e não sobrepostas, como regiões administrativas, células de uma grelha ou zonas censitárias.
Seja \(\{D_i\}_{i=1}^{n}\) uma coleção finita de \(n\) unidades espaciais (por exemplo, municípios, distritos ou pixels). Os dados de área são definidos como uma coleção de variáveis aleatórias indexadas por essas unidades: \(\{Y(\mathbf{s}_i): \mathbf{s}_i \in D^L\}\), onde \(D^L = \{\mathbf{s}_1, \dots, \mathbf{s}_n\}\) é um subconjunto fixo e contável do espaço Euclidiano \(\mathbb{R}^d\)[@cressie2022spatial]. A incerteza reside exclusivamente no valor do atributo \(Y(\mathbf{s}_i)\), e não na localização \(\mathbf{s}_i\) (que é fixa e conhecida), diferenciando-se dos processos pontuais (?@sec-proc_pont). Para as \(n\) regiões, o vetor de observações é \(\mathbf{y} = (y_1, \dots, y_n)^\top\), onde \(y_i \equiv y(\mathbf{s}_i)\).
Conforme destacado por @besag1974spatial, a dependência espacial neste contexto não é necessariamente governada por uma métrica de distância Euclidiana contínua, como na geoestatística (?@sec-geoest), mas sim pela topologia ou estrutura de vizinhança definida entre as unidades discretas \(\{D_i\}\).
A questão inferencial central também se desloca. Em vez de interpolar (prever) um valor em um local não observado \(s_0\) (krigagem, ?@sec-geoest), o foco passa a ser compreender e quantificar como o valor observado na unidade \(D_i\) é influenciado pelos valores nas unidades vizinhas \(\{D_j\}\) (interação espacial). Por simplicidade, as unidades são frequentemente denotadas apenas por seus índices \(i\) e \(j\).
Uma característica fundamental dos dados de área é a agregação. O valor observado \(y_i\) na unidade \(i\) é tipicamente o resultado da integração (ou média) de um processo contínuo latente \(Y(\mathbf{s})\) sobre a área geográfica \(A_i\) daquela unidade. Formalmente, se \(Y(\mathbf{s})\) representa, por exemplo, densidade ou intensidade, então:
\[
y_i = \int_{A_i} Y(\mathbf{s}) \, d\mathbf{s} \: \text{(para contagens ou volumes)}, \: \text{ ou }
y_i = \frac{1}{|A_i|} \int_{A_i} Y(\mathbf{s}) \, d\mathbf{s} \: \text{(para médias ou intensidades)},
\] onde \(|A_i|\) é a área da região \(i\).
Esta natureza agregada implica que a inferência estatística é condicional à partição específica do espaço (\(A_1 \cup \dots \cup A_n\)). Alterar essa partição (escala ou limites) pode alterar as propriedades estatísticas (média, variância, correlação) dos dados. Este fenômeno é conhecido como o Problema da Unidade de Área Modificável (MAUP) [@openshaw1984modifiable]. Estatisticamente, a agregação introduz uma heterocedasticidade intrínseca: unidades com áreas \(|A_i|\) ou populações-base diferentes terão variâncias de amostragem distintas, um aspecto que deve ser cuidadosamente considerado na modelagem da matriz de covariância \(\mathbf{\Sigma}\).
1.1 Representação espacial e construção de estruturas de vizinhança
A representação dos dados de área pode se dar em estruturas regulares (grelhas ou grids) ou irregulares (divisões políticas ou administrativas, ?@sec-grid). Grids regulares são comuns em análise de imagens, sensoriamento remoto e dados climáticos, onde cada célula (pixel) tem uma forma e tamanho constantes, facilitando a computação e a definição de vizinhança. Polígonos irregulares, que representam entidades como municípios ou distritos, são comuns em ciências sociais e saúde pública. A heterogeneidade no tamanho e forma dessas regiões introduz desafios adicionais, como a já mencionada variância desigual e a definição não trivial de proximidade [@cressie1989spatial].
Para modelar a dependência espacial, é fundamental definir formalmente como as unidades se relacionam. Essa relação baseia-se na matriz de pesos espaciais ou matriz de vizinhança:
onde cada elemento \(w_{ij}\) quantifica a conexão espacial entre a unidade \(j\) e unidade \(i\). Por convenção, assume-se que \(w_{ii} = 0\), impedindo que uma unidade seja vizinha de si [@anselin2001spatial]. Note ainda que é comum descrever a vizinhança entre unidades \(i\) e \(j\) se existe, simplesmente \(i\sim j\), para referir que \(w_{ij} \neq 0\)[@BesagKooperberg1995].
A construção de \(\mathbf{W}\) envolve duas etapas conceituais distintas: 1) a definição da topologia ou critério de vizinhança (quem é vizinho de quem); e 2) a ponderação (a intensidade atribuída a cada conexão). Enquanto a primeira é predominantemente geométrica, a segunda frequentemente envolve uma operação de normalização, crucial para a estabilidade numérica e interpretabilidade dos modelos.
Diferente das séries temporais, onde a dependência é unidirecional e sequencial (o passado influencia o futuro), nos dados de área a dependência é multidirecional e simultânea. A unidade \(i\) influencia \(j\), que influencia \(k\), que pode, por sua vez, influenciar \(i\) novamente através de outras conexões, criando um sistema de feedback espacial.
1.1.1 Critérios de Vizinhança
A definição operacional de proximidade ou vizinhança é um passo fundamental e teórico. @anselin2002under discutem os critérios mais comuns:
Contiguidade (Adjacência): Baseia-se no compartilhamento de fronteiras (ver ?@sec-dependencia).
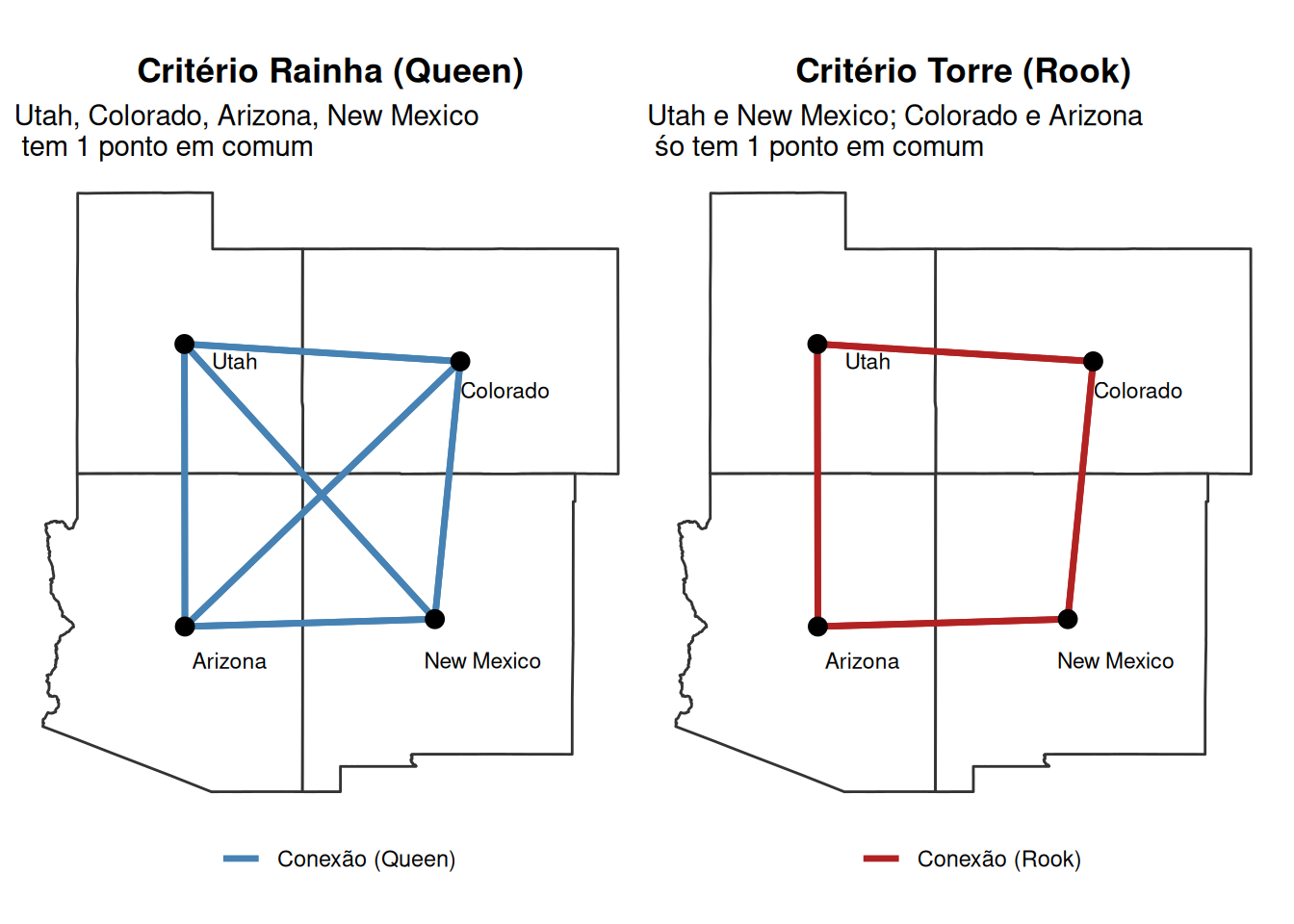
Torre (Rook): As unidades \(i\) e \(j\) são vizinhas se compartilham um segmento de fronteira (aresta). Formalmente, \(\text{dim}(\partial A_i \cap \partial A_j) = 1\).
Rainha (Queen): As unidades \(i\) e \(j\) são vizinhas se compartilham qualquer ponto de fronteira, seja um vértice ou uma aresta. Formalmente, \(A_i \cap \partial A_j \neq \emptyset\). Este critério é mais abrangente e é particularmente útil para malhas irregulares, pois evita que unidades que se tocam apenas em um canto (como municípios separados por um rio que se encontram em uma confluência) sejam consideradas desconectadas. Por exemplo, ao estudar a propagação de um fenômeno social entre municípios, dois que são separados por um rio mas cujos centros urbanos estão próximos na confluência podem ter intensa interação. Usar o critério Rook os trataria como isolados, enquanto o critério Queen capturaria essa potencial conexão, resultando em uma matriz de conectividade mais robusta e evitando subestimar a dependência espacial.
Code
if (!require("pacman")) install.packages("pacman")pacman::p_load(sf, spdep, ggplot2, patchwork, dplyr, geodata)# Baixar dados dos EUA (Nível 1 = Estados)usa_sf <-tryCatch({# Tenta baixar direto usa_vect <- geodata::gadm(country ="USA", level =1, path =tempdir(), version="latest") sf::st_as_sf(usa_vect)}, error =function(e) {message("Erro ao baixar dados, gadm está com problemas, baixa direto no site: https://gadm.org/maps.html.")})# FILTRAR apenas Utah, Colorado, Arizona, New Mexicofour_corners <- usa_sf %>%filter(NAME_1 %in%c("Utah", "Colorado", "Arizona", "New Mexico")) %>%st_make_valid()# Extrair centroides para o grafocoords <-suppressWarnings(st_coordinates(st_centroid(four_corners))) #suppressWarnings() era para tirarcoords_df <-as.data.frame(coords)# Queen (Rainha)#identificar quais polígonos são vizinhos e constroir lista de vizinhosnb_queen <-poly2nb(four_corners, queen =TRUE)#criar segmentos de reta ligando os centroides das áreas vizinhasnb_lines_queen <-nb2lines(nb_queen, coords = coords, as_sf =TRUE)st_crs(nb_lines_queen) <-st_crs(four_corners) # atribuir a nb_lines_queen CRS igual do four_corners# Rook (Torre)nb_rook <-poly2nb(four_corners, queen =FALSE)nb_lines_rook <-nb2lines(nb_rook, coords = coords, as_sf =TRUE)st_crs(nb_lines_rook) <-st_crs(four_corners)theme_comp <-theme_void() +theme(plot.title =element_text(hjust =0.5, face ="bold"),legend.position ="bottom")+theme(legedn.title=element_text(hjust=0.5))# Queenp_queen <-ggplot() +geom_sf(data = four_corners, fill ="white", color ="gray20", linewidth =0.5) +geom_sf(data = nb_lines_queen, aes(color ="Conexão (Queen)"), linewidth =1.2) +geom_point(data = coords_df, aes(X, Y), size =3) +geom_sf_text(data = four_corners, aes(label = NAME_1), size =3, nudge_y =-0.5, nudge_x=1) +scale_color_manual(values ="steelblue", name ="") +labs(title ="Critério Rainha (Queen)", subtitle ="Utah, Colorado, Arizona, New Mexico\n tem 1 ponto em comum") + theme_comp# Rookp_rook <-ggplot() +geom_sf(data = four_corners, fill ="white", color ="gray20", linewidth =0.5) +geom_sf(data = nb_lines_rook, aes(color ="Conexão (Rook)"), linewidth =1.2) +geom_point(data = coords_df, aes(X, Y), size =3) +geom_sf_text(data = four_corners, aes(label = NAME_1), size =3, nudge_y =-0.5, nudge_x=1) +scale_color_manual(values ="firebrick", name ="") +labs(title ="Critério Torre (Rook)", subtitle ="Utah e New Mexico; Colorado e Arizona\n śo tem 1 ponto em comum") + theme_compp_queen + p_rook
Figure 1: Comparação das Estruturas de Vizinhança Queen (Rainha) e Rook (Torre) entre Utah, Colorado, Arizona, New Mexico (Estados Unidos)
Baseado em distância:
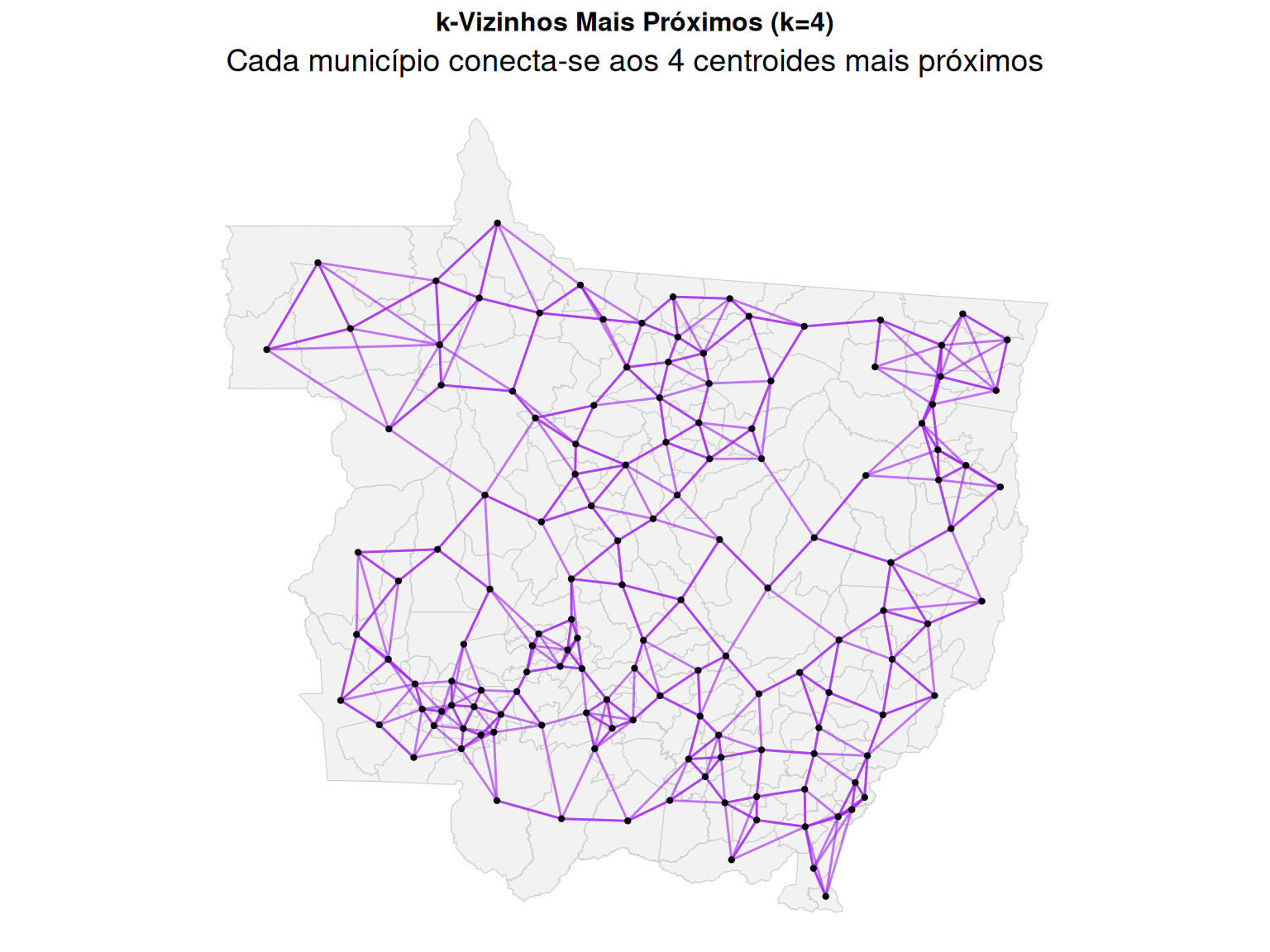
\(k\)-Vizinhos mais próximos (\(k\)-NN): Define como vizinhos de \(i\), as \(k\) unidades cujos centroides (ou outro ponto representativo) estão mais próximos, segundo a distância euclidiana. Garante que cada unidade tenha exatamente \(k\) vizinhos, criando uma matriz esparsa e evitando ilhas de desconexão [@anselin2001spatial].
Code
if (!require("pacman")) install.packages("pacman")pacman::p_load(sf, spdep, ggplot2, geobr, dplyr, patchwork)# Baixar mapa municipal de Mato Grosso (MT)mt_sf <-read_municipality(code_muni ="MT", year =2020, showProgress =FALSE)coords_mt <-suppressWarnings(st_coordinates(st_centroid(mt_sf)))theme_map <-theme_void() +theme(plot.title =element_text(hjust =0.5, face ="bold", size =12),plot.subtitle =element_text(hjust =0.5, size =14))
Code
# Calcular os k=4 vizinhos mais próximosk <-4knn_nb <-knearneigh(coords_mt, k = k)nb_knn <-knn2nb(knn_nb)# Converter para linhas espaciais para plotarlines_knn <-nb2lines(nb_knn, coords = coords_mt, as_sf =TRUE)st_crs(lines_knn) <-st_crs(mt_sf)# Plotggplot() +geom_sf(data = mt_sf, fill ="gray95", color ="gray80") +geom_sf(data = lines_knn, color ="purple", linewidth =0.5, alpha =0.6) +geom_point(data =as.data.frame(coords_mt), aes(X, Y), size =0.8) +labs(title =paste0("k-Vizinhos Mais Próximos (k=", k, ")"),subtitle ="Cada município conecta-se aos 4 centroides mais próximos") + theme_map
Figure 2: Vizinhança k-NN (k=4) em Mato Grosso.
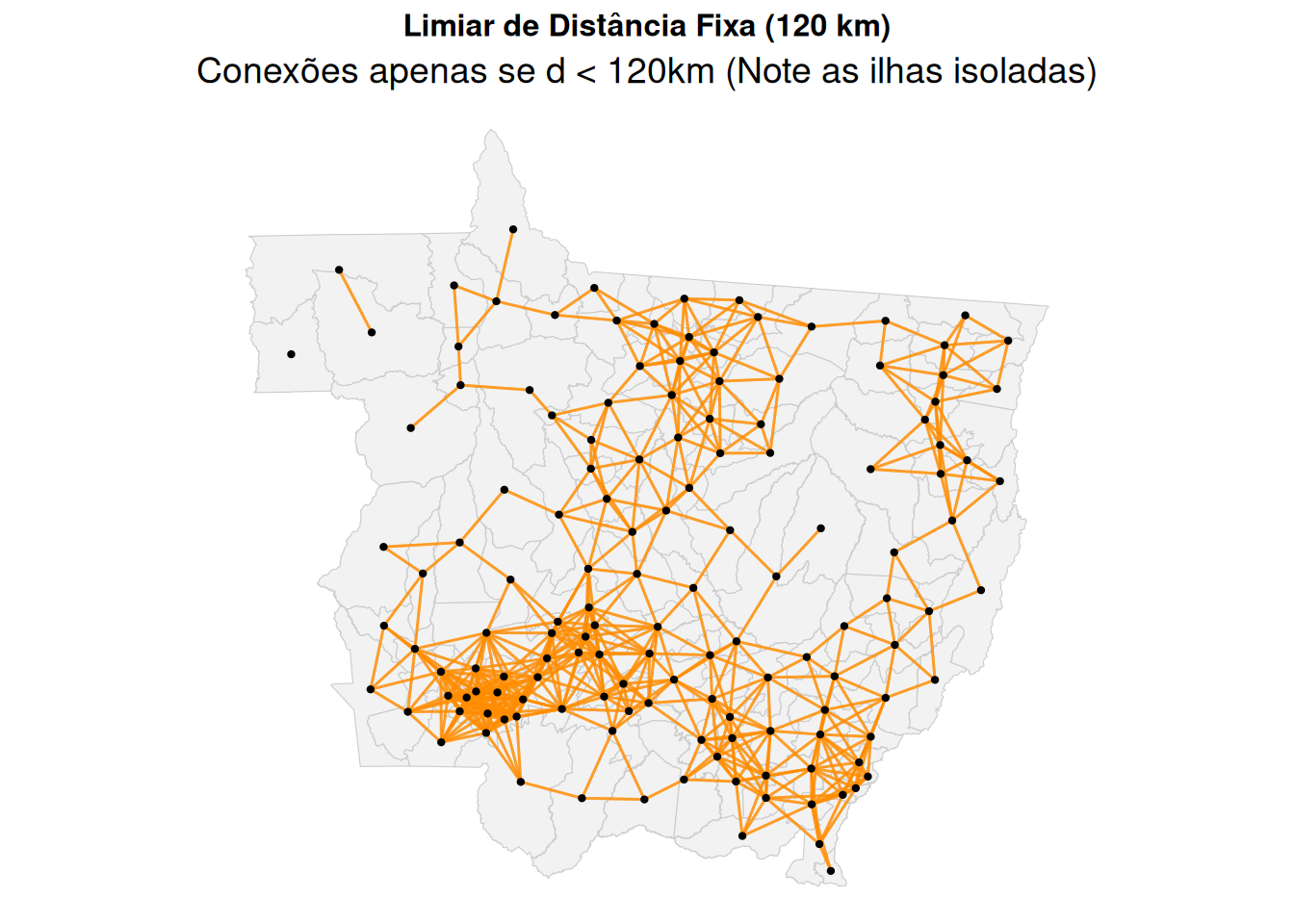
Limiar de distância (Threshold): \(w_{ij} = 1\) se \(d_{ij} \le d_{\max}\), e \(0\) caso contrário, onde \(d_{ij}\) é a distância entre centroides.
Code
# Para precisão, vamos projetar para SIRGAS 2000 / Brazil Polyconic (EPSG 5880) para usar metros.mt_proj <-st_transform(mt_sf, 5880)coords_proj <-st_coordinates(st_centroid(mt_proj))# Definir raio de 120 km (120000 metros)dist_nb <-dnearneigh(coords_proj, 0, 120000)# Converter para linhaslines_dist <-nb2lines(dist_nb, coords = coords_proj, as_sf =TRUE)st_crs(lines_dist) <-st_crs(mt_proj)ggplot() +geom_sf(data = mt_proj, fill ="gray95", color ="gray80") +geom_sf(data = lines_dist, color ="darkorange", linewidth =0.5, alpha =0.6) +geom_point(data =as.data.frame(coords_proj), aes(X, Y), size =0.8) +labs(title ="Limiar de Distância Fixa (120 km)",subtitle ="Conexões apenas se d < 120km (Note as ilhas isoladas)") + theme_map
Figure 3: Vizinhança por Limiar de Distância (120km).
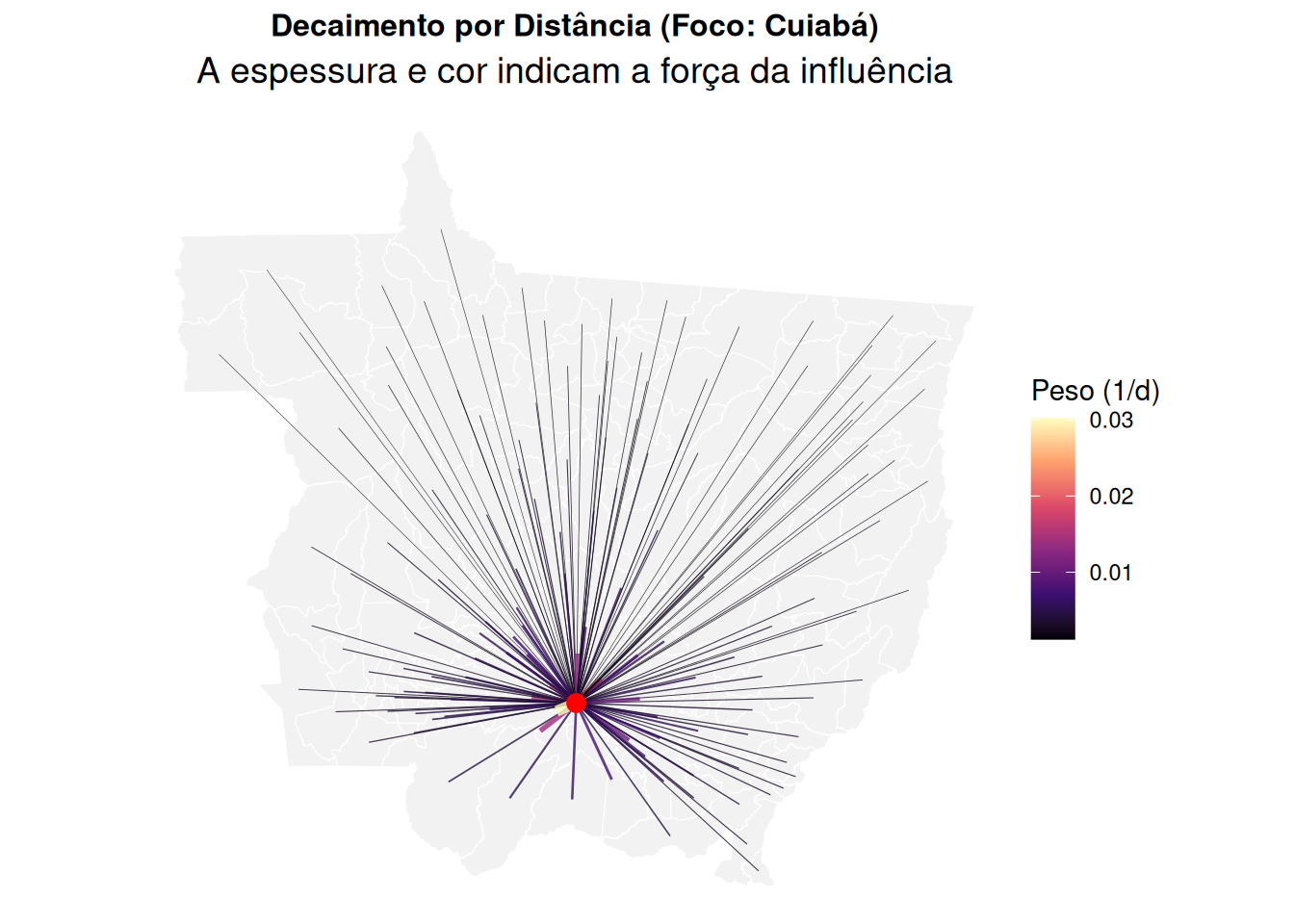
Decaimento por distância: Atribui pesos que decrescem com a distância, ex: \(w_{ij} = d_{ij}^{-\alpha}\) ou \(w_{ij} = \exp(-\beta d_{ij})\). Atribui maior influência a unidades mais próximas.
Code
# Identificar Cuiabáid_cuiaba <-which(mt_sf$name_muni =="Cuiabá")# Calcular distâncias de Cuiabá para TODOS os outros municípiosnb_all <-dnearneigh(coords_proj, 0, 900000) # Raio grande para pegar quase todo estadodists <-nbdists(nb_all, coords_proj)# Calcular Pesos (Inverso da Distância: 1/d)weights_list <-lapply(dists, function(x) 1/(x/1000)) # /1000 para km# Preparar dados apenas para Cuiabá para visualizaçãovizinhos_cuiaba <- nb_all[[id_cuiaba]]pesos_cuiaba <- weights_list[[id_cuiaba]]# Criar linhas saindo de Cuiabálines_cuiaba <-vector("list", length(vizinhos_cuiaba))for(i inseq_along(vizinhos_cuiaba)) { dest_idx <- vizinhos_cuiaba[i] lines_cuiaba[[i]] <-st_linestring(rbind(coords_proj[id_cuiaba,], coords_proj[dest_idx,]))}sf_decay <-st_sf(peso = pesos_cuiaba, geometry =st_sfc(lines_cuiaba), crs =5880)ggplot() +geom_sf(data = mt_proj, fill ="gray95", color ="white") +geom_sf(data = sf_decay, aes(color = peso, linewidth = peso), alpha =0.8) +geom_point(aes(x=coords_proj[id_cuiaba,1], y=coords_proj[id_cuiaba,2]), color="red", size=3) +scale_color_viridis_c(option ="magma", name ="Peso (1/d)") +scale_linewidth(range =c(0.1, 2), guide ="none") +labs(title ="Decaimento por Distância (Foco: Cuiabá)",subtitle ="A espessura e cor indicam a força da influência") + theme_map
Figure 4: Decaimento por Distância Inversa a partir de Cuiabá.
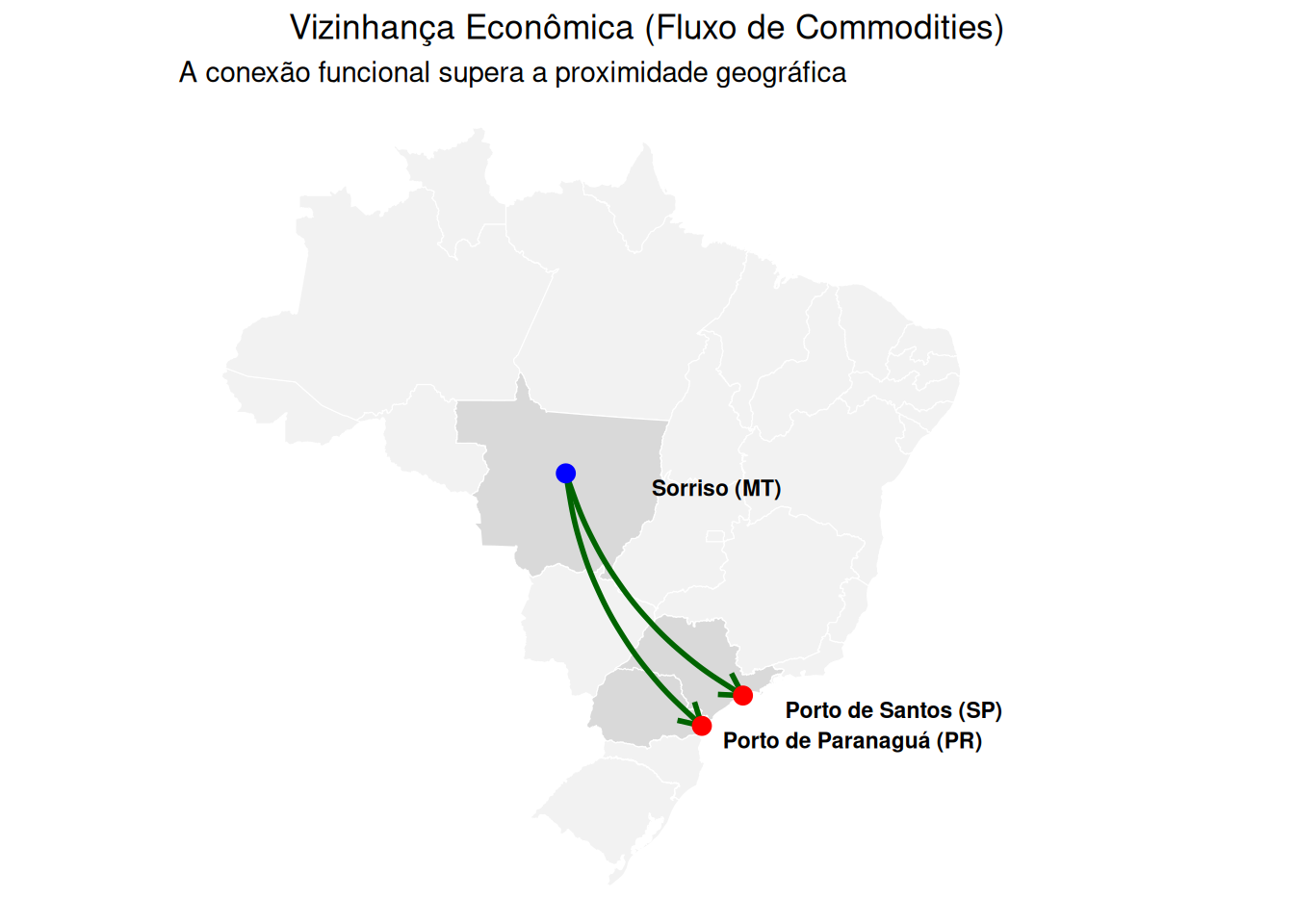
Vizinhança econômica ou social:@harris2011search argumentam que a contiguidade física pode ser insuficiente ou enganosa em muitos contextos. Em estudos regionais, a conexão funcional frequentemente supera a proximidade geográfica. Por exemplo, no Brasil, um município do agronegócio no Centro-Oeste (ex.: Sorriso/MT) pode estar economicamente mais conectado aos portos de Santos (SP) ou Paranaguá (PR) por onde escoa sua produção do que aos municípios geograficamente adjacentes em seu próprio estado que possuem economias de base diferente. Da mesma forma, para análises de mercado de trabalho ou inovação, a região metropolitana de São Paulo pode ter uma interação mais intensa com polos tecnológicos como Campinas ou até com outros centros globais do que com municípios vizinhos de baixa intensidade tecnológica. Matrizes baseadas em fluxos (comerciais, migratórios, de passageiros), similaridade socioeconômica (PIB per capita, estrutura produtiva) ou redes de infraestrutura (rodovias, linhas de voo) são, portanto, alternativas teóricas mais ricas e adequadas a fenômenos específicos.
Code
# Carregar mapa do Brasil (Estados)br_states <-read_state(year =2020, showProgress =FALSE)# Coordenadas aproximadas das cidades de interesse# (Sorriso-MT, Santos-SP, Paranaguá-PR)cidades_df <-data.frame(cidade =c("Sorriso (MT)", "Porto de Santos (SP)", "Porto de Paranaguá (PR)"),lat =c(-12.5427, -23.9618, -25.5205),lon =c(-55.7211, -46.3322, -48.5095),tipo =c("Origem", "Destino", "Destino"))cidades_sf <-st_as_sf(cidades_df, coords =c("lon", "lat"), crs =4326)# Criar conexões (Arcos)sorriso_coords <-subset(cidades_df, cidade =="Sorriso (MT)")destinos <-subset(cidades_df, tipo =="Destino")conexoes <-lapply(1:nrow(destinos), function(i) {st_linestring(rbind(c(sorriso_coords$lon, sorriso_coords$lat),c(destinos$lon[i], destinos$lat[i]) ))})conexoes_sf <-st_sf(geometry =st_sfc(conexoes), crs =4326)# Plotggplot() +geom_sf(data = br_states, fill ="gray95", color ="white") +# Destacar Estados envolvidosgeom_sf(data =subset(br_states, abbrev_state %in%c("MT", "SP", "PR")), fill ="gray85", color ="white") +# Linhas de Fluxo (Curvas para indicar movimento/distância)geom_curve(data =data.frame(x1 = sorriso_coords$lon, y1 = sorriso_coords$lat,x2 = destinos$lon, y2 = destinos$lat),aes(x = x1, y = y1, xend = x2, yend = y2),color ="darkgreen", size =1, curvature =0.2, arrow =arrow(length =unit(0.03, "npc"))) +geom_point(data = cidades_df, aes(x = lon, y = lat, color = tipo), size =3) +scale_color_manual(values =c("red", "blue")) +geom_text(data = cidades_df, aes(x = lon, y = lat, label = cidade), vjust =-1, fontface ="bold", size =3, nudge_x=8, nudge_y=-2) +#usei nudge pra mover legendalabs(title ="Vizinhança Econômica (Fluxo de Commodities)",subtitle ="A conexão funcional supera a proximidade geográfica") +theme_void() +theme(legend.position ="none", plot.title =element_text(hjust =0.5))
Figure 5: Vizinhança Econômica/Funcional: O Agronegócio conectando Sorriso-MT aos Portos.
1.1.2 Matriz de pesos espaciais (\(\mathbf{W}\)) e normalização
A matriz binária de adjacência \(\mathbf{W} = [w_{ij}]_{n \times n}\) (com elementos 0 ou 1) é frequentemente transformada em uma matriz de pesos para refletir a intensidade relativa das conexões. A escolha dos pesos é exógena ao modelo (ou seja, deve ser definida a priori com base em teoria ou no desenho do estudo) e tem implicações na estimação e interpretação [@kelejian2017spatial].
A necessidade de normalização surge por razões estatísticas e de interpretação. Em modelos autorregressivos espaciais (por serem vistos mais adiante), o parâmetro de dependência \(\rho\) deve geralmente estar em um intervalo que garanta a invertibilidade da matriz \(( \mathbf{I} - \rho \mathbf{W} )\). Se \(\mathbf{W}\) não for normalizada, os autovalores podem ser muito grandes ou desiguais, restringindo o espaço paramétrico válido para \(\rho\) a um intervalo desconhecido e difícil de interpretar. A normalização estabiliza o comportamento numérico do modelo.
Normalização por linha (row-standardization)
É a abordagem mais comum. Cada peso é dividido pela soma da linha correspondente:
O resultado é que cada linha de \(\mathbf{W}^{r}\) soma 1. A operação \(\mathbf{W}^{r}\mathbf{y}\) gera uma defasagem espacial (spatial lag) que é interpretado como a média ponderada dos valores dos vizinhos de cada unidade. Esta normalização equaliza a capacidade de receber influência de cada unidade, independentemente do seu número de vizinhos. Garante também que o maior autovalor de \(\mathbf{W}^{r}\) seja 1, facilitando a definição do intervalo \((-1, 1)\) para \(\rho\) em modelos SAR.
Exemplo: Considere uma matriz de vizinhança/adjacência binária \(\mathbf{W}\) para quatro unidades/estados (A, B, C, D), onde estado A é vizinho de B e C; B é vizinha apenas de A; C é vizinho apenas de A e, D é isolado.
A normalização por linha transforma a matriz da seguinte forma:
\[
\mathbf{W} =
\begin{array}{c|cccc}
& A & B & C & D \\
\hline
A & 0 & 1 & 1 & 0 \\
B & 1 & 0 & 0 & 0 \\
C & 1 & 0 & 0 & 0 \\
D & 0 & 0 & 0 & 0 \\
\end{array}
\quad \rightarrow \quad
\mathbf{W}^{r} =
\begin{array}{c|cccc}
& A & B & C & D \\
\hline
A & 0 & 0.5 & 0.5 & 0 \\
B & 1 & 0 & 0 & 0 \\
C & 1 & 0 & 0 & 0 \\
D & 0 & 0 & 0 & 0 \\
\end{array}
\]
Cada unidade recebe uma influência total igual a 1 de seus vizinhos. A unidade A (com dois vizinhos) recebe 50% de sua influência de B e 50% de C. B e C (cada um com um único vizinho) recebem 100% de sua influência de A. D não recebe influência. A defasagem espacial para a unidade A, \((\mathbf{W}^{r}\mathbf{y})_A\), é \(0.5 \cdot y_B + 0.5 \cdot y_C\), a média simples dos valores de seus vizinhos.
Code
if (!require("pacman")) install.packages("pacman")pacman::p_load(sf, spdep, geobr, dplyr)# Carregar mapa do estado de Sergipe se_sf <-read_municipality(code_muni ="SE", year =2020, showProgress =FALSE)# Criar vizinhança (Queen)nb <-poly2nb(se_sf, queen =TRUE)# Criar Matriz Binária (0 e 1)# Necessária para os cálculos manuais de Coluna, Espectral e CARW_binaria <-nb2mat(nb, style ="B", zero.policy =TRUE)paste("Dimensão da Matriz W:", nrow(W_binaria), "x", ncol(W_binaria))
[1] "Dimensão da Matriz W: 75 x 75"
Code
# Normalização por linha, style = "W"lw_row <-nb2listw(nb, style ="W", zero.policy =TRUE)# Extrair a matriz de pesos para verificaçãoW_row <-listw2mat(lw_row)# A soma dos pesos de cada linha deve ser 1 (para quem tem vizinhos)soma_linhas <-rowSums(W_row)print(head(soma_linhas)) # Deve mostrar 1, 1, 1... (por baixo),
1 2 3 4 5 6
1 1 1 1 1 1
Code
#os de cima sao indices que identificam Municipios
Normalização por Coluna (Column-Standardization)
Cada peso é dividido pela soma da coluna correspondente:
Esta abordagem equaliza a capacidade de emitir influência de cada unidade. Enquanto a normalização por linha controla o impacto recebido, a normalização por coluna controla o impacto causado.
Exemplo: Usando a mesma matriz \(\mathbf{W}\) definida anteriormente, a normalização por coluna resulta em:
\[
\mathbf{W} =
\begin{array}{c|cccc}
& A & B & C & D \\
\hline
A & 0 & 1 & 1 & 0 \\
B & 1 & 0 & 0 & 0 \\
C & 1 & 0 & 0 & 0 \\
D & 0 & 0 & 0 & 0 \\
\end{array}
\quad \rightarrow \quad
\mathbf{W}^{c} =
\begin{array}{c|cccc}
& A & B & C & D \\
\hline
A & 0 & 1 & 1 & 0 \\
B & 0.5 & 0 & 0 & 0 \\
C & 0.5 & 0 & 0 & 0 \\
D & 0 & 0 & 0 & 0 \\
\end{array}
\]
A influência total que cada unidade emite é normalizada para 1. A unidade A é alvo da influência de B e C; portanto, a coluna A (influência emitida para A) soma 2 (vinda de B e C). Cada conexão para A recebe peso \(1/2\). A unidade B emite influência apenas para A (coluna B soma 1), logo, a conexão de A para B recebe peso 1. Assim, a defasagem espacial agora é um vetor onde o valor para cada unidade é a soma dos valores das unidades que ela influencia, ponderada pela intensidade. Para a unidade A, \((\mathbf{W}^{c}\mathbf{y})_A = 1 \cdot y_B + 1 \cdot y_C\). Esta abordagem é menos comum, mas pode ser relevante em modelos de difusão ou análise de redes, onde o out-degree (influência emitida) é um objeto de interesse central.
Code
# Calcular a soma de cada coluna da matriz bináriacol_somas <-colSums(W_binaria)# Proteção contra divisão por zero (caso haja ilhas)col_somas[col_somas ==0] <-1# Dividir cada elemento pela soma da sua coluna# A função sweep aplica a operação na MARGIN=2 (colunas)W_col <-sweep(W_binaria, MARGIN =2, STATS = col_somas, FUN ="/")# A soma da primeira coluna deve ser 1paste("Soma da Coluna 1:", sum(W_col[,1]))
[1] "Soma da Coluna 1: 1"
Normalização espectral (ou por autovalor máximo): Para preservar as proporções relativas originais entre os pesos (especialmente importante em matrizes baseadas em distância), normaliza-se toda a matriz por seu autovalor de maior módulo, \(\lambda_{max}\):
Esta abordagem mantém a simetria da matriz (se originalmente simétrica) e preserva o significado físico original dos pesos (ex., um decaimento por distância). É recomendada por autores como @kelejian2010specification e @elhorst2014spatial para evitar distorções na estrutura de dependência.
Code
# Calcular autovalores da matriz bináriaautovalores <-eigen(W_binaria, only.values =TRUE)$values# Encontrar o maior autovalor absoluto (Raio Espectral)lambda_max <-max(abs(autovalores))# Normalizar a matrizW_spec <- W_binaria / lambda_max# O maior autovalor da nova matriz deve ser 1print(paste("Novo Lambda Max:", max(abs(eigen(W_spec, only.values=TRUE)$values))))
[1] "Novo Lambda Max: 1"
Normalização de variância escalar (para modelos CAR): Em modelos autorregressivos condicionais (CAR) bayesianos, busca-se frequentemente uma matriz simétrica para definir uma matriz de precisão válida. Uma normalização comum é:
onde \(\mathbf{D}\) é uma matriz diagonal com \(d_{ii} = \sum_j w_{ij}\). Esta forma estabiliza a variância e preserva a simetria.
Code
# Fórmula: D^(-1/2) * W * D^(-1/2)# Obter número de vizinhos (D) de cada áreanum_vizinhos <-rowSums(W_binaria)# Calcular a matriz diagonal inversa da raiz quadrada (D^-1/2)# Se vizinhos = 0, mantemos 0 para evitar Infinitoinv_sqrt_D <-ifelse(num_vizinhos >0, 1/sqrt(num_vizinhos), 0)M_diag <-diag(inv_sqrt_D)# Multiplicação Matricial (%*%)W_car <- M_diag %*% W_binaria %*% M_diag# Visualizar o canto da matriz (Note que ela é simétrica)print(round(W_car[1:5, 1:5], 3))
A escolha de \(\mathbf{W}\) é frequentemente o ponto mais subjetivo e crítico da modelagem espacial. @kelejian2017spatial e @elhorst2014spatial apresentam críticas à aplicação da normalização por linha:
Perda da interpretação de distância: Se \(\mathbf{W}\) é baseada no inverso da distância (\(w_{ij} = d_{ij}^{-\alpha}\)), a normalização por linha destrói a estrutura de decaimento absoluto. Uma unidade central com muitos vizinhos próximos (\(\sum_j w_{ij}\) grande) terá seus pesos reduzidos drasticamente, enquanto uma unidade periférica com poucos vizinhos distantes (\(\sum_j w_{ij}\) pequeno) terá seus pesos inflacionados.
Indução de assimetria: Uma matriz de contiguidade ou distância é frequentemente simétrica (\(w_{ij} = w_{ji}\)). A normalização por linha gera uma matriz assimétrica (\(w_{ij}^{r} \neq w_{ji}^{r}\)), o que pode ser contra-intuitivo para noções de vizinhança e complica a interpretação em alguns modelos.
A Falácia da seleção por \(R^2\): Uma prática comum é escolher a matriz \(\mathbf{W}\) (ou seu critério de construção) que maximiza uma medida de ajuste como o \(R^2\) ou a verossimilhança do modelo. @kelejian2017spatial demonstram analiticamente que este procedimento é enviesado. Eles provam que o \(R^2\) é maximizado quando os pesos se aproximam de uma matriz de pesos uniformes. Nesse cenário, o parâmetro espacial \(\hat{\rho}\) absorve toda a variação, e os coeficientes das covariáveis \(\hat{\boldsymbol{\beta}}\) colapsam para zero, produzindo um modelo sem poder explicativo real.
Assim, a seleção de \(\mathbf{W}\) deve ser guiada pela teoria substantiva do fenômeno em estudo. Quando várias especificações são plausíveis, pode-se usar:
Critérios de seleção de modelo: Como proposto por @zhang2018spatial, que adaptam um critério do tipo \(C_p\) de Mallows para selecionar a matriz dentro de um conjunto candidato, visando minimizar o erro de previsão. Em sua forma clássica, o \(C_p\) de Mallows fornece uma estimativa do erro quadrático médio de previsão para um modelo de regressão com \(p\) parâmetros [@Mallows1973; @mallows1995more]. Sua expressão é dada por:
\[
C_p = \frac{\text{SSE}_p}{\hat{\sigma}^2} - n + 2p,
\]
onde = \(\text{SSE}_p\) é a soma dos quadrados dos resíduos do modelo candidato; \(\hat{\sigma}^2\) é uma estimativa não viciada da variância do erro do modelo mais completo (ou do modelo considerado verdadeiro); \(n\) é o número de observações e, \(p\) é o número de parâmetros do modelo (incluindo o intercepto), que atua como penalização pela complexidade.
Um valor menor de \(C_p\) indica um melhor equilíbrio entre qualidade de ajuste (SSE baixo) e parcimônia (penalidade \(p\) baixa), guiando a seleção do modelo.
@zhang2018spatial estende este princípio para modelos de defasagem espacial (SAR). A ideia central é tratar cada matriz candidata \(\mathbf{W}_k\) como um modelo distinto. Para um SAR da forma \(\mathbf{y} = \rho_k \mathbf{W}_k \mathbf{y} + \mathbf{X} \boldsymbol{\beta}_k + \boldsymbol{\varepsilon}_k\), uma estatística \(C_p\) adaptada é derivada.
Essa adaptação considera que a complexidade efetiva do modelo espacial não depende apenas do número de covariáveis em \(\mathbf{X}\), mas também da estrutura de dependência induzida por \(\mathbf{W}_k\) e do parâmetro espacial \(\rho_k\). O traço da matriz de projeção (ou hat matrix) do modelo SAR, \(\text{tr}(\mathbf{H}_k)\), que generaliza o número de parâmetros \(p\), é tipicamente utilizado na penalização. A estatística resultante pode ser aproximada por:
onde \(\text{SSE}_k\) e \(\text{tr}(\mathbf{H}_k)\) são calculados para o modelo estimado com a matriz \(\mathbf{W}_k\). A matriz \(\mathbf{W}_k\) que minimiza \(C_p(\mathbf{W}_k)\) no conjunto candidato é então selecionada.
@zhang2018spatial demonstra que este procedimento é assintoticamente ótimo no sentido de minimizar o erro quadrático médio de previsão, mesmo que a verdadeira matriz de pesos (geradora dos dados) não esteja incluída no conjunto \(\{\mathbf{W}_1, \ldots, \mathbf{W}_K\}\).
Média de modelos: Uma evolução natural deste paradigma é reconhecer a incerteza inerente à escolha de uma única matriz. Em vez de selecionar um único \(\mathbf{W}_k\), a abordagem de média de modelos combina as previsões de todos os modelos candidatos, atribuindo-lhes pesos que refletem seu suporte empírico. @miao2025spatial estendem esta lógica para modelos espaciais multivariados (MSAR). Eles propõem estimar pesos \(\pi_k\) para cada modelo (cada um com sua matriz \(\mathbf{W}_k\)) de modo a minimizar o risco de predição. A previsão final é uma média ponderada:
onde \(\hat{\mathbf{y}}_k\) é a previsão do modelo com matriz \(\mathbf{W}_k\). Esta estratégia geralmente produz previsões mais robustas e estáveis do que qualquer modelo individual, pois incorpora a incerteza sobre a estrutura de dependência espacial correta.
1.2 Implicações estatísticas da discretização espacial
A agregação de um processo contínuo em unidades de área discretas introduz desafios inferenciais profundos que vão além do MAUP.
O MAUP possui duas dimensões @openshaw1984modifiable . O efeito de escala refere-se à mudança nos resultados ao se alterar o nível de agregação (ex.: de bairros para municípios). O efeito de zoneamento refere-se à mudança nos resultados ao se redesenhar os limites das unidades no mesmo nível de agregação. Ambos podem alterar ou até inverter o sinal de correlações e parâmetros espaciais, pois a discretização atua como um filtro não linear na estrutura de covariância do processo subjacente.
Em dados de contagem (ex.: casos de doença), a variabilidade observada é uma combinação da variação do processo espacial latente de risco (\(Y(\mathbf{s})\)) e da variação inerente ao mecanismo de amostragem (ex.: distribuição de Poisson). Em áreas com populações pequenas, a flutuação amostral pode dominar, criando padrões espúrios. @cressie1989spatial mostram, no estudo da Síndrome da Morte Súbita Infantil (SIDS), como a heterogeneidade do tamanho da população-base pode gerar autocorrelação espacial aparente. Modelos hierárquicos que incorporam um offset populacional ou usam distribuições como a Binomial negativa são essenciais para separar esses efeitos.
A agregação tende a alisar a variação local de um processo contínuo, podendo atenuar hotspots reais. Além disso, como alertado por @reich2006effects, a inclusão de termos de dependência espacial (como um processo CAR ou SAR) para capturar correlação nos resíduos pode introduzir colinearidade com as covariáveis fixas do modelo, inflando a variância das estimativas dos coeficientes \(\boldsymbol{\beta}\) e complicando a inferência.
A estrutura de dependência inferida é altamente condicional à matriz \(\mathbf{W}\) especificada. Duas observações fisicamente próximas, mas separadas por uma fronteira administrativa que não é considerada no critério de vizinhança, serão modeladas como independentes. Portanto, a dependência espacial estimada é, em grande parte, uma função da discretização e da definição de vizinhança adotada, e não apenas uma propriedade intrínseca do fenômeno [@hodges2010adding].
1.3 Análise exploratória em dados de área
A Análise Exploratória de Dados Espaciais (ESDA – Exploratory Spatial Data Analysis) é definida por @anselin1995local como um conjunto de técnicas destinadas a: (i) descrever e visualizar distribuições espaciais; (ii) identificar localizações atípicas (spatial outliers); (iii) detectar padrões de associação espacial (clusters); e (iv) sugerir regimes de heterogeneidade espacial. Diferentemente da estatística descritiva clássica, a ESDA não assume independência entre as observações. O seu objetivo central é, justamente, quantificar a natureza e a intensidade da dependência espacial, que é definida pela estrutura de vizinhança \(\mathbf{W}=[w_{ij}]_{n \times n}\) (ver Section 1.1). A ESDA é uma extensão da Análise Exploratória de Dados (EDA) para o contexto espacial, mantendo seu caráter visual e robusto, mas com a adição fundamental do mapa como ferramenta central para responder a perguntas como “onde estão esses casos no mapa?” ou “quais áreas nesta sub-região atendem a critérios específicos de atributo?” @haining1998exploratory .
Em dados de área (lattice), onde \(y_i\) representa um valor agregado na unidade discreta \(i\), a análise divide-se fundamentalmente em duas categorias: indicadores globais (que resumem o padrão de todo o mapa num único escalar) e indicadores locais (que decompõem a estrutura de dependência para cada \(i\)-unidade individualmente). A implementação prática da ESDA frequentemente ocorre em ambientes de Sistemas de Informação Geográfica (GIS), que integram capacidades de visualização cartográfica, gestão de dados e análise estatística interativa, como exemplificado pelo sistema SAGE descrito por @haining1998exploratory. Este capítulo, assim como feito nos outros capítulos, usaremos o R/Rstudio.
1.3.1 Estatísticas globais de autocorrelação
As estatísticas globais testam a hipótese nula de aleatoriedade espacial completa (CSR - Complete Spatial Randomness). Sob \(H_0\), os valores \(\{y_i\}\) são distribuídos aleatoriamente pelas localizações fixas, sem respeitar a topologia definida por \(\mathbf{W}\).
Índice I de Moran
O Índice de Moran (\(I\)) é a medida de autocorrelação espacial mais amplamente utilizada, introduzida formalmente por @moran1950notes . A sua estrutura é análoga ao coeficiente de correlação de Pearson, mas ponderada pela matriz de pesos espaciais. Para um vetor de observações \(\mathbf{y} = (y_1, \dots, y_n)^\top\) com \(n\) unidades:
onde \(\mathbf{z} = (y_1 - \bar{y}, \dots, y_n - \bar{y})^\top\) é o vetor dos desvios em relação à média \(\bar{y}\), \(w_{ij}\) são os elementos da matriz de pesos espaciais \(\mathbf{W}\) (tipicamente normalizada por linha, ver Section 1.1.2), e \(S_0 = \sum_{i=1}^n \sum_{j=1}^n w_{ij}\) é a soma de todos os pesos (que iguala \(n\) no caso de normalização por linha).
O valor esperado de \(I\) sob \(H_0\) é \(E[I] = -1/(n-1)\), que tende a zero quando \(n\) aumenta.
\(I > E[I]\): Indica autocorrelação espacial positiva (agrupamento de valores semelhantes no espaço).
\(I < E[I]\): Indica autocorrelação espacial negativa (dispersão perfeita ou padrão de xadrez).
A inferência é geralmente realizada através de uma abordagem de permutação condicional (Monte Carlo), uma vez que a aproximação à normalidade depende de pressupostos assintóticos que podem não se verificar em matrizes de pesos irregulares, como discutido por @getis1995cliff.
Propriedades estatísticas do Índice de Moran
Embora “não exista” um teste uniformemente mais poderoso (UMP) para autocorrelação espacial em todos os cenários, @tiefelsdorf2000modelling demonstrou que o \(I\) de Moran é um teste Localmente Melhor Invariante (LBI). Isso significa que, na vizinhança da hipótese nula (\(\rho \approx 0\)), a função de poder do \(I\) de Moran possui a inclinação mais acentuada em comparação a outros testes. Isso torna o \(I\) de Moran a ferramenta mais sensível para detectar pequenos desvios da aleatoriedade, sendo eficaz tanto contra hipóteses alternativas de processos autorregressivos (AR) quanto de médias móveis (MA)18.
@burridge1980cliff provou que o \(I\) de Moran é assintoticamente equivalente a um teste de Multiplicador de Lagrange (LM) para processos gaussianos. A estatística LM, calculada a partir da função de verossimilhança restrita, é proporcional ao valor de \(I\), compartilhando assim as propriedades de eficiência computacional dos testes LM, que exigem estimação apenas sob a hipótese nula e são mais conservadores que os testes de Razão de Verossimilhança (LR).
Code
if (!require("pacman")) install.packages("pacman")pacman::p_load(sf, spdep, ggplot2, patchwork, dplyr, geobr)#Carregar dados: Malha de Minas Gerais (MG)mg_sf <-read_municipality(code_muni ="MG", year =2020, showProgress =FALSE)#simulando dadoscoords <-st_coordinates(st_centroid(mg_sf))set.seed(123)mg_sf$indicador <- (-coords[,2]) *10+rnorm(nrow(mg_sf), mean =0, sd =15)# Definir Vizinhança e Pesos# Vizinhança Queennb <-poly2nb(mg_sf, queen =TRUE)# normalizar por linha (style W)lw <-nb2listw(nb, style ="W", zero.policy =TRUE) #recomendo usar sempre zero.policy = TRUE# Cálculo do Índice de Moran# A) Teste Rápido para variavel de interresse "indicador"moran_analitico <-moran.test(mg_sf$indicador, listw=lw, randomisation =TRUE)print(moran_analitico)
Moran I test under randomisation
data: mg_sf$indicador
weights: lw
Moran I statistic standard deviate = 29.13, p-value < 2.2e-16
alternative hypothesis: greater
sample estimates:
Moran I statistic Expectation Variance
0.6193722870 -0.0011737089 0.0004537973
Code
# B) Teste Monte Carlo (Robusto)# Simula 999 permutações aleatóriasmoran_mc <-moran.mc(mg_sf$indicador, listw=lw, nsim =999)print(moran_mc)
Monte-Carlo simulation of Moran I
data: mg_sf$indicador
weights: lw
number of simulations + 1: 1000
statistic = 0.61937, observed rank = 1000, p-value = 0.001
alternative hypothesis: greater
Interpretação
Como normalizamos a matriz \(\mathbf{W}\) por linha, o intervalo do índice de Moran é limitado, tipicamente variando entre -1 e 1.
O valor da estatística I de Moran calculado foi de aproximadamente 0,619. Este valor positivo e de magnitude elevada indica uma forte autocorrelação espacial positiva, sugerindo que municípios com indicador socioeconômico alto tendem a estar geograficamente agrupados com outros de indicador alto (neste caso, no Sul), enquanto municípios com indicador baixo formam aglomerados com seus vizinhos de indicador baixo (neste caso, no Norte).
Para validar se este agrupamento é meramente fruto do acaso, compara-se o valor observado com o valor esperado sob a hipótese nula de aleatoriedade espacial completa (Expectation), que neste caso é -0,0012 (calculado como \(-1/(n-1) = -1/(853-1) \approx -0,0012\)). A diferença substancial entre o valor observado (Statistic \(\approx 0,62\)) e o esperado (-0,0012) fornece a evidência primária de que o processo gerador dos dados não é aleatório. A confirmação estatística desta observação na abordagem analítica é dada pelo desvio padrão padronizado (standard deviate ou Z-score) de 29,13. Este valor é extremamente alto muito além do corte crítico de 1,96 para 95% de confiança resultando em um valor-p virtualmente nulo (\(< 2.2e-16\)). Isso nos permite rejeitar a hipótese nula com um nível de confiança de 95% (considerando que fixamos nível de significância em 5%) e confirmar a existência de dependência espacial significativa.
A abordagem via simulação de Monte Carlo fortalece essa conclusão, sendo tecnicamente preferível por não depender de pressupostos de normalidade distributiva dos dados. O resultado mostra que, ao realizar 999 permutações aleatórias dos valores do indicador pelo mapa de Minas Gerais, a estatística observada nos dados originais (statistic = 0,61937) foi superior a absolutamente todas as simulações geradas, ocupando a posição máxima (observed rank) de 1000. Isso resulta em um pseudo valor-p de 0,001, indicando que a probabilidade de se obter um padrão espacial tão ou mais organizado quanto este por mero acaso é de apenas 1 em 1000. Portanto, conclui-se que a variável analisada apresenta dependência espacial positiva significativa.
Índice C de Geary
Proposto por Robert Charles Geary e desenvolvido por @cliff1981spatial, este indicador (\(c\)) foca na dissimilaridade quadrática entre vizinhos, em vez da covariância (produto cruzado):
Enquanto o \(I\) de Moran é uma medida de covariância global, o \(c\) de Geary assemelha-se ao variograma da geoestatística (?@sec-variograma), medindo a variância local das diferenças.
\(0 < c < 1\): Autocorrelação positiva (vizinhos são similares, diferenças ao quadrado são pequenas).
\(c > 1\): Autocorrelação negativa (vizinhos são dissimilares).
\(c \approx 1\): Ausência de autocorrelação espacial.
@anselin2001spatial nota que o \(I\) de Moran é mais sensível a tendências globais e clusters, enquanto o \(c\) de Geary é mais sensível a diferenças locais e outliers espaciais.
Code
pacman::p_load(ggspatial)#Cálculo do Índice C de Geary# A) Teste Analíticogeary_analitico <-geary.test(mg_sf$indicador, listw=lw, randomisation =TRUE)# B) Teste Monte Carloset.seed(123)geary_mc <-geary.mc(mg_sf$indicador, listw=lw, nsim =999)print(geary_analitico)
Geary C test under randomisation
data: mg_sf$indicador
weights: lw
Geary C statistic standard deviate = 26.149, p-value < 2.2e-16
alternative hypothesis: Expectation greater than statistic
sample estimates:
Geary C statistic Expectation Variance
0.377124962 1.000000000 0.000567393
Code
print(geary_mc)
Monte-Carlo simulation of Geary C
data: mg_sf$indicador
weights: lw
number of simulations + 1: 1000
statistic = 0.37712, observed rank = 1, p-value = 0.001
alternative hypothesis: greater
Code
# Calculamos o Geary Local (localC) para ver onde vizinhos diferem muito.# Valores altos no mapa indicam vizinhos muito diferentes (outliers locais).mg_sf$geary_local <-localC(mg_sf$indicador, listw=lw)# Mapa da Variável Originalp1 <-ggplot(mg_sf) +geom_sf(aes(fill = indicador), color =NA) +scale_fill_viridis_c(option ="magma", name ="Valor") +labs(title ="A. Variável Original", subtitle ="Padrão Norte-Sul") +theme_void()+annotation_scale(location ="bl", width_hint =0.3, bar_cols =c("black", "white")) +annotation_north_arrow(location ="tl", which_north ="true", pad_x =unit(0.2, "in"), pad_y =unit(0.2, "in"),style = north_arrow_fancy_orienteering)# Mapa de Geary Localp2 <-ggplot(mg_sf) +geom_sf(aes(fill = geary_local), color =NA) +scale_fill_viridis_c(option ="cividis", name ="Local C") +labs(title ="B. Dissimilaridade Local (Geary)", subtitle ="Áreas claras = Vizinhos muito diferentes") +theme_void()+annotation_scale(location ="bl", width_hint =0.3, bar_cols =c("black", "white")) +annotation_north_arrow(location ="tl", which_north ="true", pad_x =unit(0.2, "in"), pad_y =unit(0.2, "in"),style = north_arrow_fancy_orienteering)p1 + p2
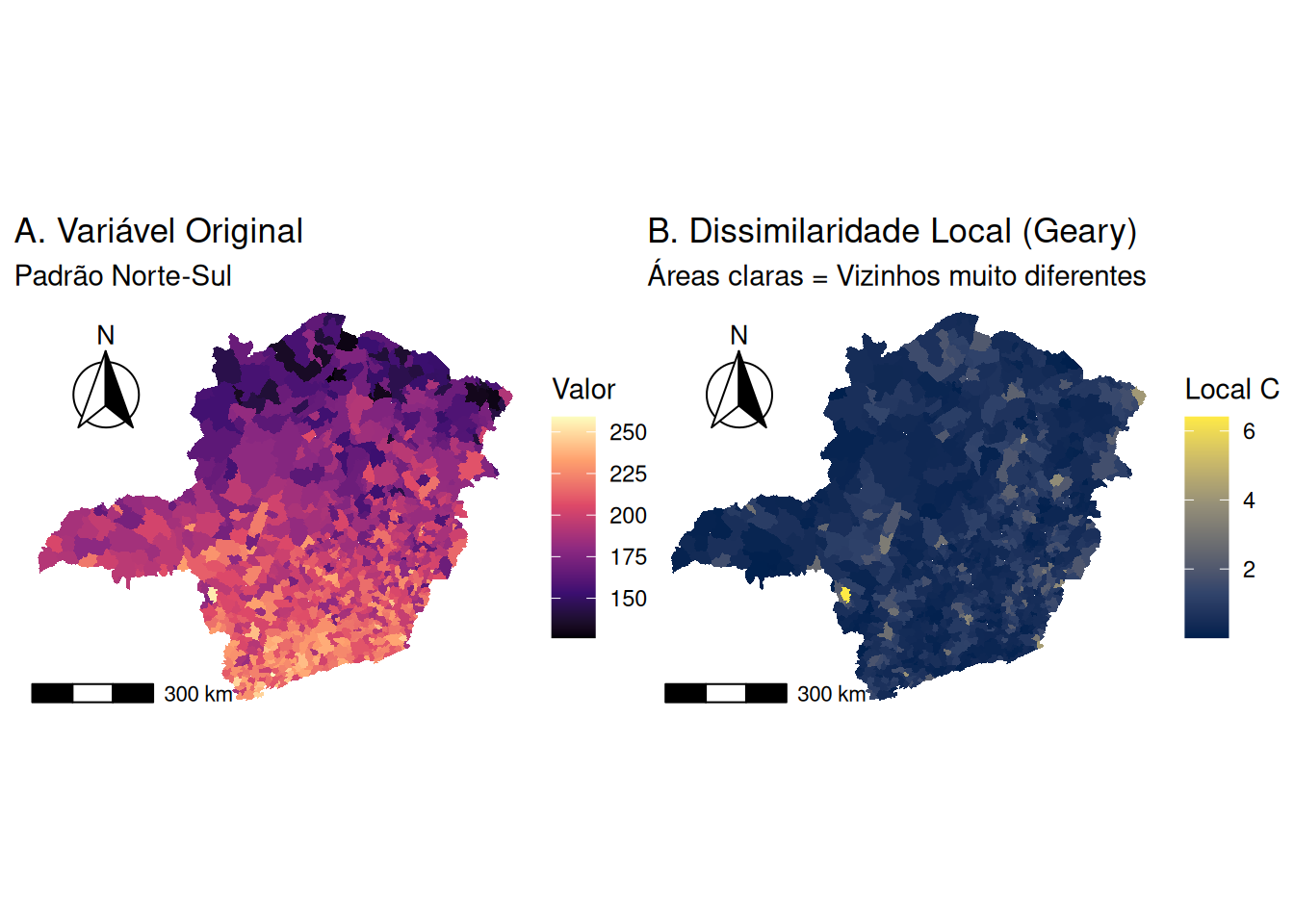
Figure 6: Índice C de Geary: Teste Global e Mapa de Dissimilaridade Local.
Interpretação
A análise do Índice C de Geary confirma a existência de autocorrelação espacial positiva fort. O valor estatístico observado (Geary C statistic 0,377) situa-se substancialmente abaixo do valor esperado sob a hipótese de aleatoriedade espacial (Expectation = 1,0). Como \(0<c<1\), conclui-se que a variância local (diferença entre vizinhos) é muito menor do que a variância global, ou seja, vizinhos tendem a ser parecidos.
A significância estatística deste padrão é atestada pelo elevado desvio padrão padronizado (standard deviate = 26,15), que resulta em um valor-p baixo (p-value < 2.2e-16). Isso permite rejeitar a hipótese nula com um nível de confiança de 95% e confirmar que a similaridade entre as unidades espaciais não é aleatória.
A validação via Monte Carlo reforça o resultado obtido. A estatística observada (statistic = 0,377) foi mais extrema (menor) do que todas as 999 permutações aleatórias geradas, ocupando a primeira posição no ranking de dissimilaridade (observed rank = 1). Isso gera um pseudo valor-p significativo (p-value = 0,001), confirmando que a probabilidade de tal padrão de aglomeração surgir ao acaso é desprezível (1 em 1000).
1.3.2 Suporte das estatísticas \(I\) e \(c\)
É comum assumir incorretamente que o Índice de Moran varia estritamente no intervalo \([-1, 1]\), tal como o coeficiente de correlação de Pearson. No entanto, o suporte (intervalo de valores possíveis) das estatísticas de autocorrelação espacial não é fixo [@scalon2024analise]; ele é intrinsecamente dependente da topologia da rede definida por \(\mathbf{W}=[w_{ij}]_{n \times n}\) (matriz de pesos ou vizinhança) e pode ultrapassar esses limites dependendo da geometria dos vizinhos.
Suporte do Índice de Moran
@de1984extreme discutem este problema abordando-o através da álgebra matricial. Eles demonstram que os valores extremos (limites mínimo e máximo) de \(I\) correspondem aos autovalores da matriz de pesos, sujeitos à restrição de que os dados são centrados na média (\(\mathbf{z}^\top \mathbf{1} = 0\), ver Equation 1).
Para uma dada matriz de pesos \(\mathbf{W}\), os limites inferior (\(I_{min}\)) e superior (\(I_{max}\)), necessários para definir o suporte do índice de Moran são dados por:
Onde \(\lambda_{min}\) e \(\lambda_{max}\) são, respectivamente, o menor e o maior autovalor da matriz de pesos projetada no subespaço ortogonal ao vetor constante.
Se \(\mathbf{W}\) for simétrica, estes são simplesmente os autovalores extremos (menor e maior autovalor) de \(\mathbf{W}\) (excluindo o autovalor trivial associado à média constante). Caso \(\mathbf{W}\) seja assimétrica (comum em vizinhança por \(k\)-vizinhos), os autovalores são calculados a partir da parte simétrica da matriz, \(\mathbf{S} = \frac{1}{2}(\mathbf{W} + \mathbf{W}^\top)\).
Extremos do Índice de Geary
De forma análoga, @de1984extreme derivaram os limites para a estatística \(c\) de Geary reformulando o seu numerador como uma forma quadrática. Os valores extremos são definidos como:
Neste caso, \(\gamma_{min}\) e \(\gamma_{max}\) representam os autovalores extremos (menor e maior autovalor) de uma matriz auxiliar \(\mathbf{B}\), cujos elementos \(b_{ij}\) são construídos combinando a estrutura de conectividade com os totais marginais dos pesos6:
\[
b_{ij} = (R_i + K_j)\delta_{ij} - 2w_{ij}
\]
Sendo \(R_i\) a soma da linha \(i\) de \(\mathbf{W}\), \(K_j\) a soma da coluna \(j\), e \(\delta_{ij}\) o delta de Kronecker (1 se \(i=j\), 0 caso contrário).
O cálculo destes limites exatos é crucial para a validação estatística. Se utilizarmos uma aproximação teórica (como a distribuição Normal) que atribua probabilidade a valores fora do intervalo \([I_{min}, I_{max}]\), estaremos cometendo um erro de especificação, atribuindo probabilidade a eventos impossíveis para aquela configuração espacial específica. Além disso, @de1984extreme notam que a simetria desses limites fornece informação sobre a estrutura da rede; por exemplo, grafos do tipo estrela possuem limites muito distintos de reticulados regulares (grids), o que afeta a interpretação da magnitude da autocorrelação.
1.3.3 Estatísticas Locais
A dependência espacial raramente é estacionária sobre todo o domínio \(D^L\). @anselin1995local introduziu o conceito de LISA (Local Indicators of Spatial Association) para decompor a estatística global em contribuições individuais \(I_i\), satisfazendo duas propriedades:
O indicador \(I_i\) permite avaliar a significância do padrão espacial local em torno da unidade \(i\).
A soma dos indicadores locais é proporcional à estatística global (ex: \(\sum_i I_i \propto I\)).
Índice I de Moran local
O Moran local (\(I_i\)) avalia a correlação entre o valor de uma unidade e a média dos seus vizinhos (o spatial lag) Figure 7. É definido como:
onde \(S^2 = \sum_{j=1}^n (y_j - \bar{y})^2 / n\) é a variância amostral.
Esta estatística é a base para o mapa de clusters LISA, que classifica cada localidade estatisticamente significativa em quatro quadrantes, baseados no sinal de \(z_i = (y_i - \bar{y})\) (valor local) e do seu defasamento espacial (spatial lag) \(\sum_j w_{ij} (y_j - \bar{y})\) (valor dos vizinhos):
Alto-Alto (High-High | HH): Este quadrante (superior direito) representa o regime de associação espacial positiva onde uma unidade com valor acima da média é circundada por vizinhos que também possuem valores altos. Estatisticamente, identifica-se aqui a formação de clusters (agrupamentos) de alta intensidade, conhecidos como hot spots. A sua presença sugere fortes fenômenos de contágio ou transbordamento (spillover), indicando que os fatores que elevam a variável numa localidade estão também presentes e ativos na sua vizinhança imediata.
Baixo-Baixo (Low-Low | LL): Define-se pelo agrupamento de uma unidade com valor abaixo da média cercada por \(j\) vizinhos que compartilham essa característica de baixa intensidade. Este padrão, denominado cold spot, indica também autocorrelação espacial positiva, mas na direção oposta aos hot spots. Podendo refletir barreiras geográficas à difusão de um fenômeno ou áreas estruturalmente desfavorecidas (ou protegidas, dependendo se a variável é benéfica ou maléfica) em bloco.
Alto-Baixo (High-Low | HL): Caracteriza-se por uma unidade com valor alto que está isolada em meio a uma vizinhança de valores predominantemente baixos, configurando um outlier espacial. Este padrão de autocorrelação negativa sugere que o processo gerador de dados na unidade central é distinto do seu entorno. Frequentemente indica vulnerabilidades locais específicas, erros de medição, ou um surto localizado que, por algum motivo de contenção, não transbordou para as regiões adjacentes.
Baixo-Alto (Low-High | LH): Refere-se a uma unidade com valor abaixo da média que está cercada por vizinhos com valores altos. Como um outlier espacial inverso, esta configuração indica autocorrelação negativa. Pode sinalizar a eficácia de políticas de contenção locais (resiliência), subnotificação de dados em relação aos vizinhos, ou características intrínsecas que tornam a unidade impermeável à influência do seu entorno de alta intensidade.
Code
pacman::p_load(tidyverse,sf,spdep,geobr,patchwork, ggtext, ggspatial) # Cálculo do Moran Localloc_m <-localmoran(mg_sf$indicador, listw=lw)# Preparar dados para plotagemmg_sf$z_score <-as.numeric(scale(mg_sf$indicador)) mg_sf$lag_z <-lag.listw(lw, mg_sf$z_score) mg_sf$p_value <- loc_m[, 5] # P-valor do teste local# Classificação dos Quadrantessig_level <-0.05mg_sf <- mg_sf %>%mutate(quadrante =case_when( p_value > sig_level ~"NS", z_score >0& lag_z >0~"HH", z_score <0& lag_z <0~"LL", z_score >0& lag_z <0~"HL", z_score <0& lag_z >0~"LH" )) %>%mutate(quadrante =factor(quadrante, levels =c("HH", "LL", "HL", "LH", "NS"),labels =c("Alto-Alto (HH)", "Baixo-Baixo (LL)", "Alto-Baixo (HL)", "Baixo-Alto (LH)", "Não Significativo")))# Corescores_lisa <-c("Alto-Alto (HH)"="#FF0000", "Baixo-Baixo (LL)"="#0000FF", "Alto-Baixo (HL)"="#FFA500", "Baixo-Alto (LH)"="#87CEFA", "Não Significativo"="#eeeeee")# Mapag_map <-ggplot(mg_sf) +geom_sf(aes(fill = quadrante), color ="black", size =0.05) +scale_fill_manual(values = cores_lisa) +theme_void() +labs(title ="A. LISA",subtitle ="Identificação de regimes locais (p < 0.05)", fill="Legenda") +theme(plot.title =element_text(size =12, face ="bold"))+annotation_scale(location ="bl", width_hint =0.3, bar_cols =c("black", "white"), text_family ="sans" ) +annotation_north_arrow(location ="tl", which_north ="true", pad_x =unit(0.2, "in"), pad_y =unit(0.2, "in"), style = north_arrow_fancy_orienteering )#g_scatter <-ggplot(mg_sf, aes(x = z_score, y = lag_z)) +geom_hline(yintercept =0, linetype ="dashed", color ="gray50") +geom_vline(xintercept =0, linetype ="dashed", color ="gray50") +geom_point(aes(color = quadrante), size =1.5, alpha =0.6) +# Linha de regressão (Moran Global)geom_smooth(method ="lm", se =FALSE, color ="black", size =0.8) +# Anotações dos Quadrantesannotate("text", x =2, y =2, label ="HH", color ="red", fontface="bold") +annotate("text", x =-2, y =-2, label ="LL", color ="blue", fontface="bold") +annotate("text", x =2, y =-1, label ="HL", color ="orange", fontface="bold") +annotate("text", x =-2, y =1, label ="LH", color ="#87CEFA", fontface="bold") +scale_color_manual(values = cores_lisa) +labs(title ="B. Diagrama de Dispersão",subtitle =paste("I de Moran Global:", round(moran.test(mg_sf$indicador, lw)$estimate[1], 3)),x ="Valor Padronizado (y)",y ="Defasagem Espacial (Wy)") +theme_minimal() +theme(legend.position ="none",plot.title =element_text(size =12, face ="bold"))g_map + g_scatter
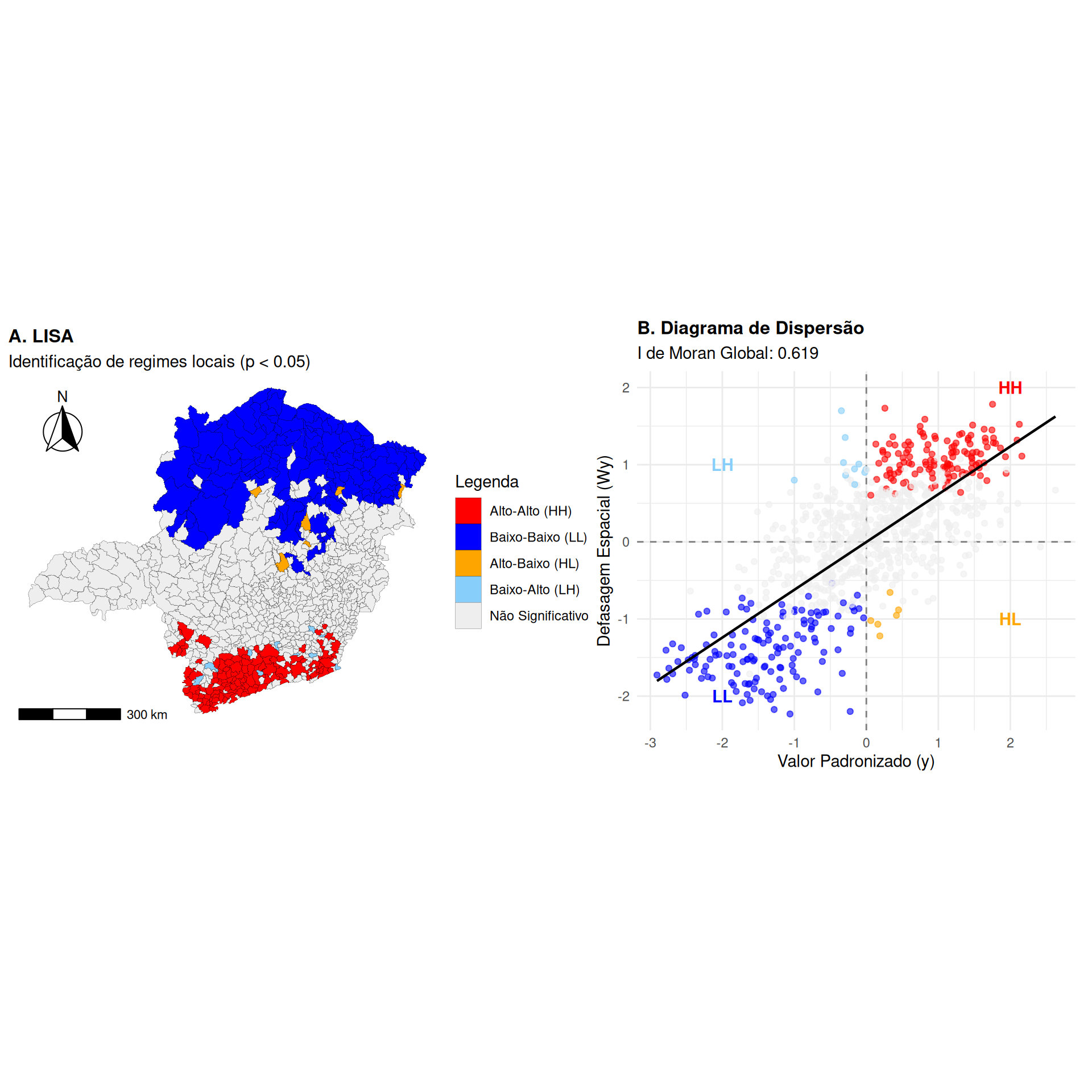
Figure 7: Clusters Espaciais LISA (Local Moran) para Minas Gerais
Interpretação
Os resultados (Figure 7) confirmam e localizam a intensa polarização espacial sugerida pelas estatísticas globais. O mapa de LISA (Figure 7 A) decompõe a dependência, evidenciando um aglomerado do tipo Alto-Alto (HH) na porção sul do estado (em vermelho), onde municípios com altos valores do indicador estão circundados por vizinhos com valores igualmente elevados. Em contrapartida, observa-se um vasto aglomerado do tipo Baixo-Baixo (LL) dominando as regiões Norte e Nordeste (em azul), caracterizando um regime espacial de valores baixos cercados por vizinhos também com baixos valores.
O Diagrama de dispersão de Moran (Figure 7 B) mostra a quase totalidade das observações significativas (pontos coloridos) se concentra nos quadrantes de associação positiva (HH e LL). A escassez de pontos nos quadrantes de transição ou outliers espaciais (HL e LH) reflete a alta continuidade do fenômeno e a existência de fronteiras nítidas entre os regimes. A inclinação da reta de regressão, correspondente ao I de Moran Global de 0,619, atesta que o valor de um município é um forte preditor positivo da média de seus vizinhos, validando estatisticamente o gradiente Norte-Sul presente nos dados.
Estatísticas Getis-Ord (\(G_i\) e \(G_i^*\))
Desenvolvidas por @getis1992analysis e @Getis2010SpatialAutocorrelation, estas estatísticas focam especificamente na deteção de agrupamentos de valores altos ou baixos baseados em distância, sem a componente de covariância negativa do Moran.
\(G_i\) (sem auto-inclusão): Mede a concentração de valores na vizinhança, excluindo \(y_i\).
\(G_i^*\) (com auto-inclusão): Mede a concentração incluindo o valor da própria unidade \(i\):
onde \(\mathbf{W}\) é tipicamente uma matriz de pesos baseada em distância binária (1 se \(d_{ij} < d_{\max}\), 0 caso contrário).
Um valor de \(G_i^*\) significativamente positivo (Z-score alto) indica um hot spot (agrupamento de valores altos); um valor significativamente negativo indica um cold spot. Diferentemente do Moran local, o \(G_i^*\) não distingue um outlier espacial de um cluster fraco, sendo uma medida pura de intensidade local.
Code
if (!require("pacman")) install.packages("pacman")pacman::p_load(tidyverse, sf, spdep, geobr, ggspatial)#Cálculo do Getis-Ord Gi*# A função retorna os Z-scores (desvios padrão)gi_star <-localG(mg_sf$indicador, listw=lw)# Adicionar ao mapamg_sf$gi_zscore <-as.numeric(gi_star)# Classificação para o Mapa (Níveis de Confiança)# Baseado na distribuição Normal Padrãomg_sf$classificacao <-case_when( mg_sf$gi_zscore >=1.96~"Hot Spot (95%)", mg_sf$gi_zscore <=-1.96~"Cold Spot (95%)",TRUE~"Não Significativo")cores_gi <-c("Hot Spot (95%)"="#d7191c","Cold Spot (95%)"="#2c7bb6","Não Significativo"="gray90")ggplot(mg_sf) +geom_sf(aes(fill = classificacao), color ="white", size =0.05) +scale_fill_manual(values = cores_gi, name ="Intensidade (Gi*)") +theme_void() +labs(title ="Análise de Hot Spots (Getis-Ord Gi*)",subtitle ="Identificação de aglomerados de alta e baixa intensidade") +theme(plot.title =element_text(size =14, face ="bold"),legend.position ="right") +annotation_scale(location ="bl", width_hint =0.3, bar_cols =c("black", "white"), text_family ="sans" ) +annotation_north_arrow(location ="tl", which_north ="true", pad_x =unit(0.2, "in"), pad_y =unit(0.2, "in"), style = north_arrow_fancy_orienteering )
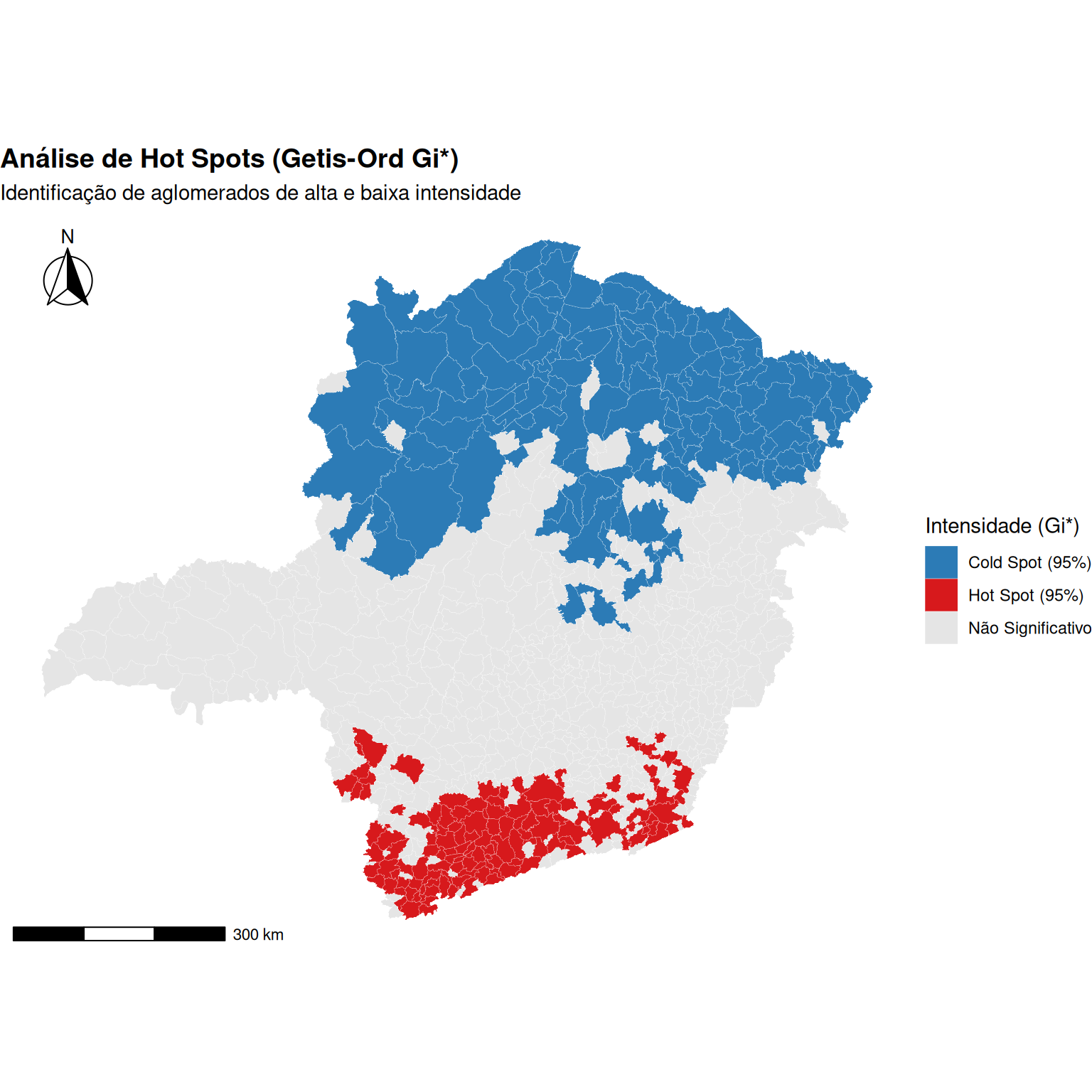
Figure 8: Análise de Hot Spots (Getis-Ord Gi*) para Minas Gerais.
Interpretação
O mapa (Figure 8) de análise de Hot Spots (Getis-Ord Gi) mostra uma clara polarização na distribuição espacial dos valores de intensidade em Minas Gerais. Observa-se a formação de um aglomerado significativo de alta intensidade (Hot Spot), representado em vermelho, concentrado na região sul do estado. Essa área indica uma aglomeração de municípios com valores elevados cercados por vizinhos também com valores elevados, sugerindo uma zona de maior atividade ou ocorrência do fenômeno analisado com 95% de confiança.
Em contrapartida, a região norte e nordeste do estado é caracterizada por um aglomerado de baixa intensidade (Cold Spot), representado em azul. Essa configuração espacial aponta para uma área onde predominam municípios com valores baixos, rodeados por outros de características similares, indicando uma depressão ou menor intensidade do fenômeno nesta porção do território. As áreas em cinza, classificadas como “Não Significativo”, representam regiões de transição ou de aleatoriedade espacial, onde não se verifica um padrão de aglomeração significativo nem para altas nem para baixas intensidades.
1.4 Riscos e Suavização
A visualização de dados de área brutos, especialmente taxas (ex: incidência de doenças), sofre de instabilidade intrínseca da variância, um problema amplamente discutido por @cressie1989spatial na análise de SIDS (Síndrome de Morte Súbita Infantil).
Mapas de risco e razão padronizada (SMR)
Para dados de contagem \(O_i\) (observados) com uma população em risco \(P_i\), a taxa bruta é \(r_i = O_i / P_i\). Em epidemiologia, utiliza-se frequentemente a razão de morbidade/mortalidade padronizada (SMR - Standardized Mortality/Morbidity Ratio):
\[
\text{SMR}_i = \frac{O_i}{E_i},
\]
onde \(E_i = P_i \cdot \bar{r}\) é o número esperado de casos sob a hipótese de uma taxa constante global \(\bar{r} = \sum_i O_i / \sum_i P_i\).
Em áreas com população \(P_i\) pequena, a variância da taxa \(r_i\) é altíssima. Um único caso adicional pode duplicar a taxa, criando outliers espúrios que dominam visualmente o mapa coroplético.
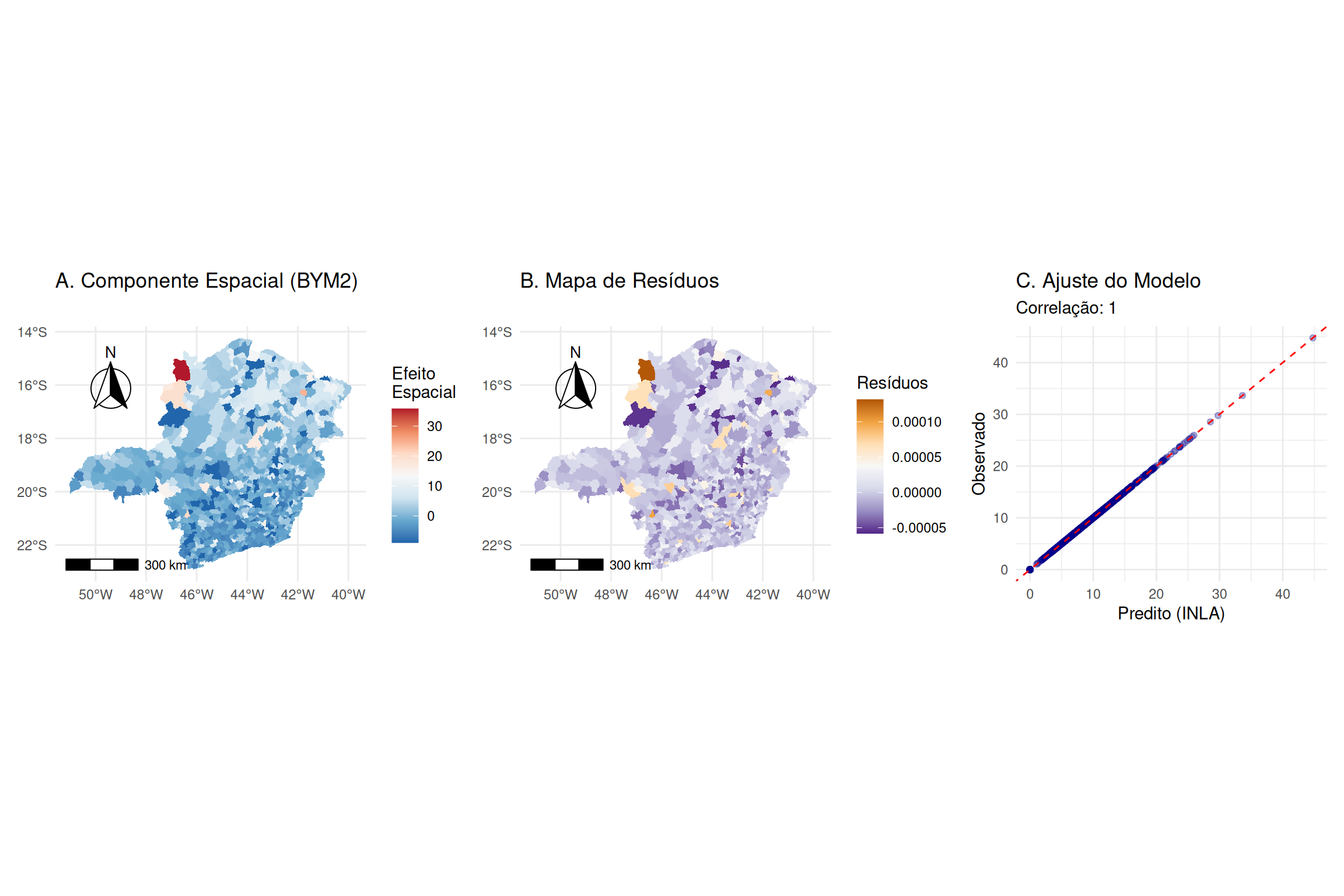
Para mitigar a instabilidade, utiliza-se a suavização Bayesiana empírica, onde a taxa estimada \(\theta_i\) é uma média ponderada entre a taxa local (instável) e a média global (estável) ou a média da vizinhança local [@banerjee2016spatial].
O peso \(\gamma_i \in [0, 1]\) depende da população \(P_i\): áreas populosas têm \(\gamma_i \approx 1\) (confia-se no dado local), áreas despovoadas têm \(\gamma_i \approx 0\) (o valor é encolhido em direção à média). @besag1993spatial estendem isto para modelos hierárquicos completos (BYM), utilizando a estrutura de vizinhança \(\mathbf{W}\) para suavizar localmente.
Code
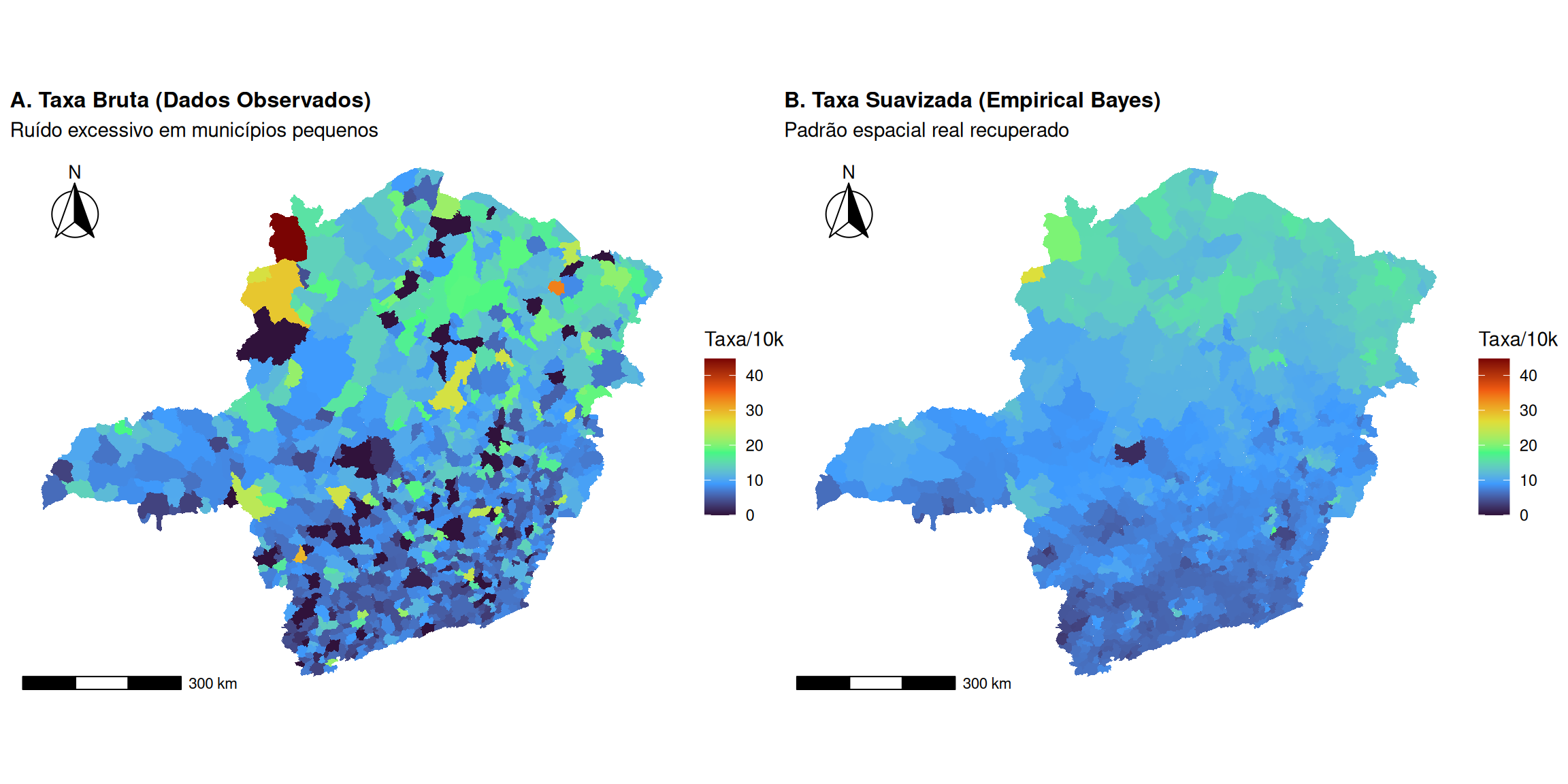
if (!require("pacman")) install.packages("pacman")pacman::p_load(tidyverse, sf, spdep, geobr, patchwork, viridis, ggspatial)mg_sf <-read_municipality(code_muni ="MG", year =2020, showProgress =FALSE)#Vamos simulação de um dataframe de dados brutos (Como viria do DATASUS)# Cenário: Incidência de uma doença rara.# O usuário teria uma tabela com: ID do Município, População em Risco, Nº de Casos.set.seed(999)# A) Simular População (ni):populacao_simulada <-floor(rlnorm(nrow(mg_sf), meanlog =9, sdlog =1.2))# B) Definir um Risco Latente (Verdadeiro, mas desconhecido):coords <-st_coordinates(st_centroid(mg_sf))padrao_norte_sul <- (coords[,2] -min(coords[,2])) / (max(coords[,2]) -min(coords[,2]))risco_real <-0.0005* (1+ (padrao_norte_sul *2)) # Risco varia de 0.05% a 0.15%# Simular Nº de Casos (yi):# Os casos são uma realização de um processo de Poisson: Casos ~ Poisson(Pop * Risco)casos_simulados <-rpois(nrow(mg_sf), lambda = populacao_simulada * risco_real)# D) Unir ao mapa mg_dados <- mg_sf %>%mutate(populacao = populacao_simulada, casos = casos_simulados #Óbitos ou Doentes )# Cálculo das Taxas # Passo 1: Calcular Taxa Bruta (Incidência por 10.000 habitantes)mg_dados <- mg_dados %>%mutate(taxa_bruta = (casos / populacao) *10000)# Passo 2: Suavização Bayesiana Empírica Local nb <-poly2nb(mg_dados, queen =TRUE)# A função EBlocal precisa dos CASOS (ri) e da POPULAÇÃO (ni)eb_resultado <-EBlocal(ri = mg_dados$casos, ni = mg_dados$populacao, nb = nb, zero.policy =TRUE)# Adicionamos a taxa suavizada ao mapa (multiplicando por 10k para ficar na mesma escala)mg_dados$taxa_suavizada <- eb_resultado$est *10000# Definir limites iguais para garantir que as cores representem os mesmos valoresescala_limites <-range(c(mg_dados$taxa_bruta, mg_dados$taxa_suavizada), na.rm =TRUE)p1 <-ggplot(mg_dados) +geom_sf(aes(fill = taxa_bruta), color =NA) +scale_fill_viridis_c(option ="turbo", limits = escala_limites, name ="Taxa/10k") +theme_void() +labs(title ="A. Taxa Bruta (Dados Observados)",subtitle ="Ruído excessivo em municípios pequenos") +theme(plot.title =element_text(size =12, face ="bold"))+annotation_scale(location ="bl", width_hint =0.3, bar_cols =c("black", "white"), text_family ="sans" ) +annotation_north_arrow(location ="tl", which_north ="true", pad_x =unit(0.2, "in"), pad_y =unit(0.2, "in"), style = north_arrow_fancy_orienteering )p2 <-ggplot(mg_dados) +geom_sf(aes(fill = taxa_suavizada), color =NA) +scale_fill_viridis_c(option ="turbo", limits = escala_limites, name ="Taxa/10k") +theme_void() +labs(title ="B. Taxa Suavizada (Empirical Bayes)",subtitle ="Padrão espacial real recuperado") +theme(plot.title =element_text(size =12, face ="bold")) +annotation_scale(location ="bl", width_hint =0.3, bar_cols =c("black", "white"), text_family ="sans" ) +annotation_north_arrow(location ="tl", which_north ="true", pad_x =unit(0.2, "in"), pad_y =unit(0.2, "in"), style = north_arrow_fancy_orienteering )p1 + p2
A análise comparativa entre as taxas brutas (Figure 9 A) e as taxas suavizadas por meio do método Bayesiano Empírico Local (Figure 9 B) evidencia a eficácia deste último na correção de distorções estatísticas. O mapa das taxas brutas (Figure 9 A) apresenta um padrão ruidoso e fragmentado, com valores extremos (muito altos ou muito baixos) dispersos aleatoriamente, refletindo a instabilidade das estimativas em municípios com pequenas populações.
Em contraste, o mapa das taxas suavizadas (Figure 9 B) mostra com clareza a estrutura espacial subjacente do fenômeno, destacando um gradiente norte-sul consistente. Ao incorporar informações da vizinhança, o método Bayesiano Empírico estabiliza as estimativas, permitindo a identificação de padrões geográficos reais que estavam obscurecidos pelo ruído nos dados brutos.
1.5 Diagnóstico de dependência espacial
A ESDA não se aplica apenas aos dados brutos (\(\mathbf{y}\)), mas é crucial no diagnóstico de modelos de regressão. Como alertado por @cressie1989spatial, a detecção de autocorrelação espacial em \(\mathbf{y}\) não implica necessariamente um processo espacial intrínseco (como contágio); pode ser resultado de heterogeneidade não observada ou variáveis omitidas que possuem padrão espacial.
O procedimento padrão, detalhado por @anselin2001spatial, envolve:
Ajustar um modelo de regressão (mínimos quadrados ordinários-OLS): \(\mathbf{y} = \mathbf{X}\boldsymbol{\beta} + \boldsymbol{\varepsilon}, : \mathbf{y} \| \mathbf{X} \sim N(\mathbf{\mu}, \Sigma)\).
Calcular os resíduos \(\hat{\boldsymbol{\varepsilon}} = \mathbf{y} - \mathbf{X}\hat{\boldsymbol{\beta}}\).
Aplicar o teste \(I\) de Moran sobre os resíduos \(\hat{\boldsymbol{\varepsilon}}\) utilizando uma matriz \(\mathbf{W}\) escolhida.
Se \(I\) for significativo, o pressuposto de independência dos erros é violado. No entanto, @zhang2018spatial demonstram que a validade deste diagnóstico depende criticamente da escolha correta de \(\mathbf{W}\). O uso de uma matriz incorreta pode falhar em detetar a dependência residual ou indicar falsamente a necessidade de um modelo espacial.
Code
if (!require("pacman")) install.packages("pacman")pacman::p_load(sf, spdep, ggplot2, patchwork, viridis)if (!exists("mg_dados")) { mg_dados <-read_municipality(code_muni ="MG", year =2020, showProgress =FALSE) coords <-st_coordinates(st_centroid(mg_dados)) mg_dados$taxa_bruta <- (-coords[,2] *10) +rnorm(nrow(mg_dados), 0, 5)}# Criar uma variável explicativa X aleatória (sem padrão espacial)set.seed(123)mg_dados$variavel_x <-rnorm(nrow(mg_dados))#Ajuste do Modelo de Regressão Linear (OLS)modelo_ols <-lm(taxa_bruta ~ variavel_x, data = mg_dados)# Extrair os resíduos do modelomg_dados$residuos <-residuals(modelo_ols)#Teste I de Moran nos Resíduos# Necessário recriar a lista de pesos (W)nb <-poly2nb(mg_dados, queen =TRUE)lw <-nb2listw(nb, style ="W", zero.policy =TRUE)# Função para resíduos de regressão (lm.morantest)moran_residuos <-lm.morantest(modelo_ols, lw, alternative ="two.sided")print(moran_residuos)
Global Moran I for regression residuals
data:
model: lm(formula = taxa_bruta ~ variavel_x, data = mg_dados)
weights: lw
Moran I statistic standard deviate = 9.3389, p-value < 2.2e-16
alternative hypothesis: two.sided
sample estimates:
Observed Moran I Expectation Variance
0.1977385849 -0.0011812437 0.0004536919
Code
p1 <-ggplot(mg_dados) +geom_sf(aes(fill = residuos), color =NA) +scale_fill_distiller(palette ="RdBu", name ="Resíduos") +labs(title ="A. Mapa dos Resíduos OLS", subtitle ="Padrão visível (não aleatório)") +annotation_scale(location ="bl", width_hint =0.3, bar_cols =c("black", "white"), text_family ="sans" ) +annotation_north_arrow(location ="tl", which_north ="true", pad_x =unit(0.2, "in"), pad_y =unit(0.2, "in"), style = north_arrow_fancy_orienteering )+theme_void()#mg_dados$residuos_z <-scale(mg_dados$residuos)mg_dados$lag_residuos <-lag.listw(lw, mg_dados$residuos_z)p2 <-ggplot(mg_dados, aes(x = residuos_z, y = lag_residuos)) +geom_point(alpha =0.4) +geom_smooth(method ="lm", se =FALSE, color ="red") +geom_hline(yintercept =0, linetype="dashed") +geom_vline(xintercept =0, linetype="dashed") +labs(title ="B. Moran dos Resíduos",subtitle =paste("I de Moran =", round(moran_residuos$statistic, 3)),x ="Resíduos (Z)", y ="Lag Espacial dos Resíduos") +theme_bw()p1 + p2
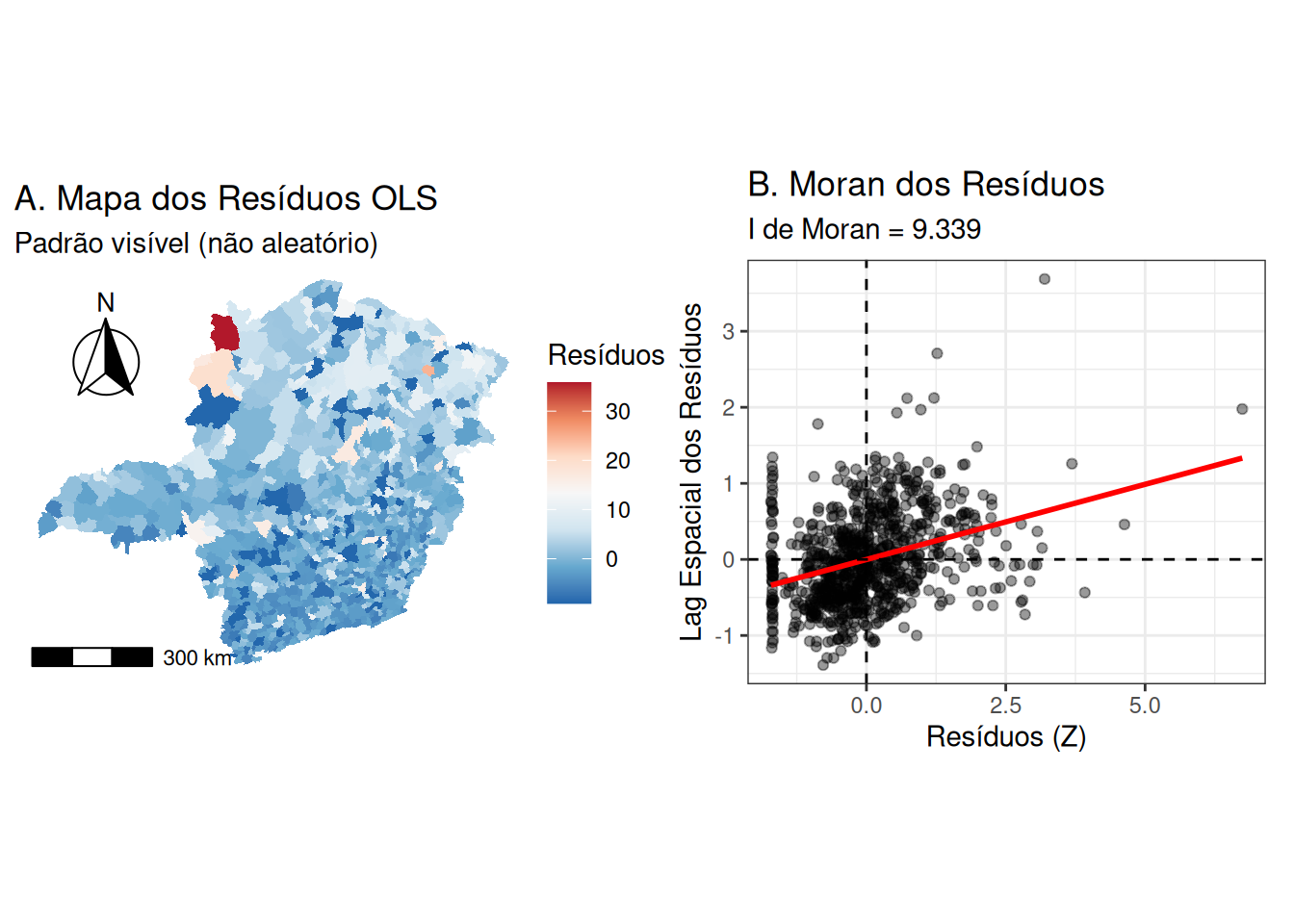
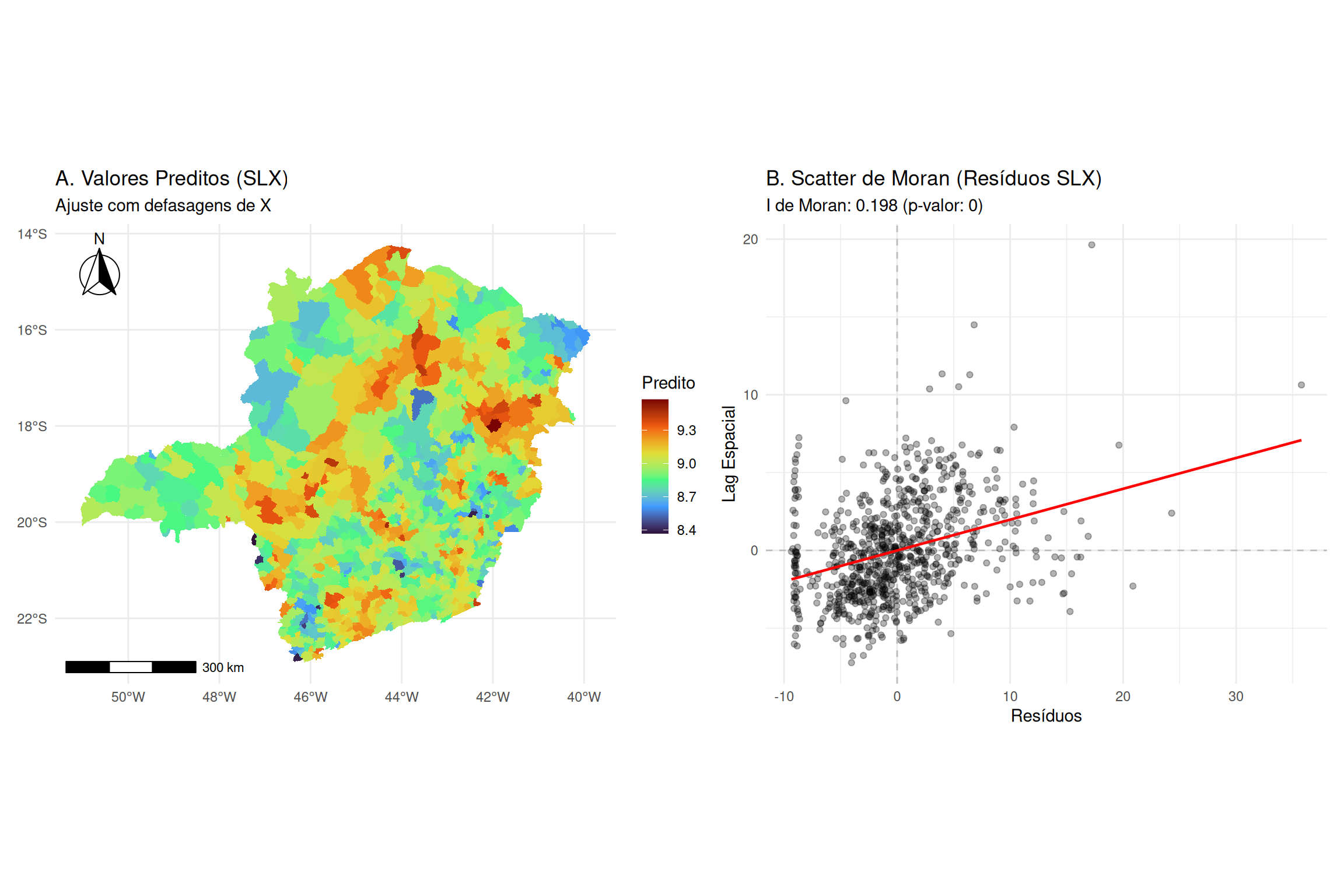
Figure 10: Diagnóstico de Resíduos: (A) Mapa dos Resíduos e (B) Diagrama de Moran dos Resíduos.
Interpretação
A análise dos resíduos do modelo de regressão linear clássico aponta para a violação do pressuposto de independência dos resíduos. A estatística I de Moran observada nos resíduos foi de aproximadamente 0,198, um valor substancialmente superior à esperança matemática sob aleatoriedade (-0,001). A magnitude dessa dependência é confirmada pelo desvio padrão padronizado de 9,34, resultando em um valor-p baixo (< 2.2e-16), o que nos leva a rejeitar a hipótese nula de ausência de autocorrelação espacial com alto grau de confiança.
Visualmente, essa dependência é observada na Figure 10. Figure 10 A), a distribuição espacial dos resíduos não se assemelha a um ruído branco aleatório; ao contrário, observam-se nítidos aglomerados de resíduos positivos (em vermelho) e negativos (em azul), indicando que o modelo subestima ou superestima sistematicamente os valores em regiões vizinhas. Figure 10 B) reforça esse diagnóstico através da inclinação positiva da reta de regressão entre os resíduos e sua defasagem espacial. Essa estrutura remanescente nos erros sugere que a variável explicativa aleatória introduzida foi incapaz de capturar o padrão espacial da variável resposta, transferindo essa estrutura não modelada para o termo de erro.
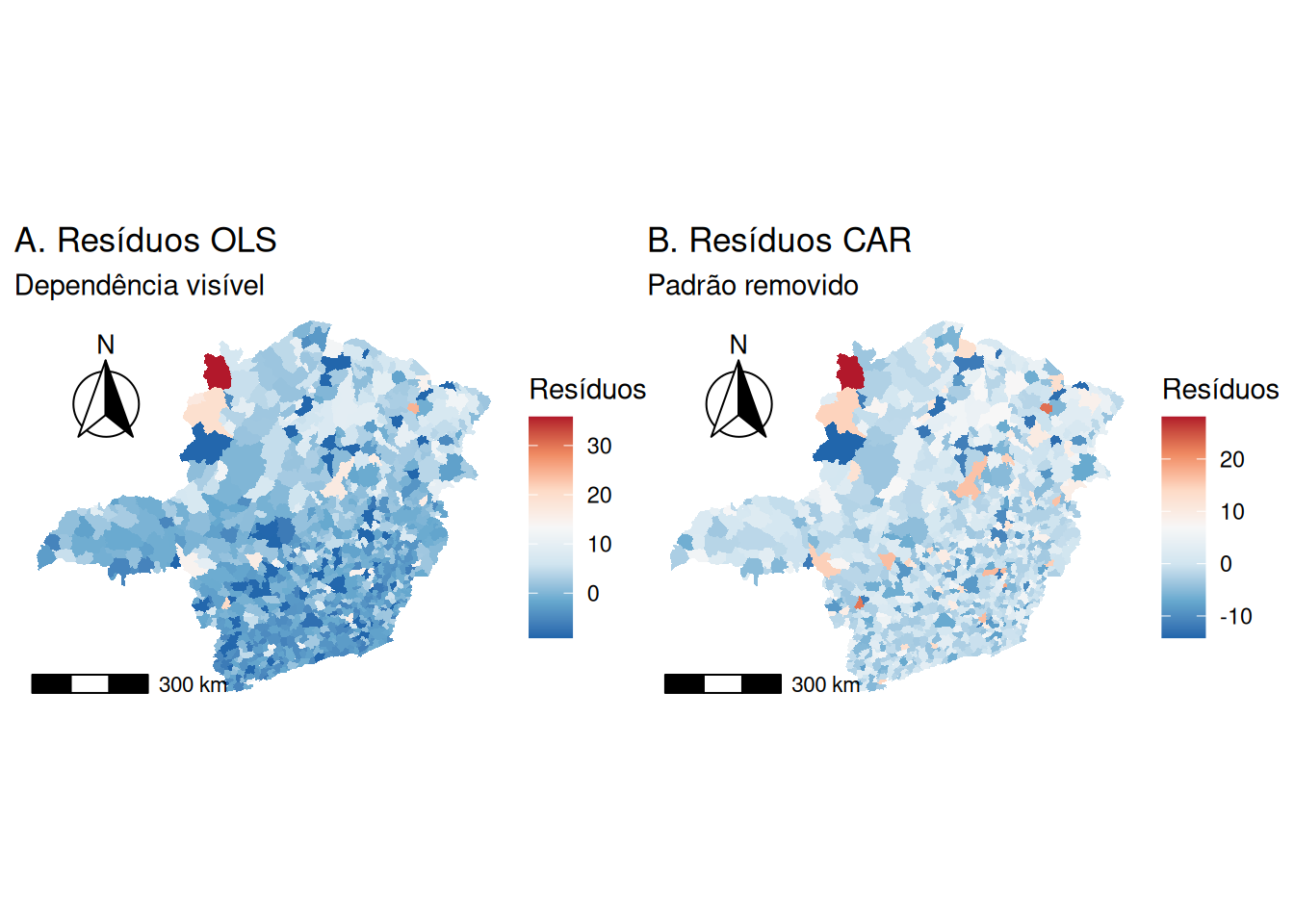
Como próximo passo, é o pesquisador abandonaria o estimador de Mínimos Quadrados Ordinários, cujos testes de significância tornaram-se inválidos, e adotar modelos de regressão espacial que incorporem explicitamente a estrutura de dependência na matriz de covariância ou na média.
Limitações da ESDA
Os valores das estatísticas de Moran ou Geary podem mudar drasticamente com a alteração da escala de agregação ou do desenho das zonas. Um cluster identificado a nível municipal pode desaparecer a nível estadual (MAUP).
O cálculo de estatísticas locais (LISA) envolve a realização de \(n\) testes de hipótese simultâneos. Sem correção (como Bonferroni ou False Discovery Rate), a probabilidade de encontrar clusters falsos positivos (erro Tipo I) aumenta com o tamanho da amostra.
A descoberta de estrutura espacial nos resíduos via ESDA pode levar à inclusão de termos espaciais (CAR/SAR) que competem com as covariáveis fixas pela explicação da variância (colinearidade espacial), enviesando a inferência sobre os efeitos causais.
Unidades na periferia do mapa têm menos vizinhos (efeito da borda), o que distorce o cálculo dos momentos das estatísticas locais e globais, exigindo correções ou simulações de Monte Carlo para inferência válida [@besag1975statistical].
1.6 Fundamentos probabilísticos: GMRF, matrizes de precisão e operadores Laplacianos discretos
Esta seção estabelece a ponte formal entre a teoria dos processos estocásticos contínuos e a implementação computacional eficiente em dados de área, fundamentando-se na estrutura probabilística dos Campos Aleatórios de Markov.
Campos Aleatórios Gaussianos: GRF vs. GMRF
Um campo aleatório Gaussiano (GRF - Gaussian Random Field) é um processo estocástico \(\{Y(\mathbf{s}): \mathbf{s} \in D\}\) tal que, para qualquer conjunto finito de localizações \(\{\mathbf{s}_1, \dots, \mathbf{s}_n\}\), o vetor \((Y(\mathbf{s}_1), \dots, Y(\mathbf{s}_n))^\top\) segue uma distribuição normal multivariada [@cressie2022spatial]. A distinção fundamental na modelagem espacial reside em como essa estrutura de dependência é parametrizada:
GRF Padrão (Geoestatística): Especificado por sua função de média \(\mu(\mathbf{s})\) e sua função de covariância \(C(\mathbf{s}_i, \mathbf{s}_j) = \text{Cov}(Y(\mathbf{s}_i), Y(\mathbf{s}_j))\). Isto gera uma matriz de covariância \(\mathbf{\Sigma}\) densa, onde cada par de locais possui uma correlação teoricamente não nula, definida por uma função de decaimento (ex.: exponencial, Matérn). O custo computacional para inferência (como cálculo da verossimilhança) é \(\mathcal{O}(n^3)\) devido à necessidade de fatorar uma matriz \(n \times n\) densa.
Campo aleatório de Markov Gaussiano (GMRF): É um GRF definido sobre um domínio discreto \(D^L\) (um grafo ou lattice), especificado diretamente pela sua matriz de precisão \(\mathbf{Q} = \mathbf{\Sigma}^{-1}\). A propriedade que define um GMRF é a independência condicional espacial [@RueHeld2005; @rue2009approximate]:
\[
Y_i \perp Y_j \mid \mathbf{Y}_{-ij} \iff Q_{ij} = 0 \quad \text{para} \quad i \neq j.
\]
Ou seja, dadas as observações de todos os outros locais, \(Y_i\) e \(Y_j\) são independentes se e somente se não forem vizinhos no grafo (ou se a estrutura de dependência direta for modelada como nula). Esta é a formalização probabilística da propriedade de Markov: o valor em um local depende apenas dos valores em seus vizinhos diretos.
Propriedade de Markov em grafos e esparsidade da matriz de precisão
A propriedade de Markov espacial formaliza a noção intuitiva de vizinhança. Seja \(\mathcal{G} = (\mathcal{V}, \mathcal{E})\) o grafo que representa o domínio espacial discreto, onde \(\mathcal{V}=\{1, \dots, n\}\) são os vértices (unidades de área) e \(\mathcal{E}\) são as arestas que definem vizinhanças. Um vetor aleatório \(\mathbf{Y} = (Y_1, \dots, Y_n)^\top\) é um GMRF em relação a \(\mathcal{G}\) se:
onde \(\partial i = \{j: (i, j) \in \mathcal{E}\}\) é o conjunto de vizinhos de \(i\). Esta propriedade local é equivalente à esparsidade da matriz de precisão \(\mathbf{Q}\): \(Q_{ij} = 0\) para todo par \((i, j)\) tal que \(j \notin \partial i\) e \(j \neq i\).
Exemplo: Considere 5 regiões onde cada região é vizinha apenas da anterior e da seguinte (assumindo que as regiões estão em fila única). A matriz de precisão teria a forma:
onde * denota um elemento não nulo. Para dados de área bidimensionais com vizinhança por contiguidade, cada região tem tipicamente entre 4 e 8 vizinhos, resultando em uma matriz \(\mathbf{Q}\) com \(\mathcal{O}(n)\) elementos não nulos, em contraste com os \(\mathcal{O}(n^2)\) de uma matriz densa. Esta esparsidade permite o uso de algoritmos numéricos de álgebra linear esparsa (como a fatoração de Cholesky esparsa), reduzindo o custo computacional da inferência de \(\mathcal{O}(n^3)\) para aproximadamente \(\mathcal{O}(n^{3/2})\) em domínios 2D, viabilizando métodos como a inferência Bayesiana aproximada via INLA[@rue2009approximate].
O Laplaciano do grafo
A estrutura da matriz de precisão \(\mathbf{Q}\) em modelos espaciais está intrinsecamente ligada ao conceito de Laplaciano discreto. O operador Laplaciano contínuo \(\nabla^2\) mede a divergência do gradiente, ou a curvatura local de uma função. Num grafo, seu análogo mede a diferença entre o valor num nó e a média dos valores dos seus vizinhos, atuando como um quantificador de suavidade ou rugosidade local do campo.
A matriz Laplaciana \(\mathbf{L}\) de um grafo não direcionado é definida como \(\mathbf{L} = \mathbf{D} - \mathbf{W},\) onde \(\mathbf{W}=[w_{ij}]_{n \times n}\) é a matriz de adjacência/vizinhança (com \(w_{ij}=1\) se \(i\) e \(j\) são vizinhos) e \(\mathbf{D}\) é a matriz diagonal dos graus (com \(D_{ii} = \sum_j w_{ij}\), o número de vizinhos de \(i\)). Para um vetor \(\mathbf{y} = (y_1, \dots, y_n)^\top\), a forma quadrática associada ao Laplaciano é:
Esta equação demonstra que \(\mathbf{y}^\top \mathbf{L} \mathbf{y}\) é uma soma de diferenças quadráticas entre todos os pares de vizinhos. Um valor baixo indica que \(\mathbf{y}\) é suave sobre o grafo (vizinhos têm valores similares), enquanto um valor alto indica um campo rugoso ou heterogêneo.
Propriedades espectrais e singularidade
As propriedades espectrais (autovalores e autovetores) de \(\mathbf{L}\) revelam características fundamentais da conectividade do sistema.
\(\mathbf{L}\) é sempre semidefinida positiva, ou seja, \(\mathbf{y}^\top \mathbf{L} \mathbf{y} \geq 0\) para todo \(\mathbf{y}\).
O menor autovalor de \(\mathbf{L}\) é sempre \(\lambda_1 = 0\), e seu autovetor correspondente é o vetor constante \(\mathbf{1} = (1, \dots, 1)^\top\). Isto decorre diretamente do fato de que \(\mathbf{L}\mathbf{1} = \mathbf{0}\) (a soma de cada linha é zero).
A existência do autovalor zero implica que \(\mathbf{L}\) é uma matriz singular (não invertível). Estatisticamente, isso significa que uma distribuição com matriz de precisão proporcional a \(\mathbf{L}\), como \(\mathbf{Y} \sim \mathcal{N}(\mathbf{0}, \mathbf{L}^-)\) (onde \(\mathbf{L}^-\) denota uma inversa generalizada), é imprópria. Ela define uma densidade de probabilidade válida apenas no subespaço ortogonal ao vetor constante (ou seja, para contrastes entre os \(y_i\)), pois a variância na direção do nível médio global é infinita.
1.7 Modelos mais comuns em dados de área: CAR, ICAR, SAR e BYM
A modelagem de dados de área (ou lattice data) fundamenta-se na incorporação explícita da estrutura de vizinhança definida pela matriz de pesos espaciais \(\mathbf{W}=[w_{ij}]_{n \times n}\) (ver Section 1.1) no mecanismo gerador de dados. A literatura distingue duas formas canônicas de especificar esta dependência: a especificação condicional (CAR), que modela a distribuição de uma área dados os seus vizinhos, e a especificação simultânea (SAR), que modela o sistema de equações de feedback instantâneo entre todas as áreas [@cressie1993statistics].
1.7.1 Modelo Condicional Autorregressivo (CAR)
Introduzido por @besag1974spatial, o modelo autorregressivo condicional (CAR - Conditional Autoregressive) especifica cada observação \(Y_i\) como uma função linear dos valores de seus vizinhos mais um termo de erro independente, mas a inferência é baseada na distribuição condicional.
Seja \(Y_i\) a variável aleatória na unidade \(i\) e \(\mathbf{Y}_{-i} = \{Y_j : j \neq i\}\) o conjunto de todas as outras observações excluindo \(i\). O modelo CAR é definido por uma família de distribuições condicionais Gaussianas:
onde \(\mu_i\) é uma tendência determinística (tendência, geralmente \(\mathbf{x}_i^\top \boldsymbol{\beta}\)); \(w_{ij}\) são os pesos espaciais normalizados, com \(w_{ij} \neq 0\) apenas se \(j\) é vizinho de \(i\) e, \(\epsilon_i \sim \mathcal{N}(0, \sigma_i^2)\) são erros independentes.
Aqui, o valor esperado em \(i\), condicional aos seus vizinhos, é a média global ajustada por uma média ponderada dos desvios dos seus vizinhos em relação à média global.
A partir Equation 2, deriva-se a distribuição condicional que caracteriza o CAR:
Para que estas condicionais definam uma distribuição conjunta válida \(\mathbf{Y} \sim \mathcal{N}(\boldsymbol{\mu}, \mathbf{\sigma})\), o Teorema de Hammersley-Clifford impõe condições de simetria. @besag1974spatial mostrou que a matriz de precisão conjunta \(\Sigma^-1=\mathbf{Q} = [Q_{ij}]_{n \times n}\) deve ser simétrica e positiva definida. A distribuição conjunta é dada por:
Aqui, \(\Sigma= \mathbf{M}(\mathbf{I} - \rho \mathbf{W})^{-1}\), \(\mathbf{M}_{n \times n} =\text{diag}(\sigma_1^2, \dots, \sigma_n^2), \: \boldsymbol{\mu} = [\mu_1, \mu_2, \ldots, \mu_n]^\top\) e \(\rho\) parâmetro espacial desconhecido. Para garantir a simetria de \(\mathbf{Q}_{CAR}\), é necessário que \(\frac{w_{ij}}{\sigma_i^2} = \frac{w_{ji}}{\sigma_j^2}\). Note ainda que \(w_{ii}=0, \, Q_{ii} = 1/\sigma_i^2 >0, \: Q_{ij}= -\rho w_{ij}/\sigma_i^2\: i \neq j\). Lembre-se que quando \(w_{ij} \neq 0\), pode-se escrever \(i \sim j\)[@BesagKooperberg1995]. Note que sem perda de generalidade, em várias literaturas tem se assumido que \(\mu=\mu_i=\mu_j=0\), removendo o efeito da tendência global.
Code
if (!require("pacman")) install.packages("pacman")pacman::p_load(spatialreg, spdep, modelsummary,knitr, kableExtra, texreg,ggplot2, patchwork, sf)#Preparação dos Dadosif (!exists("mg_dados")) { mg_dados <- geobr::read_municipality(code_muni ="MG", year =2020, showProgress =FALSE) coords <-st_coordinates(st_centroid(mg_dados))set.seed(123) mg_dados$taxa_bruta <- (-coords[,2] *10) +rnorm(nrow(mg_dados), 0, 5) mg_dados$variavel_x <-rnorm(nrow(mg_dados))}# Matriz de Pesos Espaciaisnb <-poly2nb(mg_dados, queen =TRUE)lw <-nb2listw(nb, style ="W", zero.policy =TRUE)#Ajuste dos Modelos# Regressão linear classica mod_ols <-lm(taxa_bruta ~ variavel_x, data = mg_dados)# Modelo CAR (Incorpora dependência espacial condicional)# family = "CAR" ajusta via Máxima Verossimilhançamod_car <-spautolm(taxa_bruta ~ variavel_x, data = mg_dados, listw = lw, family ="CAR")# Função auxiliar para formatar valorformat_coef <-function(est, se, pval) { stars <-case_when(pval <0.001~"***", pval <0.01~"**", pval <0.05~"*", TRUE~"")paste0(format(round(est, 3), nsmall=3), " (", format(round(se, 3), nsmall=3), ")", stars)}sum_ols <-summary(mod_ols)coef_ols <- sum_ols$coefficientsres_ols <-c(format_coef(coef_ols[1,1], coef_ols[1,2], coef_ols[1,4]), # Interceptoformat_coef(coef_ols[2,1], coef_ols[2,2], coef_ols[2,4]), # Variavel X"-", # Lambda (Não existe no OLS)round(AIC(mod_ols), 1) # AIC)sum_car <-summary(mod_car)coef_car <- sum_car$Coef# Lambda (parametro espacial) e seu SElambda_val <- mod_car$lambdalambda_se <- mod_car$lambda.se# Teste Z para o Lambda (aproximado)lambda_p <-2* (1-pnorm(abs(lambda_val / lambda_se)))res_car <-c(format_coef(coef_car[1,1], coef_car[1,2], coef_car[1,4]), # Interceptoformat_coef(coef_car[2,1], coef_car[2,2], coef_car[2,4]), # Variavel Xformat_coef(lambda_val, lambda_se, lambda_p), # Lambdaround(AIC(mod_car), 1) # AIC)#tabela_final <-data.frame(Parametro =c("Intercepto", "Variável X", "Lambda (Espacial)", "AIC"),OLS = res_ols,CAR = res_car)#Gerar Tabela (HTML/LaTeX)kbl(tabela_final, #format = "latex", booktabs =TRUE, align ="lcc", caption =NULL) %>%kable_styling(latex_options =c("HOLD_position"), full_width =FALSE, position ="center") %>%add_header_above(c(" "=1, "Modelos"=2)) %>%footnote(general ="* p<0.05; ** p<0.01; *** p<0.001. Valores em parênteses são erros-padrão.")
Table 1: Comparação entre Mínimos Quadrados Ordinários e Modelo Autorregressivo Condicional (CAR).
Modelos
Parametro
OLS
CAR
Intercepto
8.973 (0.182)***
8.993 (0.325)***
Variável X
0.058 (0.185)
-0.029 (0.172)
Lambda (Espacial)
-
0.733 (0.059)***
AIC
5275
5199
Note:
* p<0.05; ** p<0.01; *** p<0.001. Valores em parênteses são erros-padrão.
Interpretação
A tabela Table 1 de resultados demonstra que o modelo CAR proporcionou uma redução substancial no critério de informação AIC (de 5275 para 5199), indicando um ajuste melhor em relação a regressão linear (OLS). O parâmetro espacial \(\lambda\) (Lambda), estimado em 0,733, foi significativo (\(p < 0,001\)), confirmando que a vizinhança exerce influência determinante no processo, capturando a variabilidade que o modelo linear clássico falhou em explicar. Note-se ainda que a variável explicativa aleatória permaneceu não significativa em ambos os modelos, como esperado, mas o erro-padrão e o intercepto foram ajustados para refletir a incerteza real do sistema.
Code
# Diagnóstico dos Resíduosmg_dados$resid_ols <-residuals(mod_ols)mg_dados$resid_car <-residuals(mod_car)# Teste de Moranmoran_car <-moran.test(mg_dados$resid_car, listw=lw)print(paste("I de Moran (Resíduos CAR):", round(moran_car$estimate[1], 3), "| p-valor:", round(moran_car$p.value, 3)))
[1] "I de Moran (Resíduos CAR): -0.187 | p-valor: 1"
Quanto ao diagnóstico Figure 11, o teste de Moran aplicado aos resíduos do modelo CAR resultou em um índice de -0,187 com um valor-p de 1 (não significativo). Indica a rejeição da hipótese de aglomeração espacial positiva (clusters) nos erros. O valor-p unitário sugere que a forte autocorrelação positiva, anteriormente presente no OLS, foi absorvida pela estrutura condicional do modelo, restando resíduos que, estatisticamente, não apresentam mais o padrão de agrupamento que invalidava a inferência anterior.
1.8 Modelo CAR Intrínseco (ICAR)
Um caso limite do modelo CAR ocorre quando \(\rho \to 1\). Este modelo, denominado CAR Intrínseco , é amplamente utilizado como prior para efeitos aleatórios espaciais [@besag1991bayesian; @held2010conditional; @keefe2018formal; @Keefe2019ObjectiveBayesianICAR].
O modelo Condicional Autorregressivo Intrínseco (Intrinsic Conditional Autoregressive, (ICAR)) é um caso particular e amplamente utilizado do modelo CAR, no qual a matriz de precisão (\(\mathbf{Q}\)) é singular (não é invertível), refletindo uma prior espacial que apenas penaliza diferenças entre vizinhos, sem especificar um nível absoluto para as variáveis. O ICAR pode ser entendido como o limite de um CAR próprio quando o parâmetro de dependência espacial se aproxima da fronteira do espaço paramétrico, resultando em uma matriz de precisão (\(\mathbf{Q}\)) semidefinida positiva com posto \(n-1\)[@BesagKooperberg1995].
Partindo da especificação condicional do CAR dada na Equation 2, o ICAR é definido quando a dependência espacial atinge seu máximo (\(\rho \approx 1\)), com a média condicional de cada área dependendo apenas da média simples de seus vizinhos. Para pesos da matriz de vizinhança (\(w_{ij}=1\) se \(i \sim j\), 0 caso contrário), as distribuições condicionais são:
onde \(\partial i\) denota o conjunto de vizinhos da área \(i\), \(m_i = |\partial i|\) é o número de vizinhos (cardinal de \(\partial i\)), e \(\sigma^2 > 0\) é um parâmetro de escala que controla a suavidade espacial. Nesta formulação, o valor esperado condicional é a média aritmética dos valores nas áreas vizinhas (\(\mathbb{E}[Y_i \mid \mathbf{Y}_{-i}]\)), e a variância condicional (\(\text{Var}[Y_i \mid \mathbf{Y}_{-i}]\)) é inversamente proporcional ao número de vizinhos, refletindo maior incerteza em áreas com menos conexões/vizinhos [@held2010conditional].
A especificação condicional implica uma matriz de precisão conjunta (\(\mathbf{Q}\)) singular (sem inversa), com posto \(n-1\). Seja \(\mathbf{D} = \text{diag}(m_1, \dots, m_n)\) e \(\mathbf{W}=[w_{ij}]_{n \times n}\) a matriz de de vizinhança. A matriz de precisão do ICAR é proporcional a \(\mathbf{Q} = \sigma^{-2} (\mathbf{D} - \mathbf{W})=\tau (\mathbf{D} - \mathbf{W})\), que é semidefinida positiva, com um autovalor zero correspondente ao autovetor \(\mathbf{1}\) (vetor de uns). Consequentemente, a densidade conjunta é imprópria e pode ser escrita (a menos de uma constante) como:
onde a soma percorre todos os pares de áreas adjacentes. Esta forma é conhecida como pairwise difference prior e destaca que a densidade só depende dos contrastes locais entre vizinhos, sendo invariante à adição de uma constante global [@BesagKooperberg1995; @held2010conditional].
Para obter uma distribuição própria e identificável, é comum impor uma restrição de soma-zero, \(\sum_{i=1}^n Y_i = 0\). Esta restrição pode ser aplicada formalmente projetando o vetor de efeitos espaciais no subespaço ortogonal a \(\mathbf{1}\), resultando em uma distribuição Gaussiana singular própria com matriz de covariância proporcional à pseudoinversa de Moore-Penrose de \(\mathbf{Q}_{ICAR}\)[@KeefeFerreiraFranck2018]. Em modelos hierárquicos Bayesianos, esta restrição é frequentemente implementada durante a amostragem MCMC, mas a formalização via projeção assegura unicidade e propriedades matemáticas bem definidas.
O ICAR é extensivamente utilizado como componente espacial estruturado em modelos hierárquicos, como no modelo Besag-York-Mollié (BYM) ( Section 1.10) [@besag1991bayesian], que combina um efeito ICAR para variação espacial suave e um efeito aleatório independente para variação não estruturada. @KeefeFerreiraFranck2019 derivaram priors de referência objetivas para modelos com componentes ICAR, facilitando análise Bayesiana automática sem a necessidade de especificação subjetiva de hiperparâmetros.
Code
if (!require("pacman")) install.packages("pacman")# CARBayes é o pacote padrão para modelagem Bayesiana de áreas no CRANpacman::p_load(CARBayes, spdep, sf, ggplot2, patchwork, coda, gt)if (!exists("mg_dados")) { mg_dados <- geobr::read_municipality(code_muni ="MG", year =2020, showProgress =FALSE) coords <-st_coordinates(st_centroid(mg_dados))set.seed(123) mg_dados$taxa_bruta <- (-coords[,2] *10) +rnorm(nrow(mg_dados), 0, 5) mg_dados$variavel_x <-rnorm(nrow(mg_dados))}#Matriz de Vizinhança Binária (W)# O pacote CARBayes exige uma matriz binária (0 e 1), não normalizada.nb <-poly2nb(mg_dados, queen =TRUE)W_binaria <-nb2mat(nb, style ="B", zero.policy =TRUE)#Ajuste do Modelo ICAR (Bayesiano)set.seed(123)modelo_icar <-S.CARleroux(formula = taxa_bruta ~ variavel_x, data = mg_dados, family ="gaussian", #terias que ver a distr dos seus dados para decidir aquiW = W_binaria, burnin =2000, # Descarta as primeiras 2000 iterações (aquecimento)n.sample =10000, # Total de amostras MCMCthin =10, # Salva a cada 10 para reduzir autocorrelaçãorho =1, # RHO = 1 define o ICARverbose =FALSE)#Extrair os resultados# O objeto mod_icar$summary.results contém médias e quantissumm <-as.data.frame(modelo_icar$summary.results)params_interesse <-c("(Intercept)", "variavel_x", "tau2", "nu2")summ_filt <- summ[rownames(summ) %in% params_interesse, ]# Função para formatar: "Média [IC 2.5%; IC 97.5%]"format_bayes <-function(mean, lower, upper) {paste0(format(round(mean, 3), nsmall=3), " [", format(round(lower, 3), nsmall=3), "; ", format(round(upper, 3), nsmall=3), "]")}tabela_icar <-data.frame(Parametro =rownames(summ_filt),Estimativa =mapply(format_bayes, summ_filt$Mean, summ_filt$`2.5%`, summ_filt$`97.5%`))# Renomearis_html_output <- knitr::is_html_output()label_tau2 <-if(is_html_output) "τ<sup>2</sup>"else"$\\tau^2$"label_nu2 <-if(is_html_output) "ν<sup>2</sup>"else"$\\nu^2$"tabela_icar$Parametro <-recode( tabela_icar$Parametro,"(Intercept)"="Intercepto","variavel_x"="Variável X","tau2"=paste("Variância Espacial", label_tau2),"nu2"=paste("Variância do Erro", label_nu2))kbl(tabela_icar, #format = "latex",booktabs =TRUE, align ="lc", caption =NULL, escape =FALSE) %>%kable_styling(latex_options =c("HOLD_position", "striped"), full_width =FALSE, position ="center") %>%footnote(general ="Estimativas: Média a posteriori [IC 95%].")
Table 2: Modelo ICAR Bayesiano: Estimativas a posteriori (MCMC).
Parametro
Estimativa
Intercepto
8.975 [8.657; 9.285]
Variável X
-0.001 [-0.332; 0.353]
Variância do Erro ν2
21.944 [19.461; 24.745]
Variância Espacial τ2
5.672 [3.028; 9.547]
Note:
Estimativas: Média a posteriori [IC 95%].
Interpretação
O intercepto do modelo foi estimado em 8,975 (Table 2) e é significativo uma vez que seu intervalo de pois o intervalo credibilidade de 95% (entre 8,657 e 9,285) encontra-se inteiramente acima de zero (não inclui zero). Em contrapartida, a covariável aleatória (“Variável X”) não demonstrou qualquer influência explicativa sobre a taxa, apresentando uma estimativa pontual quase nula (-0,001) e um intervalo de credibilidade que inclui zero, o que confirma sua irrelevância para o fenômeno analisado.
A variância do erro não estruturado (\(\nu^2\)) foi estimada em 21,944, indicando uma presença de ruído nos dados brutos, enquanto a variância espacial (\(\tau^2\)), estimada em 5,672 com um intervalo de credibilidade estritamente positivo (3,028 a 9,547), confirma que há um componente de vizinhança.
Code
# O modelo estima um efeito aleatório (phi) para cada município.mg_dados$efeito_icar <-apply(modelo_icar$samples$phi, 2, mean)#ggplot(mg_dados) +geom_sf(aes(fill = efeito_icar), color =NA) +scale_fill_distiller(palette ="RdBu", name =expression("Efeito Espacial"~Phi)) +labs(title ="Componente Espacial ICAR", subtitle ="Padrão latente recuperado (Suavizado)") +theme_void() +theme(plot.title =element_text(face ="bold"))+annotation_scale(location ="bl", width_hint =0.3, bar_cols =c("black", "white"), text_family ="sans" ) +annotation_north_arrow(location ="tl", which_north ="true", pad_x =unit(0.2, "in"), pad_y =unit(0.2, "in"), style = north_arrow_fancy_orienteering )
Figure 12: Componente espacial do modelo ICAR ajustado
A visualização deste efeito espacial (\(\phi\)) Figure 12, no mapa recupera o gradiente norte-sul latente, isolando-o efetivamente da variabilidade aleatória capturada pelo termo de erro.
NoneSaiba mais
Acesse ao link 1 e link 2 e veja outras formas de de ajuste do mesmo modelo.
1.9 Modelos Simultâneos Autorregressivos (SAR)
O modelo Autorregressivo Simultâneo (SAR - Simultaneous Autoregressive), introduzido por @whittle1954stationary, tem raízes na análise de séries temporais e é predominante na econometria espacial [@anselin1988spatial].
Ao contrário do CAR (Section 1.7.1), o SAR modela a dependência através de um sistema de equações simultâneas onde a variável \(Y_i\) é função direta dos seus valores contemporâneos \(Y_j\) e de um termo de erro:
Aqui, \(\rho \sum w_{ij} Y_j\) é o termo de defasagem espacial (spatial lag). Existe um efeito de feedback global: um choque em \(\epsilon_i\) afeta \(Y_i\), que afeta os vizinhos \(Y_j\), que por sua vez afetam de volta \(Y_i\) e se propagam por todo o sistema.
@ver2018relationship e @wall2004close destacam as diferenças fundamentais na estrutura de covariância:
A matriz de precisão do SAR é \(\mathbf{Q}_{SAR} = \sigma^{-2}(\mathbf{I} - \rho \mathbf{W})^\top (\mathbf{I} - \rho \mathbf{W})\). Note o produto cruzado das matrizes. Isso implica que a correlação no SAR decai mais lentamente com a distância do grafo do que no CAR.
O parâmetro \(\rho\) no SAR tem uma interpretação de spillover global (efeito multiplicador), enquanto no CAR é uma medida de correlação condicional local.
Note
Outras especificações dos modelos SAR e CAR são discutidas no capítulo 4 do livro @scalon2024analise.
Consulte o capítulo 4 do livro @scalon2024analise para conhecer todos os procedimentos a seguir antes do ajuste do modelo, desde a análise exploratória até o ajuste propriamente dito.
A descrição completa dos pacotes spdep e spatialreg encontra-se no capítulo 4 do livro @scalon2024analise.
1.10 O Modelo BYM (Besag-York-Mollié) e sua reparametrização (BYM2)
Até este ponto, vimos os modelos CAR, SAR e ICAR que consideram que a variável de interesse \(\mathbf{Y}\) segue, condicional aos parâmetros, uma distribuição Normal multivariada. Contudo, em epidemiologia, demografia e ciências sociais, é comum lidar com dados de contagem \(y_i\) observados em uma região \(i\), as quais são comumente modeladas como variáveis aleatórias seguindo uma distribuição de Poisson:
Nessa formulação, \(E_i\) representa o número esperado de casos, ajustado por características populacionais, enquanto \(\theta_i\) denota o risco relativo verdadeiro ( ver Section 1.4). Como os dados são de contagem, é imperativo que a média (número esperado) do processo seja positiva. No entanto, se utilizássemos um modelo linear direto para o risco, poderíamos incorrer no erro de estimar valores negativos, uma vez que, na distribuição Normal, o suporte do parâmetro de média compreende todos os números reais. É importante enfatizar que o foco da modelagem estatística reside na estrutura da média, embora existam extensões importantes como os modelos lineares generalizados (GLM) duplos, que modelam a média e a variância [ver @Paula2013DiagnosticsDGLM], ou os modelos GAMLSS, que permitem modelar simultaneamente a média, a variância, a curtose e a assimetria [ver @Stasinopoulos2017GAMLSS; @Rigby2019DistributionsGAMLSS; @Stasinopoulos2024GAMLSS].
Para resolver o problema da restrição de positividade, não se aplica uma transformação diretamente à variável resposta, como se faria em modelos de regressão clássicos para estabilização de variância, mas sim uma função de ligação ao valor esperado do processo. Essa é a essência dos Modelos Lineares Generalizados (GLM). No caso da distribuição Poisson, a função de ligação canônica é o logaritmo natural (ver outras funções em [@Paula2025ModelosRegressao]), o que nos permite definir o preditor linear \(\eta_i = \log(\theta_i)\). Esse preditor é então modelado através de uma estrutura aditiva que incorpora o intercepto \(\mu\), o efeito das covariáveis \(\mathbf{x}_i^\top \boldsymbol{\beta}\) e um termo de efeito aleatório espacial \(\varepsilon_i\), resultando na expressão:
Proposto por @besag1991bayesian, o modelo Besag-York-Mollié (BYM) decompõe o efeito aleatório espacial \(\varepsilon_i\) em dois componentes aditivos [@riebler2016intuitive]:
\[
\varepsilon_i = u_i + v_i
\]
onde:
\(u_i\) é componente estrutural que modela a dependência espacial. Assume-se uma prior ICAR (ver seção sobre Section 1.8.1), onde a distribuição condicional de \(u_i\) depende apenas dos vizinhos \(\partial i\):
A distribuição conjunta é imprópria e dada por \(\mathbf{u} \sim \mathcal{N}(\mathbf{0}, \tau_u^{-1}\mathbf{Q}^-)\), onde \(\mathbf{Q}\) é a matriz de estrutura definida pela vizinhança (\(Q_{ii} = m_i\) e \(Q_{ij} = -1\) se \(i \sim j\)) e \(\mathbf{Q}^-\) denota a sua inversa generalizada. \(\tau_u\) é a precisão (inverso da variância) deste componente.
\(v_i\) é componente não estrutural que modela o ruído aleatório independente (heterogeneidade pura). Assume-se normalidade i.i.d.:
Apesar de sua ampla utilização no mapeamento de doenças, @riebler2016intuitive identificaram limitações nesta parametrização que afetam a inferência:
Identificabilidade: Apenas a soma \(\varepsilon_i = u_i + v_i\) é identificável. A separação entre \(u\) e \(v\) depende inteiramente das distribuições a priori, e os hiperparâmetros \(\tau_u\) e \(\tau_v\) competem pela explicação da variância total. Lembre-se que um parâmetro \(\boldsymbol{\theta}\) é considerado identificável se valores distintos do parâmetro implicam necessariamente em distribuições de probabilidade distintas para os dados observados (formalmente, se \(P_{\boldsymbol{\theta}_1} = P_{\boldsymbol{\theta}_2} \implies \boldsymbol{\theta}_1 = \boldsymbol{\theta}_2\)). No modelo BYM, infinitas combinações dos componentes \(u_i\) e \(v_i\) podem resultar no mesmo valor latente \(\varepsilon_i\) e, por consequência, na mesma função de verossimilhança.
Escalonamento (Scaling): A variância marginal do componente espacial \((\mathbf{Q}^-)_{ii}\) não é constante e depende da geometria do grafo (matriz) de vizinhança. Em grafos mais conectados (regiões com muitos vizinhos), a variância marginal induzida por um mesmo \(\tau_u\) é menor do que em grafos menos conectados (regiões com poucos vizinhos). Isso torna as priors para \(\tau_u\) não transferíveis: uma prior que é vagamente informativa para um mapa pode ser fortemente informativa para outro, impedindo a criação de padrões de referência [@sorbye2014scaling].
Exemplo: Imagine que você ajusta um modelo espacial para os municípios de do estado de São Paulo (muitos vizinhos, malha densa) e outro para os municípios do estado do Amazonas (áreas enormes, poucos vizinhos). Se você usar a mesma prior para a precisão \(\tau\) (ex: \(\tau=1\)) em ambos os mapas, no mapa denso, a variância induzida será pequena enquanto no mapa esparso, a variância induzida será grande. Isso significa que a prior não é transferível, ou seja, o significado de \(\tau\) muda dependendo do mapa que você está usando.
1.10.2 Modelo BYM2
Para solucionar os problemas de escalonamento e confundimento de parâmetros, @riebler2016intuitive propuseram o modelo BYM2. A inovação consiste em escalonar a matriz de precisão espacial e reparametrizar o modelo em termos de variância total e proporção de variância espacial.
Primeiramente, define-se uma matriz de estrutura escalonada \(\mathbf{Q}_*\). O escalonamento é realizado de tal forma que a média geométrica das variâncias marginais generalizadas do componente espacial seja igual a 1:
Esta operação normaliza o tamanho médio do efeito espacial, tornando-o comparável ao efeito não estruturado (cuja variância é 1 na escala padronizada). Com a matriz \(\mathbf{Q}_*\) normalizada, o vetor de efeitos aleatórios \(\boldsymbol{\varepsilon} = (\varepsilon_1, \dots, \varepsilon_n)^\top\) é reescrito como:
onde \(\mathbf{v} \sim \mathcal{N}(\mathbf{0}, \mathbf{I})\) é o componente não estruturado padronizado; \(\mathbf{u}_* \sim \mathcal{N}(\mathbf{0}, \mathbf{Q}_*^-)\) é o componente estruturado escalonado; \(\tau > 0\) é o parâmetro de precisão marginal total e, \(\phi \in [0, 1]\) é o parâmetro de mistura.
A matriz de covariância do vetor \(\boldsymbol{\varepsilon}\) no modelo BYM2 torna-se:
Esta formulação desacopla a magnitude da variabilidade da estrutura de dependência, facilitando a interpretação. Assim, \(\tau\) controla a variância marginal total do efeito latente. \(\sigma = \tau^{-1/2}\) é o desvio padrão marginal de \(\varepsilon\), sendo invariante à estrutura do grafo (região com muitos ou poucos vizinhos), enquanto \(\phi\) representa a proporção da variância total que é explicada pela estrutura espacial.
Note que se \(\phi=1\), temos um modelo puramente ICAR; se \(\phi=0\), um modelo puramente i.i.d.
Esta parametrização permite o uso de PC Priors (Penalised Complexity Priors, [@sorbye2017penalised; @simpson2017penalising]), onde o pesquisador pode expressar conhecimento a priori de forma intuitiva (ex: acredito que a probabilidade do efeito espacial ser superior a 0.5 é baixa).
1.11 Priors de Penalização de Complexidade (PC Priors)
A especificação de distribuições a priori para parâmetros de variância e correlação em modelos hierárquicos Bayesianos constitui, historicamente, um desafio. As escolhas tradicionais, notadamente a família de distribuições Gama-Inversa (\(\epsilon, \epsilon\)) para a variância \(\sigma^2\) (ou Gama para a precisão) com parâmetros vagos (por exemplo, \(\epsilon = 0.001\)), foram severamente criticadas por @gelman2006prior. Gelman demonstra que, embora matematicamente convenientes devido à conjugação condicional, tais distribuições são inadequadas como referência não informativa. O autor argumenta que a família Gama-Inversa é patológica no limite \(\epsilon \to 0\), pois não converge para uma distribuição a posteriori própria em situações onde a verossimilhança permite variância nula. Consequentemente, a inferência torna-se instável e altamente sensível à escolha arbitrária do hiperparâmetro \(\epsilon\), especialmente em conjuntos de dados com um número pequeno de grupos ou quando a variância dos efeitos aleatórios é pequena. Na prática, a prior Gama-Inversa introduz um viés que empurra a massa da posteriori para longe da origem, distorcendo a inferência ao sugerir uma variabilidade entre grupos maior do que a suportada pelos dados. @gelman2006prior recomenda, em vez disso, o uso de prioris Uniformes ou da família Half-t (como a Half-Cauchy) para o desvio padrão \(\sigma\), que possuem melhor comportamento na origem e nas caudas.
Em resposta a essas e várias outras limitações, @simpson2017penalising propuseram uma estrutura unificada para a construção de distribuições a priori denominadas Priors de Penalização de Complexidade (PC Priors).
A construção das PC Priors fundamenta-se em quatro princípios. O primeiro princípio, o princípio da parcimônia, estabelece a existência de um modelo base (denotado por \(g\)) que é uma versão simplificada do modelo flexível (denotado por \(f\)). A prior deve ser construída de modo a favorecer o modelo base, penalizando o afastamento deste a menos que os dados forneçam evidência robusta para justificar a complexidade adicional. O segundo princípio define uma medida de complexidade baseada na Divergência de Kullback-Leibler (KLD),
que quantifica a perda de informação ao aproximar o modelo flexível pelo modelo base. Para conferir interpretabilidade, essa divergência é transformada em uma distância unidirecional definida como
\[d(\xi) = \sqrt{2 \text{KLD}(f \| g)},\]
onde \(\xi\) é o parâmetro que governa a flexibilidade do modelo.
O terceiro princípio determina a taxa de penalização. @simpson2017penalising argumentam que, na ausência de informações externas que sugiram o contrário, a penalização deve ocorrer a uma taxa constante ao longo da distância métrica \(d\). A única distribuição de probabilidade contínua definida em \([0, \infty)\) que satisfaz a propriedade de falta de memória (taxa de risco constante) é a distribuição exponencial. Portanto, a prior na escala da distância deve ser
\[\pi(d) = \lambda e^{-\lambda d},\]
onde \(\lambda\) é a taxa de decaimento. A distribuição a priori para o parâmetro original \(\xi\) é então obtida através da regra de transformação de variáveis, dada por
O quarto princípio permite a calibração definida pelo usuário. Em vez de escolher o parâmetro \(\lambda\) diretamente, o pesquisador especifica uma regra probabilística intuitiva sobre a cauda da distribuição, da forma
\[\text{Prob}(Q(\xi) > U) = \alpha,\]
onde \(Q(\xi)\) é uma transformação interpretável do parâmetro, \(U\) é um limite superior e \(\alpha\) uma probabilidade pequena.
Exemplo da Aplicação de PC Priors
Considere um pesquisador que analisa a incidência de uma doença infecciosa em \(n\) municípios. Os dados observados são contagens \(y_i\) de casos, modeladas como \(y_i \mid \theta_i \sim \text{Poisson}(E_i \theta_i)\), onde \(E_i\) é o número esperado de casos e \(\theta_i\) o risco relativo. O preditor linear é definido como \(\eta_i = \log(\theta_i) = \mu + \mathbf{x}_i^\top \boldsymbol{\beta} + \varepsilon_i\). O efeito aleatório espacial \(\varepsilon_i\) é modelado utilizando a reparametrização BYM2: \(\varepsilon_i = \tau^{-1/2} \left( \sqrt{1-\phi} \, v_i + \sqrt{\phi} \, u_i^* \right)\), onde \(\tau\) é a precisão marginal total e \(\phi \in [0,1]\) é o parâmetro de mistura. A especificação de distribuições a priori para \(\tau\) e \(\phi\) é crucial. O uso de priors Gama para a precisão, como \(\tau \sim \Gamma(1, 0.01)\), é comum, mas problemático, pois coloca densidade zero em \(\tau \to \infty\) (o modelo base de variância nula), podendo levar a sobreajuste ao não permitir o encolhimento adequado.
A aplicação das PC Priors resolve este problema. O primeiro passo é identificar os modelos base para cada parâmetro (se o objetivo é modelar dependência espacial, o modelo base é aquele que não tem dependência espacial). Para a precisão \(\tau\), o modelo base é a ausência de efeitos aleatórios, correspondente a \(\tau \to \infty\) ou, equivalentemente, ao desvio padrão marginal \(\sigma = \tau^{-1/2} = 0\). Para o parâmetro de mistura \(\phi\), o modelo base é a ausência de dependência espacial, ou seja, \(\phi = 0\). As PC Priors serão construídas para penalizar o afastamento destes modelos base.
Na prática, o pesquisador traduz conhecimento epidemiológico prévio em declarações probabilísticas (isso é prior). Para a precisão \(\tau\), é mais intuitivo pensar na escala do desvio padrão \(\sigma\) (o quão afastados estão os casos de dengue em Lavras em relação média geral de todo estado de Minas Gerais) . Suponha que, com base na literatura, o pesquisador acredite ser improvável que a variação não explicada no log-risco seja extrema. Um desvio padrão de \(\sigma = 0.5\) implica que os riscos relativos (na escala original) variam tipicamente por um fator de até \(e^{0.5} \approx 1.65\) para mais ou para menos. O pesquisador pode considerar que é pouco plausível que a variação não explicada supere este patamar. Assim, formula-se a declaração: \(\text{Prob}(\sigma > 0.5) = 0.01\). Isto significa que se atribui apenas 1% de probabilidade a priori a valores de \(\sigma\) superiores a 0.5.
Esta declaração define os parâmetros da PC Prior: \(U = 0.5\) e \(\alpha = 0.01\). Conforme a derivação de @simpson2017penalising, isso implica uma distribuição exponencial para \(\sigma\) com taxa \(\lambda = -\ln(\alpha)/U = -\ln(0.01)/0.5 \approx 9.21\). A prior correspondente para a precisão \(\tau\) é uma distribuição tipo-2 Gumbel, mas o usuário não precisa manipulá-la diretamente.
Para o parâmetro de mistura \(\phi\), que representa a proporção da variância atribuída à dependência espacial, o raciocínio é similar. O modelo base é \(\phi=0\) (ausência de estrutura espacial). O pesquisador deve refletir sobre a importância relativa esperada da dependência espacial. Em muitas aplicações epidemiológicas, é razoável assumir, na falta de informação forte, que a heterogeneidade não espacial (ruído) pode ser tão ou mais importante que a estrutura espacial. Uma declaração conservadora poderia ser: \(\text{Prob}(\phi > 0.5) = 0.5\). Isto significa que se atribui igual probabilidade (50%) a \(\phi\) estar acima ou abaixo de 0.5, mas ainda assim a prior é construída para encolher em direção a zero.
No pacote R-INLA, a especificação destas PC Priors é direta. Suponha que id_regiao é um vetor de índices que identificam cada município do estado de Minas Gerais, grafo é a matriz de vizinhança, e y é o vetor de contagens. A fórmula do modelo, incorporando as PC Priors com os parâmetros \(U\) e \(\alpha\) definidos acima, seria:
O argumento param = c(U, α) na prior "pc.prec" para a precisão codifica exatamente a declaração \(\text{Prob}(\sigma > U) = \alpha\). Para a prior "pc" no parâmetro phi, param = c(0.5, 0.5) codifica \(\text{Prob}(\phi > 0.5) = 0.5\). A opção scale.model = TRUE garante o escalonamento automático da matriz de precisão do componente estruturado, essencial para a interpretabilidade de \(\phi\).
A prior para \(\sigma\) (derivada de pc.prec) tem seu pico em zero e decai exponencialmente. Assim, se os dados forem escassos ou pouco informativos, a posteriori de \(\sigma\) será puxada para valores próximos de zero, efetivamente encolhendo os efeitos aleatórios \(\varepsilon_i\) e produzindo estimativas de risco mais suaves e próximas da média global. Segundo, a prior para \(\phi\) também encolhe em direção a zero. Portanto, na ausência de um sinal espacial claro nos dados, o modelo tenderá a alocar mais variância ao componente não estruturado (\(v_i\)), evitando a imposição de uma suavização espacial injustificada.
Code
# Instalação do INLA options(timeout =600)if (!requireNamespace("INLA", quietly =TRUE)) {install.packages("INLA", repos=c(getOption("repos"), INLA="https://inla.r-inla-download.org/R/stable"), dep=TRUE)}# Veja como instalar INLA no link: https://www.r-inla.org/download-install# veja também browseVignettes("INLA") ou system.file("doc", package = "INLA") e veja a documentacao# Veja também https://github.com/hrue/r-inla/tree/devel/rinla/vignettesif (!require("pacman")) install.packages("pacman")pacman::p_load(INLA, spdep, sf, dplyr, knitr, kableExtra, ggplot2, patchwork)# Preparação dos Dadosif (!exists("mg_dados")) { mg_dados <- geobr::read_municipality(code_muni ="MG", year =2020, showProgress =FALSE) coords <-st_coordinates(st_centroid(mg_dados))set.seed(123) mg_dados$taxa_bruta <- (-coords[,2] *10) +rnorm(nrow(mg_dados), 0, 5) mg_dados$variavel_x <-rnorm(nrow(mg_dados))}# Criar um identificador numérico sequencial para as áreas (exigência do INLA)mg_dados$ID_AREA <-1:nrow(mg_dados)#Matriz de Vizinhança e Grafonb <-poly2nb(mg_dados, queen =TRUE)plot(st_geometry(mg_dados), border ="lightgrey", main ="Estrutura de Vizinhança (Grafo)")plot(nb, coords, add =TRUE, col ="red", pch =19, cex =0.6, lwd =0.5)
Figure 13: Grafo da matriz tipo Queen
Code
# Converter para formato de grafo do INLAnb2INLA("mg_graph.adj", nb)g <-inla.read.graph("mg_graph.adj")#Definição dos PC Priors (Penalised Complexity)# Prior para a Precisão (Tau): Prob(desvio padrão > 1) = 0.01 , vc pode usar outros#A probabilidade do Desvio Padrão (σ) ser maior que 1 é de apenas 1% (0.01).# Prior para Mistura (Phi): Prob(phi < 0.5) = 0.5 (neutro), note que Phi = 1 (tudo é espacial), Phi=0 (tudo é aleatório).#Você está dizendo ao modelo: "Eu não sei se o fenômeno é mais espacial ou # mais aleatório, então vou deixar 50% de chance para cada lado"hyper_pc <-list(prec =list(prior ="pc.prec", param =c(1, 0.01)),phi =list(prior ="pc", param =c(0.5, 0.5)))#Ajuste do Modelo BYM2formula_bym2 <- taxa_bruta ~ variavel_x +f(ID_AREA, model ="bym2", graph = g, scale.model =TRUE, hyper = hyper_pc)modelo_inla <-inla(formula_bym2, data = mg_dados, family ="gaussian", control.predictor =list(compute =TRUE), control.compute =list(dic =TRUE, waic =TRUE))# Função auxiliar de formatação "Média [IC 95%]"fmt <-function(m, l, u) {paste0(format(round(m, 3), nsmall=3), " [", format(round(l, 3), nsmall=3), "; ", format(round(u, 3), nsmall=3), "]")}# Efeitos Fixosfix <- modelo_inla$summary.fixed[, c("mean", "0.025quant", "0.975quant")]df_fix <-data.frame(Parametro =rownames(fix),Valor =mapply(fmt, fix$mean, fix$`0.025quant`, fix$`0.975quant`))# renomear nomesdf_fix$Parametro <-recode(df_fix$Parametro, "(Intercept)"="Intercepto", "variavel_x"="Variável X")# Hiperparâmetroshyp <- modelo_inla$summary.hyperpar[, c("mean", "0.025quant", "0.975quant")]df_hyp <-data.frame(Parametro =rownames(hyp),Valor =mapply(fmt, hyp$mean, hyp$`0.025quant`, hyp$`0.975quant`))is_html_output <- knitr::is_html_output()label_taU <-if(is_html_output) "τ"else"$\\tau$"label_phI <-if(is_html_output) "φ"else"$\\phi$"df_hyp$Parametro <-recode(df_hyp$Parametro,"Precision for the Gaussian observations"="Precisão (Likelihood)","Precision for ID_AREA"=paste("Precisão Marginal", label_taU),"Phi for ID_AREA"=paste("Dependência Espacial", label_phI))#Métricas de Ajustedf_met <-data.frame(Parametro =c("DIC", "WAIC"),Valor =c(format(round(modelo_inla$dic$dic, 2), nsmall=2),format(round(modelo_inla$waic$waic, 2), nsmall=2)))# Unir tudodf_final <-rbind(df_fix, df_hyp, df_met)# Gerar Tabelakbl(df_final, # format = "latex",booktabs =TRUE, align ="lr", caption =NULL) %>%kable_styling(latex_options =c("HOLD_position"), full_width =FALSE, position ="center") %>%pack_rows("Efeitos Fixos (Média [IC 95%])", 1, nrow(df_fix)) %>%pack_rows("Hiperparâmetros (Média [IC 95%])", nrow(df_fix) +1, nrow(df_fix) +nrow(df_hyp)) %>%pack_rows("Qualidade do Ajuste", nrow(df_final) -1, nrow(df_final)) %>%row_spec((nrow(df_final)-1):nrow(df_final), bold =TRUE)
Table 3: Resultados do Modelo BYM2 com PC Priors.
Parametro
Valor
Efeitos Fixos (Média [IC 95%])
Intercepto
8.974 [8.665; 9.282]
Variável X
-0.001 [-0.330; 0.327]
Hiperparâmetros (Média [IC 95%])
Precisão (Likelihood)
21397.768 [1548.439; 76343.214]
Precisão Marginal τ
0.041 [0.037; 0.045]
Dependência Espacial φ
0.124 [0.069; 0.198]
Qualidade do Ajuste
DIC
-4827.16
WAIC
-5047.62
Interpretação
A análise dos efeitos fixos (Table 3) mostra que o intercepto do modelo foi estimado com uma média de 8,974, situando-se num intervalo de credibilidade de 95% entre 8,664 e 9,283 (não inclui zero). Por outro lado, a covariável “Variável X” apresentou uma estimativa média muito próxima de zero (-0,001) e, mais importante, o seu intervalo de credibilidade varia de -0,331 a 0,328. Como este intervalo inclui o valor zero, conclui-se que não existe evidência estatística de uma associação significativa entre a Variável X e a variável resposta; ou seja, a variável não contribui para explicar o fenômeno estudado neste modelo.
No que nos hiperparâmetros e à estrutura aleatória, a precisão da verossimilhança (Likelihood) é extremamente alta (média de 21117,082), o que indica que a variância do erro residual dos dados em torno da média predita é muito pequena. O parâmetro de dependência espacial (\(\phi\)) foi estimado em 0,124 (com intervalo de 0,068 a 0,200), o que revela que apenas cerca de 12,4% da variabilidade capturada pelo efeito aleatório (campo latente) se deve à estrutura espacial de vizinhança, enquanto a maior parte (os restantes 87,6%) é atribuída a ruído não estruturado (efeito iid). Por fim, os critérios de informação DIC (-4822,46) e WAIC (-5056,00) indicam a qualidade do ajuste, servindo como base de comparação para modelos alternativos, onde valores menores indicariam um melhor ajuste.
Code
# DIAGNÓSTICOmg_dados$efeito_bym <- modelo_inla$summary.random$ID_AREA$mean[1:nrow(mg_dados)]mg_dados$ajustado <- modelo_inla$summary.fitted.values$meanmg_dados$residuos <- mg_dados$taxa_bruta - mg_dados$ajustado#Mapa do Efeito Espacial (Risco/Nível estimado)p1 <-ggplot(mg_dados) +geom_sf(aes(fill = efeito_bym), color =NA) +scale_fill_distiller(palette ="RdBu", name ="Efeito\nEspacial") +labs(title ="A. Componente Espacial (BYM2)") +theme_minimal()+annotation_scale(location ="bl", width_hint =0.3, bar_cols =c("black", "white"), text_family ="sans" ) +annotation_north_arrow(location ="tl", which_north ="true", pad_x =unit(0.2, "in"), pad_y =unit(0.2, "in"), style = north_arrow_fancy_orienteering )# Mapa dos Resíduos p2 <-ggplot(mg_dados) +geom_sf(aes(fill = residuos), color =NA) +scale_fill_distiller(palette ="PuOr", name ="Resíduos") +labs(title ="B. Mapa de Resíduos") +theme_minimal()+annotation_scale(location ="bl", width_hint =0.3, bar_cols =c("black", "white"), text_family ="sans" ) +annotation_north_arrow(location ="tl", which_north ="true", pad_x =unit(0.2, "in"), pad_y =unit(0.2, "in"), style = north_arrow_fancy_orienteering )#Gráfico Observado vs Esperadocor_p <-round(cor(mg_dados$taxa_bruta, mg_dados$ajustado), 3)p3 <-ggplot(mg_dados, aes(x = ajustado, y = taxa_bruta)) +geom_point(alpha =0.3, color ="darkblue") +geom_abline(col ="red", linetype ="dashed") +labs(title ="C. Ajuste do Modelo", subtitle =paste0("Correlação: ", cor_p),x ="Predito (INLA)", y ="Observado") +theme_minimal()(p1 + p2 + p3)# TESTE DE MORAN NOS RESÍDUOSlw <-nb2listw(nb, style ="W")moran_test <-moran.test(mg_dados$residuos, lw)print(moran_test)
Moran I test under randomisation
data: mg_dados$residuos
weights: lw
Moran I statistic standard deviate = -1.4131, p-value = 0.9212
alternative hypothesis: greater
sample estimates:
Moran I statistic Expectation Variance
-0.0312073160 -0.0011737089 0.0004517059
Code
if(moran_test$p.value >0.05) {message("SUCESSO: Resíduos são aleatórios (p > 0.05). O modelo removeu a autocorrelação.")} else {message("ATENÇÃO: Ainda existe dependência espacial nos resíduos.")}
Figure 14: Diagnóstico do modelo BYM2 ajustado
Interpretação
O componente espacial mapeado em Figure 14 (A) delineia a variabilidade latente, capturando a heterogeneidade geográfica do fenômeno. O ajuste é evidenciado na Figure 14 (C), onde a relação entre os valores observados e os preditos pelo INLA exibe uma correlação unitária, com os pontos assentando-se perfeitamente sobre a linha de identidade, indicando ausência de viés sistemático nas predições.
A validade do modelo é confirmada pela análise dos resíduos. O mapa em Figure 14 (B) sugere visualmente uma distribuição espacial aleatória dos erros, sem padrões de aglomeração (clustering) remanescentes. Esta inspeção visual é confirmada pelo Teste de I de Moran realizado nos resíduos (\(I = -0.0311\); \(p = 0.9203\)). O valor-p elevado não permite rejeitar a hipótese nula de aleatoriedade espacial, o que confirma que o modelo BYM2 foi eficaz em incorporar toda a autocorrelação espacial significativa presente nos dados, restando nos resíduos apenas ruído branco estocástico.
1.12 Estatística Espacial vs. Econometria Espacial
A escolha entre as famílias de modelos condicionais (CAR/ICAR/BYM) e simultâneos (SAR) é fundamentalmente guiada pelo objetivo, pela natureza teórica da dependência espacial e pelo contexto disciplinar. A Estatística Espacial, com seus modelos CAR e ICAR, adota uma abordagem condicional ou markoviana [@besag1974spatial], cujo objetivo primário é a predição, suavização e mapeamento de superfícies latentes, como o risco de doença ou a concentração de poluentes [@cressie1993statistics]. Neste paradigma, o foco reside em modelar com precisão a estrutura de covariância para capturar padrões espaciais, utilizando uma formulação baseada em distribuições condicionais locais. Esta especificação resulta em uma matriz de precisão esparsa, o que confere eficiência computacional a métodos bayesianos e hierárquicos, como MCMC e INLA [@rue2009approximate; @rue2005gaussian]. Esta abordagem é predominante em campos como a epidemiologia, ecologia e ciências ambientais, onde a interpretação do processo espacial latente e a quantificação da incerteza de predição são objetivos centrais [@riebler2016intuitive; @banerjee2003hierarchical].
Em contraste, a Econometria Espacial, fundamentada no modelo SAR, adota uma abordagem simultânea ou estrutural [@anselin1988spatial]. Seu objetivo primário é a inferência causal e a estimação não enviesada de parâmetros que capturem efeitos de interação e transbordamento (spillovers) entre unidades [@lesage2009introduction]. Sua formulação constitui um sistema de equações com feedback, onde o valor em uma unidade depende simultaneamente dos valores em outras, gerando uma estrutura de precisão geralmente densa [@ver2018relationship]. Esta característica associa-a mais fortemente a métodos de estimação frequentistas, como a máxima verossimilhança ou o método dos momentos generalizado (GMM) [@anselin2010thirty]. Esta abordagem é predominante em campos como economia regional, ciências políticas e estudos urbanos, onde a questão central é testar teorias sobre interdependência estratégica, externalidades espaciais ou difusão de políticas.
A seleção do modelo deve ser uma função direta da pergunta de pesquisa. Deve-se optar por modelos CAR, ICAR ou BYM quando o interesse principal for a predição, suavização ou recuperação de um campo aleatório espacial subjacente [@wall2004close]. Estes são a escolha natural para a criação de mapas de risco, interpolação de superfícies ou para modelagem bayesiana hierárquica que “empreste força” (borrowing strength) entre áreas vizinhas [@riebler2016intuitive]. Por outro lado, modelos SAR (ou modelos de erro espacial - SEM) são mais adequados quando o interesse é a inferência causal sobre um parâmetro de interação espacial (\(\rho\)) ou quando a teoria subjacente postula um mecanismo de dependência simultânea e feedback entre unidades observadas, como em modelos de competição ou difusão [@ver2018relationship]. Tais modelos são essenciais para corrigir viés de variável omitida espacial e para estimar efeitos diretos e indiretos de políticas. Ambas as abordagens são complementares, e a fronteira entre elas tem se tornado mais permeável, com avanços metodológicos permitindo, por exemplo, a interpretação de priors CAR em termos de equilíbrio de sistemas dinâmicos ou o uso de técnicas de álgebra esparsa para a estimação eficiente de certas especificações de modelos SAR [@ver2018relationship; @lesage2009introduction].
1.13 Modelos Espaciais Econométricos para Dados de Área
A econometria espacial distingue-se da estatística espacial clássica (como os modelos CAR, SAR Section 1.7.1) por sua ênfase na identificação de relações causais, na fundamentação teórica dos processos de dependência (como interações estratégicas, efeitos de contágio ou externalidades) e na garantia de propriedades assintóticas dos estimadores, especialmente a consistência sob condições de endogeneidade. Enquanto os modelos CAR são frequentemente usados para suavização e predição em contextos Bayesianos hierárquicos, os modelos econométricos (SAR, SEM, SDM, etc.) são desenhados para testar hipóteses sobre mecanismos de interação e estimar o impacto de políticas ou choques exógenos em um sistema interconectado.
A literatura econométrica, consolidada por @anselin1988spatial e expandida expressivamente por @lesage2009introduction, @elhorst2014spatial e @kelejian2017spatial, organiza os modelos espaciais com base na inclusão de três tipos fundamentais de interação entre unidades espaciais:
Defasagem espacial na variável dependente (\(\mathbf{W}\mathbf{y}\)): Refere-se ao fenômeno em que o resultado observado em uma região ou agente é diretamente influenciado pelos resultados observados em regiões ou agentes vizinhos. Isto é, o valor da variável de interesse na unidade \(i\) (\(y_i\)) é determinado simultaneamente pelos valores de \(y\) nas unidades vizinhas (\(\mathbf{W}\mathbf{y}\), ver @elhorst2022dynamic).
Exemplo: Competição fiscal entre municípios (a alíquota de imposto de um município depende da alíquota dos vizinhos para não perder base tributária) ou efeitos de pares em educação (o desempenho de um aluno depende do desempenho dos colegas).
Defasagem espacial nas variáveis explicativas (\(\mathbf{W}\mathbf{X}\)): Refere-se à influência que as características ou políticas de regiões vizinhas exercem sobre os resultados de uma região. É um efeito de transbordamento direto ou externalidade, onde o que acontece ao lado importa tanto quanto o que acontece aqui (ver @elhorst2022dynamic). Note que aqui \(\mathbf{X}\) é covariável.
Exemplo: A criminalidade em um bairro pode ser afetada não apenas pelo policiamento local, mas também pelo policiamento nos bairros vizinhos (deslocamento do crime).
Dependência espacial no termo de erro (\(\mathbf{W}\mathbf{u}\)): Refere-se à dependência residual. A correlação espacial surge devido a variáveis omitidas que são espacialmente correlacionadas ou a erros de medição com padrão espacial. Isto é, mesmo após controlar pelas variáveis explicativas observadas (\(\mathbf{X}\)), os resíduos de unidades geograficamente próximas podem não ser independentes, podendo ser correlacionados. Isso indica que os fatores não observados que influenciam a variável resposta \(\mathbf{y}\) possuem, eles próprios, uma estrutura espacial.
Exemplo: Considere um modelo de preços de imóveis que inclui variáveis como tamanho, idade, número de quartos e proximidade do centro. Se o modelo omitir a poluição sonora (ruído de tráfego) um fator que varia gradualmente no espaço (ruas adjacentes têm níveis similares), os imóveis em ruas mais barulhentas terão sistematicamente preços abaixo do previsto pelo modelo, enquanto aqueles em ruas mais silenciosas terão preços acima do previsto. Como a poluição sonora é espacialmente correlacionada, os erros do modelo (resíduos) também o serão: resíduos negativos se agruparão em regiões barulhentas e positivos em regiões quietas. Essa estrutura espacial nos resíduos é exatamente a dependência espacial no termo de erro (\(W u\)).
O modelo mais geral que engloba essas três formas de interação é o modelo geral de aninhamento espacial (GNS - General Nesting Spatial Model, @elhorst2022dynamic), por vezes referido como Spatial Autoregressive model with Spatial Autoregressive errors (SARAR) ou Spatial Autoregressive Combined (SAC) generalizado:
\(\mathbf{y}\) é um vetor \(N \times 1\) da variável dependente.
\(\mathbf{X}\) é uma matriz \(N \times K\) de variáveis explicativas (covaráveis).
\(\mathbf{W}\) é a matriz de pesos espaciais (ou matriz de vizinhança) \(N \times N\). Pode-se usar matrizes diferentes para cada termo (\(\mathbf{W}_1, \mathbf{W}_2\)), mas frequentemente assume-se a mesma estrutura por parcimônia.
\(\rho\) é o coeficiente autorregressivo espacial (intensidade da dependência substantiva).
\(\boldsymbol{\beta}\) é o vetor \(K \times 1\) de parâmetros associados às covariáveis.
\(\boldsymbol{\theta}\) é o vetor \(K \times 1\) de parâmetros associados à defasagem espacial.
\(\lambda\) é o coeficiente de erro autorregressivo espacial.
\(\boldsymbol{\epsilon} \sim \mathcal{N}(\mathbf{0}, \sigma^2 \mathbf{I}_n)\) é o vetor de erros, tipicamente assumido i.i.d. com média zero e variância constante \(\sigma^2\) (embora métodos modernos relaxem a homocedasticidade).
A partir desta estrutura geral, impõem-se restrições aos parâmetros (\(\rho=0\), \(\lambda=0\), ou \(\boldsymbol{\theta}=\mathbf{0}\)) para derivar os modelos específicos mais utilizados na prática.
1.13.1 Modelo de Defasagem Espacial (SAR – Spatial Autoregressive Model)
O Modelo de Defasagem Espacial (SAR, o mesmo descrito na Section 1.9), também conhecido como Spatial Lag Model, constitui um caso particular do Modelo Geral de Aninhamento Espacial (GNS, Equation 4) obtido ao impor as restrições paramétricas \(\lambda = 0\) e \(\boldsymbol{\theta} = \mathbf{0}\).
Esta especificação pressupõe que a dependência espacial é um fenômeno substantivo, resultante da interação direta e simultânea entre as unidades de observação, onde o resultado de uma localidade é condicionado pelos resultados de suas vizinhas. Formalmente, o modelo é definido pela seguinte equação estrutural [@anselin1988spatial]:
com erros i.i.d. \(\boldsymbol{\epsilon} \sim \mathcal{N}(\mathbf{0}, \sigma^2 \mathbf{I}_n)\). Na sua forma escalar, para uma unidade \(i\), o modelo é expresso como:
em que \(\rho\) é o coeficiente de autocorrelação espacial, que quantifica a intensidade da dependência espacial.
A partir da forma reduzida do modelo, obtém-se a distribuição condicional completa de \(\mathbf{y}\). Assumindo que \((\mathbf{I}_n - \rho \mathbf{W})\) é não singular (tem inversa), temos:
Esta expressão evidencia que tanto a média condicional quanto a estrutura de covariância de \(\mathbf{y}\) são globalmente afetadas pela configuração espacial através da matriz de pesos \(\mathbf{W}\) e do parâmetro \(\rho\).
A especificação é motivada por processos de difusão, contágio, competição estratégica, externalidades ou efeitos de aprendizagem entre agentes ou regiões geograficamente próximas [@lesage2009introduction].
A natureza simultânea do modelo é explicitada por sua forma reduzida (ou Data Generating Process – DGP), obtida ao resolver a equação para \(\mathbf{y}\):
revela que um choque exógeno (seja via \(\mathbf{X}\) ou \(\boldsymbol{\epsilon}\)) em uma unidade \(i\) não afeta apenas \(y_i\) ou seus vizinhos diretos, mas propaga-se por toda a rede através de efeitos de feedback de ordem superior, envolvendo caminhos de comprimento crescente na estrutura de vizinhança [@elhorst2014spatial].
Consequentemente, a esperança condicional da variável dependente é espacialmente estruturada:
\[
\mathbb{E}[\mathbf{y} \, | \, \mathbf{X}, \mathbf{W}] = (\mathbf{I}_n - \rho \mathbf{W})^{-1}\mathbf{X}\boldsymbol{\beta}.
\] A presença do multiplicador espacial implica que a interpretação dos parâmetros \(\boldsymbol{\beta}\) no modelo SAR difere fundamentalmente da regressão linear clássica. Estes coeficientes não representam os efeitos marginais diretos de uma mudança nas variáveis explicativas. Como qualquer alteração em uma covariável para a unidade \(i\) afeta sua própria variável dependente e, via interdependência, as das demais unidades, os efeitos são globais.
@lesage2009introduction propõe uma decomposição da matriz de efeitos totais das variáveis explicativas, derivada da forma reduzida do modelo. Para uma variável explicativa \(k\), o efeito total de uma mudança unitária em todo o sistema é dado pela matriz:
Efeito direto médio que captura o impacto médio de uma mudança em \(x_{ik}\) sobre o próprio \(y_i\). Este efeito inclui tanto o impacto inicial quanto os feedbacks espaciais que retornam à unidade de origem.
Efeito indireto médio (ou Spillover) que captura o impacto médio da mudança em \(x_{ik}\) sobre todas as outras unidades \(y_j\) (\(j \neq i\)).
A presença da variável dependente defasada espacialmente (\(\mathbf{W}\mathbf{y}\)) no lado direito da equação gera um problema de simultaneidade: como \(y_i\) depende de \(y_j\) e vice-versa, o termo \(\mathbf{W}\mathbf{y}\) está correlacionado com o termo de erro \(\boldsymbol{\epsilon}\). Isto implica que o estimador de Mínimos Quadrados Ordinários (MQO) é viesado e inconsistente (\(plim \, \hat{\rho}_{MQO} \neq \rho\)), tendendo a superestimar a dependência espacial e enviesar os coeficientes \(\boldsymbol{\beta}\)[@anselin1988spatial].
As abordagens mais comuns para a estimação consistente e eficiente são:
máxima verossimilhança: Maximiza a função de verossimilhança que incorpora o log-determinante do Jacobiano da transformação, \(\ln|\mathbf{I}_n - \rho \mathbf{W}|\), para corrigir a simultaneidade.
Método dos Momentos Generalizados (GMM) / Variáveis Instrumentais (VI): Utiliza defasagens espaciais das covariáveis (\(\mathbf{W}\mathbf{X}, \mathbf{W}^2\mathbf{X}, \dots\)) como instrumentos válidos para \(\mathbf{W}\mathbf{y}\), uma estratégia robusta proposta por [@kelejian1998generalized] .
Code
if (!require("pacman")) install.packages("pacman")pacman::p_load(spatialreg, spdep, sf, texreg, knitr, kableExtra, dplyr)# Preparação dos Dadosif (!exists("mg_dados")) { mg_dados <- geobr::read_municipality(code_muni ="MG", year =2020, showProgress =FALSE) coords <-st_coordinates(st_centroid(mg_dados))set.seed(123) mg_dados$taxa_bruta <- (-coords[,2] *10) +rnorm(nrow(mg_dados), 0, 5) mg_dados$variavel_x <-rnorm(nrow(mg_dados))}# Matriz de Pesos Espaciais (Padronizada por linha 'W' é o padrão para SAR)nb <-poly2nb(mg_dados, queen =TRUE)lw <-nb2listw(nb, style ="W", zero.policy =TRUE)# Ajuste do Modelo# A) OLS (Referência)mod_ols <-lm(taxa_bruta ~ variavel_x, data = mg_dados)# SAR (Spatial Autoregressive Model) - Máxima Verossimilhança# A função lagsarlm ajusta do modelo SAR via MLmod_sar <-lagsarlm(taxa_bruta ~ variavel_x, data = mg_dados, listw = lw)#mapa_vars <-c("(Intercept)"="Intercepto","variavel_x"="Variável X","rho"="$\\rho$ (Dependência Espacial)")#mapa_gof <-list(list("raw"="nobs", "clean"="N", "fmt"=0),list("raw"="r.squared", "clean"="$\\ R^2$", "fmt"=3),list("raw"="aic", "clean"="AIC", "fmt"=1),list("raw"="logLik", "clean"="Log Likelihood", "fmt"=1))# Gerar a Tabela Principalmodelsummary(list("OLS (Clássico)"= mod_ols, "SAR (Lag Espacial)"= mod_sar),coef_map = mapa_vars, gof_map = mapa_gof, estimate="{estimate} [{conf.low}, {conf.high}]",stars =c('*'= .05, '**'= .01, '***'= .001),title =NULL, output ="kableExtra", escape =FALSE) %>%kable_styling(latex_options =c("HOLD_position"), full_width =FALSE, position ="center") %>%row_spec(5, bold =TRUE) %>%as.character() %>%cat()
Table 4: Resultados da Estimação do Modelo SAR e Decomposição dos Efeitos. Estimativas [intervalo de confiança] e abaixo o respetivo erro padrão.
OLS (Clássico)
SAR (Lag Espacial)
Intercepto
8.973 [8.616, 9.330]
5.751 [4.876, 6.626]
(0.182)
(0.446)
Variável X
0.058 [−0.306, 0.422]
0.029 [−0.316, 0.374]
(0.185)
(0.176)
\(\rho\) (Dependência Espacial)
0.359 [0.269, 0.449]
(0.046)
N
853
\(\ R^2\)
0.000
AIC
5275.0
5212.9
Log Likelihood
−2634.5
* p < 0.05, ** p < 0.01, *** p < 0.001
Interpretação
A Table 4 para a comparação de modelos evidencia a superioridade de ajuste do modelo de SAR em detrimento do linear (OLS), como observa-se pela redução substancial no Critério de Informação de Akaike (AIC), que decresceu de \(5275.0\) no modelo clássico para \(5212.9\) na especificação espacial. Este ganho de ajuste é atribuído à significância do parâmetro de autoregressão espacial \(\rho\) (\(0.359\); \(IC_{95\%} [0.269, 0.449]\)), que confirma a existência de dependência espacial positiva na variável resposta.
Não obstante a melhor adequação da estrutura espacial, a Table 4 de decomposição dos impactos demonstra que a covariável \(X\) não possui significância estatística. A análise dos efeitos marginais revela que a variável explicativa não exerce influência sobre o desfecho, apresentando valores-p não significativos tanto para o efeito direto (\(0.030\); \(p=0.829\)), que mensura o impacto local, quanto para o efeito indireto (\(0.015\); \(p=0.837\)), que mensura o transbordamento espacial. Conclui-se, portanto, que embora a modelagem da dependência espacial seja necessária para a correção do viés de especificação, a variável \(X\) não é um determinante estatisticamente relevante do fenômeno estudado, apresentando um efeito total nulo (\(0.045\); \(p=0.831\)).
Você poderia gerar formatação em latex e colar no seu overleaf ou latex.
if (!require("pacman")) install.packages("pacman")pacman::p_load(spatialreg, spdep, sf, ggplot2, dplyr, tidyr, patchwork, viridis, Matrix)# if (!exists("mod_sar") ||!exists("mg_dados")) { mg_dados <- geobr::read_municipality(code_muni ="MG", year =2020, showProgress =FALSE) coords <-st_coordinates(st_centroid(mg_dados))set.seed(123) mg_dados$taxa_bruta <- (-coords[,2] *10) +rnorm(nrow(mg_dados), 0, 5) mg_dados$variavel_x <-rnorm(nrow(mg_dados)) nb <-poly2nb(mg_dados, queen =TRUE) lw <-nb2listw(nb, style ="W", zero.policy =TRUE) mod_sar <-lagsarlm(taxa_bruta ~ variavel_x, data = mg_dados, listw = lw)}#Gráfico de Impactos (Direto vs Indireto Unificado)set.seed(123)imp_mc_plot <-impacts(mod_sar, listw = lw, R =1000)if (is.null(imp_mc_plot$smat) &&is.null(imp_mc_plot$res)) { imp_mc_plot <-impacts(mod_sar, listw = lw, R =1000, zstats =TRUE)}# Dataframe Direto e Indiretodf_impactos <-data.frame(direct = imp_mc_plot$res$direct,indirect = imp_mc_plot$res$indirect) %>%pivot_longer(cols =everything(), names_to ="Tipo", values_to ="Valor") %>%mutate(Tipo =factor(Tipo, levels =c("direct", "indirect"),labels =c("Direto", "Indireto (Spillover)")))# g_impactos <-ggplot(df_impactos, aes(x = Tipo, fill = Tipo, y=Valor)) +geom_col(width =0.2, color ="gray30") +scale_fill_manual(values =c("Direto"="#1b9e77", "Indireto (Spillover)"="#d95f02")) +labs(title ="A. Impactos: Direto vs. Indireto", y ="Magnitude do efeito", x =NULL) +theme_minimal() +theme(legend.position ="none", legend.title =element_blank())# Mapa dos Valores Ajustadosmg_dados$fitted_sar <-fitted(mod_sar)g_fit <-ggplot(mg_dados) +geom_sf(aes(fill = fitted_sar), color =NA) +scale_fill_viridis_c(option ="turbo", name ="Predito") +labs(title ="B. Valores Preditos (SAR)", subtitle ="Padrão espacial recuperado")+theme_minimal() +annotation_scale(location ="bl", width_hint =0.3, bar_cols =c("black", "white"), text_family ="sans" ) +annotation_north_arrow(location ="tl", which_north ="true", pad_x =unit(0.2, "in"), pad_y =unit(0.2, "in"), style = north_arrow_fancy_orienteering )# Diagnóstico dos Resíduosmg_dados$resid_sar <-residuals(mod_sar)moran_res <-moran.test(mg_dados$resid_sar, lw)mg_dados$resid_lag <-lag.listw(lw, mg_dados$resid_sar)g_resid_scatter <-ggplot(mg_dados, aes(x = resid_sar, y = resid_lag)) +geom_hline(yintercept =0, linetype ="dashed", color ="gray") +geom_vline(xintercept =0, linetype ="dashed", color ="gray") +geom_point(alpha =0.3) +geom_smooth(method ="lm", se =FALSE, color ="red", size =0.8) +labs(title ="C. Scatter de Moran (Resíduos)", subtitle =paste0("I de Moran: ", round(moran_res$estimate[1], 3), " (p-valor: ", round(moran_res$p.value, 3), ")"),x ="Resíduos", y ="Lag Espacial") +theme_minimal()# (g_impactos | g_fit | g_resid_scatter)
Figure 15: Diagnóstico SAR: (A) Comparação Direto vs Indireto, (B) Ajuste do Modelo e (C) Análise de Resíduos.
Interpretação
O mapa de valores preditos em Figure 15 (B) mostra que o modelo foi capaz de recuperar a estrutura espacial do processo, reproduzindo a heterogeneidade regional e os padrões de aglomeração observados na variável dependente, uma contribuição atribuível quase exclusivamente ao termo de autoregressão espacial (\(\rho\)) dada a nulidade da covariável \(X\). A validade dessa especificação é confirmada na Figure 15 (C), onde o grafico de dispersão para os resíduos de Moran não mostra nenhuma tendência. A estatística de Moran (\(I = -0.015\)) com valor-p não significativo (\(0.735\)) atesta a independência espacial dos resíduos.
1.13.2 Modelo de Erro Espacial (SEM - Spatial Error Model)
O Modelo de Erro Espacial (SEM) é um caso particular do Modelo Espacial Geral (GNS, Equation 4) obtido ao se impor as restrições paramétricas \(\rho = 0\) e \(\boldsymbol{\theta} = \mathbf{0}\). Esta especificação pressupõe a ausência de interações espaciais diretas tanto na variável dependente quanto nas variáveis explicativas, concentrando toda a estrutura de dependência espacial no termo de erro estocástico. Formalmente, o modelo é definido pelo sistema de equações [@anselin1988spatial]:
com inovações i.i.d. \(\boldsymbol{\epsilon} \sim \mathcal{N}(\mathbf{0}, \sigma^2 \mathbf{I}_n)\). A distribuição condicional de \(\mathbf{y}\) é, portanto, uma normal multivariada:
Conforme destacado por @lesage2009introduction, a utilidade do SEM reside no tratamento da dependência espacial como um fenômeno residual, frequentemente resultante de variáveis omitidas com padrão espacial ou de erros de medição decorrentes de delimitações administrativas arbitrárias que não coincidem com os verdadeiros limites econômicos. Diferentemente dos modelos SAR (Equation 5) e SDM (Equation 8), que capturam interações espaciais substantivas, a estrutura do SEM implica que a dependência espacial é um ruído a ser controlado para inferência válida.
A forma reduzida do processo gerador de dados é obtida substituindo a equação do erro na equação principal:
o que revela que erros (choques) aleatórios \(\boldsymbol{\epsilon}\) propagam-se globalmente através do multiplicador espacial inverso \((\mathbf{I}_n - \lambda \mathbf{W})^{-1}\) (desde que este exista). Contudo, a esperança condicional da variável dependente mantém-se não espacial:
No SEM, os coeficientes \(\boldsymbol{\beta}\) representam derivadas parciais verdadeiras, isto é, os efeitos marginais diretos das variáveis explicativas. Uma variação em \(x_{ik}\) afeta apenas \(y_i\), sem desencadear feedback ou spillovers espaciais na média das unidades vizinhas [@elhorst2014spatial].
Do ponto de vista da estimação, a imposição incorreta de \(\lambda = 0\) e o uso de Mínimos Quadrados Ordinários (MQO) não comprometem a consistência dos estimadores pontuais de \(\boldsymbol{\beta}\), uma vez que a média dos erros permanece zero e ortogonal aos regressores. No entanto, essa estratégia produz estimadores ineficientes e, mais criticamente, enviesa a estimação da matriz de covariância dos parâmetros, invalidando a inferência baseada em testes \(t\) e \(F\) padrão [@anselin1988spatial].
A estimação eficiente exige métodos que incorporem explicitamente a estrutura não esférica da matriz de covariância dos erros:
As abordagens usuais para obter estimadores consistentes e eficientes são a máxima verossimilhança e o Método dos Momentos Generalizados (GMM), que permitem a recuperação adequada dos erros-padrão e a realização de inferência válida [@kelejian2010specification].
Code
if (!require("pacman")) install.packages("pacman")pacman::p_load(spatialreg, spdep, sf, modelsummary, kableExtra, dplyr)# SEM (Spatial Error Model)# A função errorsarlm ajusta o SEM via Máxima Verossimilhançamod_sem <-errorsarlm(taxa_bruta ~ variavel_x, data = mg_dados, listw = lw)#Tabela mapa_vars <-c("(Intercept)"="Intercepto","variavel_x"="Variável X","rho"="$\\rho$ (Lag Espacial)", # Parâmetro do SAR"lambda"="$\\lambda$ (Erro Espacial)"# Parâmetro do SEM)mapa_gof <-list(list("raw"="nobs", "clean"="N", "fmt"=0),list("raw"="r.squared", "clean"="$R^2$", "fmt"=3),list("raw"="aic", "clean"="AIC", "fmt"=1),list("raw"="logLik", "clean"="Log Likelihood", "fmt"=1))#Gerar a Tabela Comparativa (OLS, SAR, SEM)modelsummary(list("OLS (Clássico)"= mod_ols, "SAR"= mod_sar, "SEM"= mod_sem ),coef_map = mapa_vars, gof_map = mapa_gof, estimate ="{estimate} [{conf.low}, {conf.high}]",statistic =NULL, stars =c('*'= .05, '**'= .01, '***'= .001),title =NULL, output ="kableExtra", escape =FALSE) %>%kable_styling(latex_options =c("HOLD_position"), full_width =FALSE, position ="center") %>%row_spec(c(5, 7), bold =TRUE) %>%as.character() %>%cat()
Table 6: Resultados da Estimação: Comparação OLS, SAR e SEM. Estimativas [intervalo de confiança 95%].
OLS (Clássico)
SAR
SEM
Intercepto
8.973 [8.616, 9.330]
5.751 [4.876, 6.626]
8.978 [8.449, 9.507]
Variável X
0.058 [−0.306, 0.422]
0.029 [−0.316, 0.374]
−0.001 [−0.342, 0.340]
\(\rho\) (Lag Espacial)
0.359 [0.269, 0.449]
\(\lambda\) (Erro Espacial)
0.359 [0.270, 0.449]
N
853
\(R^2\)
0.000
AIC
5275.0
5212.9
5213.0
Log Likelihood
−2634.5
* p < 0.05, ** p < 0.01, *** p < 0.001
Interprete
A Table 6 apresenta a análise comparativa entre os modelos de regressão linear (OLS), de defasagem espacial (SAR) e de erro espacial (SEM), evidenciando a superioridade de ajuste das especificações espaciais sobre a abordagem clássica. Observa-se uma melhoria substancial na qualidade do ajuste ao incorporar a dependência espacial, demonstrada pela redução do Critério de Informação de Akaike (AIC), que declinou de \(5275.0\) no OLS para valores idênticos de \(5212.9\) no SAR e \(5213.0\) no SEM. Essa equivalência entre os modelos espaciais é reforçada pela magnitude dos parâmetros estimados: tanto o coeficiente de defasagem espacial \(\rho\) (\(0.359\); \(IC_{95\%} [0.269, 0.449]\)) quanto o coeficiente de erro espacial \(\lambda\) (\(0.359\); \(IC_{95\%} [0.270, 0.449]\)) são estatisticamente significativos e apresentam estimativas pontuais coincidentes, indicando que a estrutura de autocorrelação independentemente da especificação funcional adotada. Adicionalmente, no modelo SEM o coeficiente estimado permaneceu estatisticamente nulo (\(-0.001\); \(IC_{95\%} [-0.342, 0.340]\)), confirmando que a variabilidade do fenômeno é explicada predominantemente pela estrutura de dependência espacial e não pela variável preditora \(X\).
Figure 16: Diagnóstico SEM: (A) Ajuste do Modelo e (B) Análise de Resíduos.
Interpretação
O mapeamento dos valores preditos em Figure 16 (A) demonstra a capacidade do modelo em capturar a variabilidade espacial latente, reproduzindo os gradientes regionais distintivos do fenômeno através da correção via termo \(\lambda\). A robustez desta especificação é atestada em Figure 16 (B), onde a distribuição dos resíduos de Moran mostra ausência de associação espacial, evidenciada pela inclinação nula da reta de regressão e dispersão isotrópica. A estatística de I de Moran (\(-0.014\)) associada a um valor-p não significativo (\(0.734\)) confirma que a autocorrelação espacial foi integralmente absorvida pela estrutura de erro especificada, garantindo que os resíduos remanescentes se comportem como ruído branco estocástico.
1.13.3 Modelo de Defasagem Espacial de X (SLX – Spatial Lag of X)
O Modelo de Defasagem Espacial de X (SLX) representa a especificação mais parcimoniosa para incorporação de efeitos de interação espacial. Diferentemente dos modelos SAR (Equation 5) e SEM (Equation 6), que modelam a dependência através da variável resposta ou do termo de erro, o SLX postula que o resultado de uma unidade é influenciado tanto por suas características próprias quanto pelas características observáveis de suas unidades vizinhas.
Na taxonomia do Modelo Geral Espacial (GNS, Equation 4), o SLX é obtido ao impor as restrições paramétricas \(\rho = 0\) e \(\lambda = 0\). O modelo é especificado pela equação estrutural:
onde: - \(\mathbf{W}\mathbf{X}\) denota a matriz de defasagens espaciais das variáveis explicativas, capturando o contexto espacial das covariáveis.
\(\boldsymbol{\beta} \in \mathbb{R}^{K}\) é o vetor de parâmetros associado aos efeitos diretos das características da própria unidade \(i\).
\(\boldsymbol{\theta} \in \mathbb{R}^{K}\) é o vetor de parâmetros associado aos efeitos de transbordamento exógenos (spillovers), capturando a influência das características das unidades vizinhas.
@halleck2015slx, posiciona o SLX como um modelo de referência inicial para modelagem de dados espaciais (o primeiro a ser testado antes de ir aos mais complexos). Sua justificativa teórica reside na modelagem de transbordamentos locais (ou de primeira ordem), em contraste com a dependência global induzida pelo multiplicador espacial \((\mathbf{I}_n - \rho \mathbf{W})^{-1}\) do modelo SAR (Equation 5) [@lesage2009introduction].
A derivada parcial da esperança condicional \(\mathbb{E}[\mathbf{y} \, | \, \mathbf{X}, \mathbf{W}]\) em relação à \(k\)-ésima variável explicativa revela uma separação clara dos efeitos:
Efeito Direto: \(\frac{\partial y_i}{\partial x_{ik}} = \beta_k\). Uma mudança em \(x_{ik}\) afeta \(y_i\) diretamente, sem mecanismos de retroalimentação (feedback).
Efeito Indireto (Spillover Local): \(\frac{\partial y_i}{\partial x_{jk}} = \theta_k w_{ij}\). O impacto de uma mudança na unidade vizinha \(j\) sobre \(y_i\) é proporcional ao peso espacial \(w_{ij}\) e ao parâmetro \(\theta_k\). Se \(w_{ij} = 0\), o efeito é nulo, caracterizando a localidade do transbordamento.
Uma limitação crítica dos modelos de dependência global, como o SAR, é que a razão entre efeitos indiretos e diretos é determinada unicamente pelo parâmetro \(\rho\), sendo idêntica para todas as variáveis explicativas. O modelo SLX supera esta restrição, permitindo que a magnitude e até o sinal dos efeitos de transbordamento (\(\theta_k\)) sejam estimados livremente para cada covariável \(k\). Esta flexibilidade permite testar hipóteses substantivas complexas, como a coexistência de externalidades positivas para uma variável e negativas para outra.
Sob os pressupostos clássicos de linearidade, exogeneidade de \(\mathbf{X}\) e \(\mathbf{W}\mathbf{X}\), e erros esféricos, o modelo SLX apresenta propriedades estatísticas desejáveis:
Dado que todas as variáveis do lado direito da equação (\(\mathbf{X}\) e \(\mathbf{W}\mathbf{X}\)) são exógenas, o estimador MQO de \(\boldsymbol{\beta}\) e \(\boldsymbol{\theta}\) é não viesado, consistente e eficiente (sob homocedasticidade). Esta é uma vantagem operacional, dispensando métodos computacionalmente intensivos como máxima verossimilhança (ML) [@anselin1988spatial].
O modelo SLX minimiza problemas de multicolinearidade severa que podem surgir em modelos mais gerais (como o SDM ou GNS) devido à alta correlação entre \(\mathbf{W}\mathbf{y}\) e \(\mathbf{W}\mathbf{X}\).
Conforme descrito por @halleck2015slx, a estrutura do SLX simplifica o tratamento estatístico da possível endogeneidade das variáveis explicativas \(\mathbf{X}\). Métodos padrão de Variáveis Instrumentais (VI) ou Mínimos Quadrados em Dois Estágios (MQ2E) podem ser aplicados diretamente para instrumentar \(\mathbf{X}\) e \(\mathbf{W}\mathbf{X}\), sem a complexidade adicional introduzida pela endogeneidade de \(\mathbf{W}\mathbf{y}\) em modelos SAR.
A simplicidade da função objetivo (soma de quadrados dos resíduos) no SLX permite a estimação conjunta dos parâmetros do modelo (\(\boldsymbol{\beta}, \boldsymbol{\theta}\)) e de parâmetros que definem a matriz de pesos espaciais \(\mathbf{W}\). Por exemplo, pode-se especificar \(w_{ij} = d_{ij}^{-\gamma}\) e estimar o parâmetro de decaimento \(\gamma\) via Mínimos Quadrados Não Lineares (NLS), permitindo que a estrutura de interação espacial seja inferida diretamente dos dados.
Table 7: Resultados da Estimação: Comparação OLS, SLX, SAR e SEM. Estimativas [intervalo de confiança 95%].
OLS
SLX
SAR
SEM
Intercepto
8.973 [8.616, 9.330]
8.970 [8.613, 9.327]
5.751 [4.876, 6.626]
8.978 [8.449, 9.507]
Variável X (Direto)
0.058 [−0.306, 0.422]
0.056 [−0.308, 0.420]
0.029 [−0.316, 0.374]
−0.001 [−0.342, 0.340]
WX \(\theta\)
0.397 [−0.396, 1.190]
\(\rho\) (Lag Espacial)
0.359 [0.269, 0.449]
\(\lambda\) (Erro Espacial)
0.359 [0.270, 0.449]
N
853
853
\(\ R^2\)
0.000
0.001
AIC
5275.0
5276.1
5212.9
5213.0
Log Likelihood
−2634.5
−2634.0
* p < 0.05, ** p < 0.01, *** p < 0.001
Code
# Extraindo coeficientes e intervalos de confiança do SLXcoefs <-coef(mod_slx)cis <-confint(mod_slx)# Mapa dos Valores Ajustadosmg_dados$fitted_slx <-fitted(mod_slx)g_fit <-ggplot(mg_dados) +geom_sf(aes(fill = fitted_slx), color =NA) +scale_fill_viridis_c(option ="turbo", name ="Predito") +labs(title ="A. Valores Preditos (SLX)", subtitle ="Ajuste com defasagens de X") +theme_minimal() +annotation_scale(location ="bl", width_hint =0.3) +annotation_north_arrow(location ="tl", style = north_arrow_fancy_orienteering,pad_x =unit(0.1, "in"), pad_y =unit(0.1, "in"))# Diagnóstico dos Resíduos (Scatter de Moran)mg_dados$resid_slx <-residuals(mod_slx)moran_slx <-moran.test(mg_dados$resid_slx, lw)mg_dados$resid_lag_slx <-lag.listw(lw, mg_dados$resid_slx)g_resid_scatter <-ggplot(mg_dados, aes(x = resid_slx, y = resid_lag_slx)) +geom_hline(yintercept =0, linetype ="dashed", color ="gray") +geom_vline(xintercept =0, linetype ="dashed", color ="gray") +geom_point(alpha =0.3) +geom_smooth(method ="lm", se =FALSE, color ="red", size =0.8) +labs(title ="B. Scatter de Moran (Resíduos SLX)", subtitle =paste0("I de Moran: ", round(moran_slx$estimate[1], 3), " (p-valor: ", round(moran_slx$p.value, 3), ")"),x ="Resíduos", y ="Lag Espacial") +theme_minimal()( g_fit | g_resid_scatter)
Figure 17: Diagnóstico SLX: (A) Ajuste do Modelo e (B) Análise de Resíduos.
Interpretação
Ao contrário dos modelos globais (SAR e SEM), o mapa de valores preditos em Figure 17 (A) exibe uma superfície de predição com variabilidade atenuada, falhando em reproduzir a heterogeneidade e os clusters de valores altos observados nos dados originais. A inadequação do ajuste é demonstrada definitivamente em Figure 17 (C), onde o Scatter de Moran dos resíduos mostra tendência linear positiva, indicando que o modelo não foi capaz de capturar a estrutura espacial dos dados. A estatística de I de Moran (\(I = 0.198\)) com valor-p significativo (\(p \approx 0\)) confirma a persistência de autocorrelação espacial positiva nos erros, violando o pressuposto de independência estocástica e evidenciando que a simples inclusão de defasagens exógenas de \(X\) é ineficaz para capturar a dependência espacial presente no fenômeno.
1.13.4 Modelo Espacial de Durbin (SDM – Spatial Durbin Model)
O Modelo Espacial de Durbin (SDM) constitui uma especificação geral que unifica os mecanismos de dependência espacial endógena e efeitos contextuais exógenos. Dentro da família do Modelo Geral Espacial (GNS, Equation 4), o SDM é obtido ao impor a restrição \(\lambda = 0\), mantendo os parâmetros \(\rho\) e \(\boldsymbol{\theta}\) livres. Esta estrutura postula que o valor observado para uma unidade \(i\) é uma função simultânea: (i) dos valores da variável resposta em suas unidades vizinhas, (ii) de suas próprias características observadas, e (iii) das características observadas de suas vizinhas.
Formalmente, o modelo é definido pela equação estrutural [@anselin1988spatial; @lesage2009introduction]:
com o vetor de erros assumido como \(\boldsymbol{\epsilon} \sim \mathcal{N}(\mathbf{0}, \sigma^2 \mathbf{I}_n)\). Na sua forma escalar para uma unidade \(i\):
O SDM é frequentemente defendido como uma especificação de partida robusta em modelagem espacial [@lesage2009introduction]. Sua principal justificativa reside em sua capacidade de mitigar potenciais tendências de especificação (omitted variable bias). Se o processo gerador de dados subjacente envolver fatores não observados que são espacialmente correlacionados e relacionados a \(\mathbf{X}\), a omissão desses fatores induzirá dependência espacial nos resíduos. A inclusão do termo \(\mathbf{W}\mathbf{X}\) no SDM pode absorver parte desta correlação espacial omitida, produzindo estimativas mais estáveis para \(\boldsymbol{\beta}\).
Uma ligação fundamental na teoria dos modelos espaciais é que o modelo SEM (Equation 6) é um caso restrito do SDM. Esta relação é estabelecida pela hipótese de fator comom (Common Factor Hypothesis) [@burridge1981testing; @anselin1988spatial]. A restrição não-linear \(\boldsymbol{\theta} = -\rho \boldsymbol{\beta}\), quando válida, reduz a forma reduzida do SDM à do SEM. Consequentemente, estimar um SDM permite testar estatisticamente se a dependência espacial é de natureza substancial (capturada por \(\rho\) e \(\boldsymbol{\theta}\)) ou meramente residual (um artefato de erros correlacionados, como no SEM).
A presença simultânea do termo autorregressivo \(\mathbf{W}\mathbf{y}\) confere ao SDM uma estrutura de dependência global. A forma reduzida do modelo, obtida isolando \(\mathbf{y}\), é:
A matriz \((\mathbf{I}_n - \rho \mathbf{W})^{-1}\) atua como um multiplicador espacial global, propagando choques e efeitos através de toda a rede de interconexões (matriz de pesos / de vizinhança).
A interpretação direta dos coeficientes \(\boldsymbol{\beta}\) e \(\boldsymbol{\theta}\) é limitada, pois não representam efeitos marginais simples. Seguindo @lesage2009introduction, a matriz de derivadas parciais da esperança condicional \(\mathbb{E}[\mathbf{y} \, | \, \mathbf{X}, \mathbf{W}]\) em relação a uma variável explicativa \(k\) fornece a decomposição completa dos efeitos:
A partir desta matriz \(\mathbf{S}_k(\mathbf{W})\) de dimensão \(n \times n\), calculam-se os seguintes impactos médios:
Efeito direto médio, que é a média dos elementos da diagonal de \(\mathbf{S}_k(\mathbf{W})\). Mede o impacto esperado de uma mudança em \(x_{ik}\) sobre o próprio \(y_i\), incluindo todos os feedbacks espaciais que retornam à unidade \(i\).
Efeito indireto médio (ou de transbordamento), que é média da soma dos elementos fora da diagonal para cada linha (ou coluna) de \(\mathbf{S}_k(\mathbf{W})\). Mede o impacto esperado de uma mudança em \(x_{ik}\) sobre todas as outras unidades \(y_j\) (\(j \neq i\)).
Efeito total médio que é a soma do efeito direto e do efeito indireto, equivalente ao impacto médio de uma mudança simultânea em \(x_{k}\) para todas as unidades.
Ao contrário do modelo SAR, onde a razão entre efeitos indiretos e diretos é idêntica para todas as covariáveis, no SDM esta razão é única para cada variável \(k\), determinada pela combinação específica de \(\rho\), \(\beta_k\) e \(\theta_k\)[@halleck2015slx].
A presença da variável dependente defasada espacialmente (\(\mathbf{W}\mathbf{y}\)) no lado direito da equação introduz simultaneidade, tornando o estimador de Mínimos Quadrados Ordinários (MQO) viesado e inconsistente. Métodos de estimação consistentes são necessários:
máxima verossimilhança, que maximiza a função de log-verossimilhança condicional, incorporando o termo \(\ln |\mathbf{I}_n - \rho \mathbf{W}|\) para corrigir a simultaneidade [@anselin1988spatial].
Abordagem Bayesiana (MCMC), na qual @lesage1997bayesian desenvolveu um procedimento de inferência via Monte Carlo via Cadeias de Markov (MCMC). Esta abordagem é particularmente útil para realizar inferência sobre os impactos médios (diretos, indiretos e totais), que são funções não-lineares dos parâmetros, permitindo a construção direta de intervalos de credibilidade.
Assim, o SDM serve como um modelo geral que aninha especificações mais simples: o SAR (\(\boldsymbol{\theta} = \mathbf{0}\)), o SLX (\(\rho = 0\)), e o SEM (sob a restrição \(\boldsymbol{\theta} = -\rho \boldsymbol{\beta}\)). Por esta razão, uma estratégia de modelagem do geral para o específico, começando pelo SDM, é frequentemente recomendada para a análise de dados espaciais [@elhorst2014spatial].
Code
if (!require("pacman")) install.packages("pacman")pacman::p_load(spatialreg, spdep, sf, modelsummary, kableExtra, dplyr, ggplot2, patchwork, viridis, ggspatial, tidyr, Matrix)# 1. Preparação dos Dadosif (!exists("mg_dados")) { mg_dados <- geobr::read_municipality(code_muni ="MG", year =2020, showProgress =FALSE) coords <-st_coordinates(st_centroid(mg_dados))set.seed(123) mg_dados$taxa_bruta <- (-coords[,2] *10) +rnorm(nrow(mg_dados), 0, 5) mg_dados$variavel_x <-rnorm(nrow(mg_dados))}# SDM (Spatial Durbin Model)# type = "mixed" inclui lag de Y (rho) e lag de X (theta)mod_sdm <-lagsarlm(taxa_bruta ~ variavel_x, data = mg_dados, listw = lw, type ="mixed")#Tabelamapa_vars <-c("(Intercept)"="Intercepto","variavel_x"="$\\beta$","lag.variavel_x"="WX $\\theta$", # Compartilhado por SLX e SDM"rho"="$\\rho$", # Compartilhado por SAR e SDM"lambda"="$\\lambda$"# Exclusivo do SEM)mapa_gof <-list(list("raw"="nobs", "clean"="N", "fmt"=0),list("raw"="r.squared", "clean"="$R^2$", "fmt"=3),list("raw"="aic", "clean"="AIC", "fmt"=1),list("raw"="logLik", "clean"="Log Likelihood", "fmt"=1))# Tabela Unificadamodelsummary(list("OLS"= mod_ols, "SLX"= mod_slx,"SAR"= mod_sar, "SEM"= mod_sem,"SDM"= mod_sdm ),coef_map = mapa_vars, gof_map = mapa_gof, estimate ="{estimate} [{conf.low}, {conf.high}]",statistic =NULL, stars =c('*'= .05, '**'= .01, '***'= .001),title =NULL, output ="kableExtra",escape =FALSE) %>%kable_styling(latex_options =c("HOLD_position"), full_width =FALSE, position ="center") %>%row_spec(c(5, 7, 9), bold =TRUE) %>%as.character() %>%cat()
Table 8: Resultados da Estimação: Comparação Geral (OLS, SLX, SAR, SEM, SDM). Estimativas [IC 95%].
OLS
SLX
SAR
SEM
SDM
Intercepto
8.973 [8.616, 9.330]
8.970 [8.613, 9.327]
5.751 [4.876, 6.626]
8.978 [8.449, 9.507]
5.748 [4.873, 6.622]
\(\beta\)
0.058 [−0.306, 0.422]
0.056 [−0.308, 0.420]
0.029 [−0.316, 0.374]
−0.001 [−0.342, 0.340]
0.027 [−0.318, 0.372]
WX \(\theta\)
0.397 [−0.396, 1.190]
0.391 [−0.361, 1.143]
\(\rho\)
0.359 [0.269, 0.449]
0.359 [0.270, 0.449]
\(\lambda\)
0.359 [0.270, 0.449]
N
853
853
\(R^2\)
0.000
0.001
AIC
5275.0
5276.1
5212.9
5213.0
5213.9
Log Likelihood
−2634.5
−2634.0
* p < 0.05, ** p < 0.01, *** p < 0.001
Code
# Mapa dos Valores Ajustadosmg_dados$fitted_sdm <-fitted(mod_sdm)g_fit <-ggplot(mg_dados) +geom_sf(aes(fill = fitted_sdm), color =NA) +scale_fill_viridis_c(option ="turbo", name ="Predito") +labs(title ="A. Valores Preditos (SDM)", subtitle ="Ajuste considerando Wy e WX") +theme_minimal() +annotation_scale(location ="bl", width_hint =0.3) +annotation_north_arrow(location ="tl", style = north_arrow_fancy_orienteering,pad_x =unit(0.1, "in"), pad_y =unit(0.1, "in"))#Diagnóstico dos Resíduosmg_dados$resid_sdm <-residuals(mod_sdm)moran_sdm <-moran.test(mg_dados$resid_sdm, lw)mg_dados$resid_lag_sdm <-lag.listw(lw, mg_dados$resid_sdm)g_resid_scatter <-ggplot(mg_dados, aes(x = resid_sdm, y = resid_lag_sdm)) +geom_hline(yintercept =0, linetype ="dashed", color ="gray") +geom_vline(xintercept =0, linetype ="dashed", color ="gray") +geom_point(alpha =0.3) +geom_smooth(method ="lm", se =FALSE, color ="red", size =0.8) +labs(title ="C. Scatter de Moran (Resíduos SDM)", subtitle =paste0("I de Moran: ", round(moran_sdm$estimate[1], 3), " (p-valor: ", round(moran_sdm$p.value, 3), ")"),x ="Resíduos", y ="Lag Espacial") +theme_minimal()g_fit | g_resid_scatter
Figure 18: Diagnóstico SDM: (A) Densidade dos Impactos Globais, (B) Ajuste e (C) Resíduos.
1.13.5 Modelo Espacial de Durbin com Erro (SDEM – Spatial Durbin Error Model)
O Modelo Espacial de Durbin com Erro (SDEM) é uma especificação híbrida que combina a modelagem de efeitos contextuais exógenos locais com a correção para dependência espacial residual de natureza global. No contexto do Modelo Geral Espacial (GNS, Equation 4), o SDEM é obtido ao impor a restrição paramétrica \(\rho = 0\), mantendo livres os parâmetros \(\boldsymbol{\theta}\) e \(\lambda\).
Esta estrutura pressupõe que o valor da variável dependente em uma unidade \(i\) é explicado por: (1) suas próprias características observadas, (2) as características observadas de suas unidades vizinhas, e (3) um termo de erro que exibe autocorrelação espacial. O modelo é definido pelo seguinte sistema de equações [@anselin1988spatial; @elhorst2014spatial]:
O SDEM tem sido destacado na literatura como uma alternativa robusta ao Modelo de Durbin Espacial (SDM), especialmente quando a teoria subjacente sugere que os mecanismos de interação substantiva têm alcance geográfico limitado [@halleck2015slx]. A especificação separa duas fontes de dependência espacial:
A ausência do termo autorregressivo \(\rho \mathbf{W}\mathbf{y}\) implica que os spillovers substantivos são estritamente locais. Uma mudança nas características \(\mathbf{x}_j\) de uma unidade \(j\) afeta a unidade \(i\) apenas se \(w_{ij} \neq 0\), ou seja, se as unidades forem vizinhas diretas na estrutura definida por \(\mathbf{W}\). Não há mecanismos de feedback ou propagação global destes efeitos através da rede (matriz de pesos / de vizinhança).
O parâmetro \(\lambda\) captura a autocorrelação espacial nos resíduos, tipicamente atribuída a variáveis omitidas com padrão espacial ou a choques não observados que se difundem regionalmente. Diferentemente dos efeitos na média, estes choques propagam-se globalmente através do multiplicador espacial \((\mathbf{I}_n - \lambda \mathbf{W})^{-1}\) no termo de erro.
Esta separação é teoricamente atraente em aplicações onde se espera que externalidades de política ou características de vizinhança (\(\mathbf{W}\mathbf{X}\)) tenham alcance limitado (ex.: poluição sonora, sombreamento), enquanto fatores de confusão não observados (ex.:, normas culturais, clima) exibam um padrão de correlação espacial de longo alcance [@lesage2009introduction].
A forma reduzida do modelo é obtida ao substituir a estrutura do erro na Equation 9:
Crucialmente, a ausência do multiplicador global \((\mathbf{I}_n - \rho \mathbf{W})^{-1}\) na parte determinística simplifica radicalmente a interpretação dos coeficientes. A matriz de derivadas parciais é linear e diretamente obtida dos parâmetros estimados:
Efeito direto, onde \(\frac{\partial y_i}{\partial x_{ik}} = \beta_k\) representa o impacto de uma mudança na característica própria \(x_{ik}\) sobre o resultado \(y_i\). Este efeito é idêntico ao de uma regressão clássica, sem feedback espacial.
Efeito indireto (ou de Spillover local), onde \(\frac{\partial y_i}{\partial x_{jk}} = \theta_k w_{ij}\) representa o impacto de uma mudança na característica de uma unidade vizinha \(j\) sobre o resultado da unidade \(i\). Se \(w_{ij} = 0\) (unidades não conectadas), o efeito é nulo.
Embora a equação da média contenha apenas regressores exógenos (\(\mathbf{X}\) e \(\mathbf{W}\mathbf{X}\)), a presença de autocorrelação espacial no erro (\(\lambda \neq 0\)) viola o pressuposto de esfericidade. Consequentemente, o estimador de Mínimos Quadrados Ordinários (MQO) permanece não viesado e consistente para \(\boldsymbol{\beta}\) e \(\boldsymbol{\theta}\), mas se torna ineficiente. Mais criticamente, a estimativa da matriz de covariância dos parâmetros e, portanto, os erros-padrão e testes de hipótese padrão (testes \(t\), \(F\)) tornam-se inválidos [@anselin1988spatial].
A estimação eficiente e a inferência válida exigem métodos que incorporem explicitamente a estrutura de covariância não esférica dos erros, \(\operatorname{Cov}(\mathbf{u}) = \sigma^2 [(\mathbf{I}_n - \lambda \mathbf{W})^{\top}(\mathbf{I}_n - \lambda \mathbf{W})]^{-1}\). As abordagens padrão são:
máxima verossimilhança, que maximiza a função de log-verossimilhança que inclui o termo \(\ln |\mathbf{I}_n - \lambda \mathbf{W}|\) associado à transformação do erro.
Método dos Momentos Generalizados (GMM) que utiliza os momentos dos resíduos para estimar \(\lambda\) de forma consistente, conforme proposto por @kelejian1999generalized para modelos com erros espaciais.
O SDEM é, portanto, uma ferramenta valiosa quando a teoria apoia a existência de spillovers contextuais locais, mas é necessário controlar rigorosamente a heterogeneidade espacial não observada de longo alcance. Conforme recomendado por @elhorst2014spatial, este modelo é preferível ao SDM quando testes de especificação rejeitam a dependência espacial na variável dependente (rejeitam \(\rho \neq 0\) em favor de \(\rho = 0\)), mas indicam a presença simultânea de efeitos contextuais (\(\boldsymbol{\theta} \neq \mathbf{0}\)) e dependência residual nos erros (\(\lambda \neq 0\)).
Table 9: Resultados da Estimação: Comparação Geral (OLS, SLX, SAR, SEM, SDM, SDEM). Estimativas [IC 95%].
OLS
SLX
SAR
SEM
SDM
SDEM
Intercepto
8.973 [8.616, 9.330]
8.970 [8.613, 9.327]
5.751 [4.876, 6.626]
8.978 [8.449, 9.507]
5.748 [4.873, 6.622]
8.974 [8.444, 9.503]
\(\beta\)
0.058 [−0.306, 0.422]
0.056 [−0.308, 0.420]
0.029 [−0.316, 0.374]
−0.001 [−0.342, 0.340]
0.027 [−0.318, 0.372]
0.060 [−0.297, 0.417]
WX \(\theta\)
0.397 [−0.396, 1.190]
0.391 [−0.361, 1.143]
0.496 [−0.366, 1.359]
\(\rho\)
0.359 [0.269, 0.449]
0.359 [0.270, 0.449]
\(\lambda\)
0.359 [0.270, 0.449]
0.360 [0.270, 0.450]
N
853
853
\(R^2\)
0.000
0.001
AIC
5275.0
5276.1
5212.9
5213.0
5213.9
5213.7
Log Likelihood
−2634.5
−2634.0
* p < 0.05, ** p < 0.01, *** p < 0.001
Code
# Mapa dos Valores Ajustadosmg_dados$fitted_sdem <-fitted(mod_sdem)g_fit <-ggplot(mg_dados) +geom_sf(aes(fill = fitted_sdem), color =NA) +scale_fill_viridis_c(option ="turbo", name ="Predito") +labs(title ="A. Valores Preditos (SDEM)", subtitle ="Padrão recuperado (WX + Erro)") +theme_minimal() +annotation_scale(location ="bl", width_hint =0.3, bar_cols =c("black", "white")) +annotation_north_arrow(location ="tl", which_north ="true", pad_x =unit(0.2, "in"), pad_y =unit(0.2, "in"),style = north_arrow_fancy_orienteering)# Diagnóstico dos Resíduosmg_dados$resid_sdem <-residuals(mod_sdem)moran_sdem <-moran.test(mg_dados$resid_sdem, lw)mg_dados$resid_lag_sdem <-lag.listw(lw, mg_dados$resid_sdem)g_resid_scatter <-ggplot(mg_dados, aes(x = resid_sdem, y = resid_lag_sdem)) +geom_hline(yintercept =0, linetype ="dashed", color ="gray") +geom_vline(xintercept =0, linetype ="dashed", color ="gray") +geom_point(alpha =0.3) +geom_smooth(method ="lm", se =FALSE, color ="red", size =0.8) +labs(title ="B. Scatter de Moran (Resíduos SDEM)", subtitle =paste0("I de Moran: ", round(moran_sdem$estimate[1], 3), " (p-valor: ", round(moran_sdem$p.value, 3), ")"),x ="Resíduos", y ="Lag Espacial") +theme_minimal()(g_fit | g_resid_scatter)
Figure 19: Diagnóstico SDEM: (A) Impactos Locais (Sem Feedback Global), (B) Ajuste e (C) Resíduos.
1.13.6 Modelo Autorregressivo Espacial com Erros Autorregressivos (SARAR-Spatial Autoregressive with Autoregressive Disturbances)
O Modelo Autorregressivo Espacial com Erros Autorregressivos (SARAR), também referido como modelo SAC (Spatial Autoregressive Combined) ou modelo generalizado de Cliff-Ord, é uma especificação abrangente que modela simultaneamente a dependência espacial na variável resposta e a autocorrelação espacial no termo de erro.
No contexto do Modelo Geral Espacial (GNS, Equation 4), o SARAR é obtido ao impor a restrição \(\boldsymbol{\theta} = \mathbf{0}\), mantendo os parâmetros \(\rho \neq 0\) e \(\lambda \neq 0\). Formalmente, o modelo é definido pelo sistema de equações [@anselin1988spatial; @kelejian1998generalized]:
com erros independentes e identicamente distribuídos \(\boldsymbol{\epsilon} \sim (\mathbf{0}, \sigma^2 \mathbf{I}_n)\). As matrizes de pesos espaciais \(\mathbf{W}_1\) e \(\mathbf{W}_2\) podem ser distintas, refletindo diferentes estruturas de interação para a variável dependente e para os erros, embora a especificação com \(\mathbf{W}_1 = \mathbf{W}_2 = \mathbf{W}\) seja comum por parcimônia.
A especificação SARAR é motivada pela necessidade de distinguir e controlar dois processos espaciais operando conjuntamente: 1) um mecanismo de interação substantiva ou de feedback, onde o resultado de uma unidade é diretamente influenciado pelos resultados de suas vizinhas (capturado por \(\rho\)); e 2) um mecanismo de dependência residual, onde fatores não observados ou choques exógenos exibem padrão espacial (capturado por \(\lambda\)).
A identificação conjunta dos parâmetros \(\rho\) e \(\lambda\) é assegurada pela não-linearidade da função de verossimilhança, embora o uso de matrizes de pesos distintas (\(\mathbf{W}_1 \neq \mathbf{W}_2\)) possa melhorar as propriedades de identificação ao introduzir variação exógena adicional [@anselin1988spatial].
Assumindo que \((\mathbf{I}_n - \rho \mathbf{W}_1)\) e \((\mathbf{I}_n - \lambda \mathbf{W}_2)\) são não singulares, a forma reduzida do modelo é obtida por substituição:
Esta expressão revela a estrutura do processo gerador de dados:
\(\mathbb{E}[\mathbf{y} \, | \, \mathbf{X}] = (\mathbf{I}_n - \rho \mathbf{W}_1)^{-1}\mathbf{X}\boldsymbol{\beta}\). A interpretação dos efeitos marginais das variáveis explicativas segue a mesma lógica do modelo SAR, com a decomposição em efeitos diretos, indiretos e totais via o multiplicador espacial \((\mathbf{I}_n - \rho \mathbf{W}_1)^{-1}\)[@lesage2009introduction].
\(\operatorname{Cov}(\mathbf{y} \, | \, \mathbf{X}) = \sigma^2 [(\mathbf{I}_n - \rho \mathbf{W}_1)^{\top}(\mathbf{I}_n - \lambda \mathbf{W}_2)^{\top}(\mathbf{I}_n - \lambda \mathbf{W}_2)(\mathbf{I}_n - \rho \mathbf{W}_1)]^{-1}\). A estrutura de dependência estocástica resulta de uma dupla filtragem espacial: os choques \(\boldsymbol{\epsilon}\) são primeiro filtrados pelo processo de erro (\(\lambda\)) e depois propagados pelo mecanismo autorregressivo da variável dependente (\(\rho\)).
A presença simultânea da variável dependente defasada (\(\mathbf{W}_1\mathbf{y}\)) e da autocorrelação nos erros torna o estimador de Mínimos Quadrados Ordinários (MQO) inconsistente e ineficiente. Os métodos de estimação padrão são:
máxima verossimilhança, onde Sob a suposição de normalidade dos erros, a função de log-verossimilhança é:
\[
\begin{aligned}
\ln L(\boldsymbol{\beta}, \rho, \lambda, \sigma^2) &= C + \ln|\mathbf{I}_n - \rho \mathbf{W}_1| + \ln|\mathbf{I}_n - \lambda \mathbf{W}_2| - \frac{n}{2}\ln(\sigma^2) - \frac{1}{2\sigma^2} \boldsymbol{\epsilon}(\rho, \lambda)^{\top} \boldsymbol{\epsilon}(\rho, \lambda),
\end{aligned}
\] onde \(\boldsymbol{\epsilon}(\rho, \lambda) = (\mathbf{I}_n - \lambda \mathbf{W}_2)[(\mathbf{I}_n - \rho \mathbf{W}_1)\mathbf{y} - \mathbf{X}\boldsymbol{\beta}]\). A maximização requer o cálculo de dois determinantes Jacobianos, o que pode ser computacionalmente intensivo para grandes amostras.
Método Generalizado dos Momentos (GMM) / Mínimos Quadrados em Dois Estágios Espaciais Generalizados (GS2SLS), desenvolvida por @kelejian1998generalized e @kelejian1999generalized, não exige suposições distribucionais fortes e evita o cálculo de determinantes. O procedimento é iterativo:
No primeiro estágio (2SLS) estima-se a equação estrutural ignorando inicialmente a autocorrelação do erro. Utilizam-se como instrumentos para \(\mathbf{W}_1\mathbf{y}\) as variáveis \(\mathbf{H} = [\mathbf{X}, \mathbf{W}_1\mathbf{X}, \mathbf{W}_1^2\mathbf{X}, \dots]\), obtendo estimativas consistentes de \(\rho\) e \(\boldsymbol{\beta}\) e os resíduos \(\hat{\mathbf{u}}\).
Estimação de \(\lambda\) utilizando um estimador GMM baseado nos momentos dos resíduos \(\hat{\mathbf{u}}\) para obter uma estimativa consistente de \(\lambda\).
Transformação e estimação, na qual aplica-se a transformação de Cochrane-Orcutt espacial aos dados para eliminar a autocorrelação, usando \(\hat{\lambda}\). A equação transformada é então reestimada via 2SLS, produzindo estimativas finais eficientes.
O modelo SARAR é a especificação preferencial quando evidências empíricas (testes de Multiplicador de Lagrange robustos) indicam a presença conjunta de dependência espacial substantiva e dependência residual. Ele oferece um controle robusto para a heterogeneidade espacial não observada enquanto captura os mecanismos de interação de interesse.
Enquanto as especificações de dependência única (SAR, SEM) e suas generalizações com defasagens exógenas (SDM, SDEM) atingiram um patamar de ajuste estacionário, com AICs oscilando em torno de \(5213\) (Table 10), o modelo SARAR (Table 10 ) reduziu o critério de informação para \(5200.4\). Esta melhoria no ajuste é suportada pela significância estatística simultânea de ambos os parâmetros de dependência: uma forte autoregressão espacial positiva capturada por \(\rho\) (\(0.698\); \(IC_{95\%} [0.587, 0.809]\)) e um ajuste corretivo nos resíduos evidenciado por um \(\lambda\) negativo significante (\(-0.558\); \(IC_{95\%} [-0.767, -0.349]\)). Adicionalmente, a tabela reforça a robustez da inferência sobre a covariável \(X\): em todas as sete especificações testadas desde o OLS básico até o complexo SARAR o coeficiente \(\beta\) e seus transbordamentos locais (\(\theta\)) permaneceram estatisticamente nulos, consolidando a evidência de que a estrutura dos dados é dominada por dinâmicas espaciais endógenas e estocásticas, independentes da variável explicativa proposta.
Code
set.seed(123)imp_sarar <-impacts(mod_sarar, listw = lw, R =1000)if (is.null(imp_sarar$res)) { imp_sarar <-impacts(mod_sarar, listw = lw, R =1000, zstats =TRUE)}df_impactos <-data.frame(direct = imp_sarar$res$direct,indirect = imp_sarar$res$indirect) %>%pivot_longer(cols =everything(), names_to ="Tipo", values_to ="Valor") %>%mutate(Tipo =factor(Tipo, levels =c("direct", "indirect"),labels =c("Direto", "Indireto (Spillover Global)")))g_impactos <-ggplot(df_impactos, aes(x = Tipo, fill = Tipo, y=Valor)) +geom_col(width =0.2, color ="gray30") +scale_fill_manual(values =c("Direto"="#1b9e77", "Indireto (Spillover)"="#d95f02")) +labs(title ="A. Impactos: Direto vs. Indireto", y ="Magnitude do efeito", x =NULL) +theme_minimal() +theme(legend.position ="none", legend.title =element_blank())# Mapa dos Valores Ajustadosmg_dados$fitted_sarar <-fitted(mod_sarar)g_fit <-ggplot(mg_dados) +geom_sf(aes(fill = fitted_sarar), color =NA) +scale_fill_viridis_c(option ="turbo", name ="Predito") +labs(title ="B. Valores Preditos (SARAR)", subtitle =expression("Ajuste simultâneo"~ (rho + lambda))) +theme_minimal() +annotation_scale(location ="bl", width_hint =0.3, bar_cols =c("black", "white")) +annotation_north_arrow(location ="tl", style = north_arrow_fancy_orienteering,pad_x =unit(0.1, "in"), pad_y =unit(0.1, "in"))# Diagnóstico dos Resíduosmg_dados$resid_sarar <-residuals(mod_sarar)moran_sarar <-moran.test(mg_dados$resid_sarar, lw)mg_dados$resid_lag_sarar <-lag.listw(lw, mg_dados$resid_sarar)g_resid_scatter <-ggplot(mg_dados, aes(x = resid_sarar, y = resid_lag_sarar)) +geom_hline(yintercept =0, linetype ="dashed", color ="gray") +geom_vline(xintercept =0, linetype ="dashed", color ="gray") +geom_point(alpha =0.3) +geom_smooth(method ="lm", se =FALSE, color ="red", size =0.8) +labs(title ="C. Scatter de Moran (Resíduos SARAR)", subtitle =paste0("I de Moran: ", round(moran_sarar$estimate[1], 3), " (p-valor: ", round(moran_sarar$p.value, 3), ")"),x ="Resíduos", y ="Lag Espacial") +theme_minimal()(g_impactos | g_fit | g_resid_scatter)
1.13.7 Modelo de Média Móvel Espacial (SMA – Spatial Moving Average)
O modelo de Média Móvel Espacial (SMA) oferece uma abordagem alternativa para a modelagem da dependência espacial no termo de erro. Enquanto o modelo SEM especifica um processo autorregressivo que induz uma dependência de longo alcance, o SMA postula que a dependência espacial é um fenômeno estritamente local e de curto alcance.
Embora menos comum na literatura aplicada que os modelos SAR ou SEM, o SMA é relevante para testar hipóteses sobre a extensão geográfica das interdependências. O modelo é especificado pela seguinte estrutura [@anselin1988spatial; @haining2003spatial]:
Onde \(\lambda\) é o coeficiente de média móvel espacial.
A distinção fundamental entre o SMA e os modelos autorregressivos (SAR, SEM) reside na estrutura de propagação dos choques estocásticos.
Nos modelos autorregressivos, a dependência é modelada através da inversa de uma matriz de filtro espacial, por exemplo, \((\mathbf{I}_n - \lambda \mathbf{W})^{-1}\). A expansão em série de Neumann desta inversa, \((\mathbf{I}_n - \lambda \mathbf{W})^{-1} = \mathbf{I}_n + \lambda \mathbf{W} + \lambda^2 \mathbf{W}^2 + \cdots\), implica que um choque em uma unidade \(i\) afeta seus vizinhos diretos (\(\lambda \mathbf{W}\)), os vizinhos dos vizinhos (\(\lambda^2 \mathbf{W}^2\)), e assim sucessivamente, propagando-se por todo o sistema, ainda que com intensidade decrescente [@elhorst2014spatial]. Isso caracteriza uma dependência de longo alcance.
No modelo SMA, não há inversão de matriz na definição do erro \(\mathbf{u}\). Um choque \(\epsilon_i\) afeta diretamente a unidade \(i\) e, através do termo \(\lambda \mathbf{W}\boldsymbol{\epsilon}\), afeta apenas os vizinhos imediatos de \(i\) (aqueles para os quais \(w_{ij} \neq 0\)). O efeito é contido na primeira ordem de vizinhança; não há mecanismo de retransmissão para unidades mais distantes.
A natureza local do SMA é explicitamente descrita por sua matriz de covariância. Dado que \(\mathbf{u} = (\mathbf{I}_n + \lambda \mathbf{W}) \boldsymbol{\epsilon}\), a matriz de covariância de \(\mathbf{u}\) (condicional a \(\mathbf{X}\)) é:
A covariância entre \(u_i\) e \(u_j\) é não nula se \(w_{ij} \neq 0\) (são vizinhos diretos) ou se \(w_{ji} \neq 0\) (para \(\mathbf{W}\) não simétrica).
O elemento \((i, j)\) da matriz \(\mathbf{W}\mathbf{W}^{\top}\) é não nulo se existe pelo menos uma unidade \(k\) tal que \(w_{ik} \neq 0\) e \(w_{jk} \neq 0\). Ou seja, se as unidades \(i\) e \(j\) compartilham pelo menos um vizinho comum.
Portanto, no modelo SMA, a correlação espacial é efetivamente nula para qualquer par de unidades que não sejam vizinhas diretas nem compartilhem um vizinho comum (vizinhos de segunda ordem). Isto contrasta com o SEM, onde a matriz de covariância é teoricamente densa, implicando correlação não nula (embora pequena) entre todos os pares de unidades no sistema.
Assim como no SEM, o estimador de Mínimos Quadrados Ordinários (MQO) para \(\boldsymbol{\beta}\) no modelo SMA é não viesado e consistente sob a exogeneidade de \(\mathbf{X}\). No entanto, é ineficiente na presença de autocorrelação espacial (\(\lambda \neq 0\)), e as estimativas dos erros-padrão obtidas pelo procedimento MQO padrão são viesadas, invalidando a inferência estatística habitual [@anselin1988spatial].
A estimação eficiente tipicamente requer o método de máxima verossimilhança. A função de log-verossimilhança assume a forma:
onde \(\boldsymbol{\Omega}(\lambda) = (\mathbf{I}_n + \lambda \mathbf{W})(\mathbf{I}_n + \lambda \mathbf{W})^{\top}\). A complexidade computacional reside no cálculo do determinante e da inversa de \(\boldsymbol{\Omega}(\lambda)\). Diferentemente dos modelos autorregressivos, que envolvem o determinante de \((\mathbf{I}_n - \lambda \mathbf{W})\), o SMA requer o cálculo do determinante de \((\mathbf{I}_n + \lambda \mathbf{W})\).
Para garantir que o processo seja invertível e a matriz de covariância seja positiva definida, são impostas restrições no espaço do parâmetro \(\lambda\). Geralmente, exige-se que \(|\lambda| < 1 / |\omega_{max}|\), onde \(\omega_{max}\) é o maior autovalor de \(\mathbf{W}\) em módulo [@hepple1979bayesian; @anselin1988spatial].
O uso do SMA é recomendado quando a análise exploratória dos dados (por exemplo, correlogramas espaciais ou testes de dependência para diferentes ordens de vizinhança) indica um decaimento abrupto da correlação espacial após a primeira defasagem, em contraste com o decaimento suave e prolongado característico dos processos autorregressivos.
Table 11: Comparação entre ajuste dos modelos OLS, SLX, SAR, SEM, SDM, SDEM, SARAR e SMA. Estimativas [IC 95%].
OLS
SLX
SAR
SEM
SDM
SDEM
SARAR
SMA
Intercepto
8.973 [8.616, 9.330]
8.970 [8.613, 9.327]
5.751 [4.876, 6.626]
8.978 [8.449, 9.507]
5.748 [4.873, 6.622]
8.974 [8.444, 9.503]
2.715 [1.695, 3.735]
8.975 [8.499, 9.450]
\(\beta\)
0.058 [−0.306, 0.422]
0.056 [−0.308, 0.420]
0.029 [−0.316, 0.374]
−0.001 [−0.342, 0.340]
0.027 [−0.318, 0.372]
0.060 [−0.297, 0.417]
0.065 [−0.243, 0.373]
0.001 [−0.343, 0.345]
WX \(\theta\)
0.397 [−0.396, 1.190]
0.391 [−0.361, 1.143]
0.496 [−0.366, 1.359]
\(\rho\)
0.359 [0.269, 0.449]
0.359 [0.270, 0.449]
0.698 [0.587, 0.809]
\(\lambda\)
0.359 [0.270, 0.449]
0.360 [0.270, 0.450]
−0.558 [−0.767, −0.349]
0.363
N
853
853
853
\(R^2\)
0.000
0.001
AIC
5275.0
5276.1
5212.9
5213.0
5213.9
5213.7
5200.4
5221.0
Log Likelihood
−2634.5
−2634.0
−2606.5
* p < 0.05, ** p < 0.01, *** p < 0.001
Code
# Mapamg_dados$fitted_sma <-fitted(mod_sma)g_fit <-ggplot(mg_dados) +geom_sf(aes(fill = fitted_sma), color =NA) +scale_fill_viridis_c(option ="turbo", name ="Predito") +labs(title ="A. Valores Preditos (SMA)") +theme_minimal() +annotation_scale(location ="bl", width_hint =0.3) +annotation_north_arrow(location ="tl", style = north_arrow_fancy_orienteering)#Resíduosmg_dados$resid_sma <-residuals(mod_sma)moran_sma <-moran.test(mg_dados$resid_sma, lw)mg_dados$resid_lag_sma <-lag.listw(lw, mg_dados$resid_sma)g_resid_scatter <-ggplot(mg_dados, aes(x = resid_sma, y = resid_lag_sma)) +geom_hline(yintercept =0, linetype ="dashed", color ="gray") +geom_vline(xintercept =0, linetype ="dashed", color ="gray") +geom_point(alpha =0.3) +geom_smooth(method ="lm", se =FALSE, color ="red", size =0.8) +labs(title ="B. Scatter de Moran (Resíduos SMA)", subtitle =paste0("I de Moran: ", round(moran_sma$estimate[1], 3), " (p-valor: ", round(moran_sma$p.value, 3), ")"),x ="Resíduos", y ="Lag Espacial") +theme_minimal()( g_fit | g_resid_scatter)
Figure 21: Diagnóstico SMA: (A) Ajuste e (B) Resíduos.
1.14 Modelos espaciais para respostas limitadas e discretas
1.14.1 Modelo Probit Espacial
O Modelo Probit Espacial é aplicado quando a variável dependente observada \(y_i\) é binária (\(y_i \in \{0, 1\}\)) e existe interdependência espacial entre as unidades de observação.
A formulação comum para o modelo Probit Espacial Autorregressivo (SAR Probit) baseia-se numa variável latente contínua não observada, \(y_i^*\). Assume-se que esta variável latente segue um processo autorregressivo espacial:
Aqui, \(\mathbf{W}\) é a matriz de pesos espaciais, \(\rho\) é o parâmetro de autocorrelação espacial, \(\mathbf{X}\) é a matriz de covariáveis e \(\boldsymbol{\beta}\) o vetor de coeficientes. A variância do erro \(\epsilon_i\) é fixada em 1 para identificação do modelo Probit [@lesage2009introduction].
Resolvendo a equação estrutural para o vetor latente \(\mathbf{y}^*\), obtém-se sua forma reduzida:
Define-se \(\tilde{\boldsymbol{\epsilon}} = (\mathbf{I}_n - \rho \mathbf{W})^{-1}\boldsymbol{\epsilon}\). A estrutura de covariância deste termo de erro composto é:
A diagonal desta matriz de covariância não é constante. Cada elemento diagonal, \(\tilde{\sigma}_i^2\), varia em função da posição da unidade \(i\) na rede espacial, conforme definida por \(\mathbf{W}\). Consequentemente, o modelo de variável latente exibe heterocedasticidade induzida espacialmente. A aplicação de um estimador Probit padrão, que assume homocedasticidade (\(\tilde{\sigma}_i^2 = 1\) para todo \(i\)), a dados gerados por este processo, produz estimativas inconsistentes dos parâmetros \(\rho\) e \(\boldsymbol{\beta}\)[@mcmillen1992probit; @calabrese2014estimators].
A função de verossimilhança para o modelo Probit Espacial é a probabilidade conjunta de observar a amostra \(\mathbf{y} = (y_1, \ldots, y_n)^{\top}\). Esta probabilidade requer o cálculo de uma integral \(n\)-dimensional sobre uma distribuição normal multivariada restrita a ortantes definidos pelos valores observados \(y_i\):
onde \(\boldsymbol{\mu} = (\mathbf{I}_n - \rho \mathbf{W})^{-1}\mathbf{X}\boldsymbol{\beta}\), \(\boldsymbol{\Omega} = [(\mathbf{I}_n - \rho \mathbf{W})(\mathbf{I}_n - \rho \mathbf{W})^{\top}]^{-1}\), e \(R_i = (-\infty, 0]\) se \(y_i = 0\) e \(R_i = (0, \infty)\) se \(y_i = 1\). Para amostras de tamanho moderado ou grande, o cálculo numérico direto desta integral é computacionalmente proibitivo [@fleming2004techniques].
A literatura desenvolveu várias estratégias para superar esta intratabilidade:
Algoritmo EM (Expectation-Maximization): Proposto por @mcmillen1992probit, este método trata o vetor latente \(\mathbf{y}^*\) como dados faltantes. O algoritmo itera entre um passo E, que calcula a esperança de \(\mathbf{y}^*\) condicional nos parâmetros atuais e em \(\mathbf{y}\), e um passo M, que maximiza a verossimilhança de um modelo espacial linear contínuo. Apesar de fornecer estimativas consistentes, a obtenção de erros-padrão válidos é complexa.
Método Generalizado dos Momentos (GMM): @pinkse1998contracting desenvolveram um estimador GMM baseado nos resíduos generalizados do modelo Probit. @klier2008clustering propuseram uma versão linearizada (LGMM), computacionalmente eficiente e adequada para grandes conjuntos de dados, embora potencialmente sujeita a viés quando a dependência espacial \(\rho\) é forte [@calabrese2014estimators].
Simulação recursiva de importância (GHK): @beron2004probit implementaram a estimação de máxima verossimilhança simulada usando o simulador GHK (Geweke-Hajivassiliou-Keane) para aproximar a integral \(n\)-dimensional. Este método é preciso, mas seu custo computacional cresce consideravelmente com o tamanho da amostra.
Abordagem Bayesiana (MCMC): Consolidada por @lesage2000bayesian, esta abordagem emprega métodos de Monte Carlo via Cadeias de Markov (MCMC). Utiliza-se uma estratégia de aumento de dados (data augmentation), na qual o vetor latente \(\mathbf{y}^*\) é tratado como um parâmetro a ser amostrado sequencialmente de uma distribuição normal multivariada truncada, condicional aos valores observados \(\mathbf{y}\) e aos parâmetros do modelo. Esta é frequentemente considerada a abordagem mais precisa para amostras finitas, fornecendo a distribuição completa a posteriori dos parâmetros [@calabrese2014estimators; @wilhelm2013estimating].
Aproximações e Verossimilhança Parcial: Para grandes conjuntos de dados, métodos aproximados ganham relevância. Destacam-se a aproximação de verossimilhança via método de Mendell-Elston [@martinetti2017approximate], a verossimilhança parcial por pares [@bille2020partial], e técnicas de amostragem por importância eficiente (EIS) que exploram a esparsidade da matriz de precisão [@liesenfeld2013analysis].
Em modelos Probit Espaciais, os coeficientes \(\boldsymbol{\beta}\) não possuem uma interpretação direta como efeitos marginais sobre a probabilidade \(P(y_i = 1)\), devido à não linearidade da função de ligação Probit e à presença do multiplicador espacial global \((\mathbf{I}_n - \rho \mathbf{W})^{-1}\).
A análise deve concentrar-se nos efeitos médios diretos, indiretos (de transbordamento) e totais [@lesage2009introduction]. Um cambio em uma covariável \(x_{ik}\) não afeta apenas a probabilidade na unidade \(i\), mas também se propaga através da rede, afetando as probabilidades em todas as outras unidades \(j \neq i\). Estes efeitos são não lineares e variam entre observações. Prática comum resume-os através das médias amostrais dos efeitos calculados para cada unidade, fornecendo uma medida sumária do impacto global de cada variável explicativa.
A Tabela Table 12 apresenta as estimativas estruturais modelo Probit ajustado. Observa-se que a Variável \(X\) exerce um efeito positivo (\(2.274\); \(IC_{95\%} [1.677, 2.909]\)), indicando que elevações nesta covariável aumentam significativamente a probabilidade de classificação nos estratos superiores da resposta ordinal. A dependência espacial, mensurada pelo parâmetro \(\rho\) (\(0.707\); \(IC_{95\%} [0.649, 0.761]\)), demonstra que a categoria observada em uma unidade espacial é fortemente condicionada pelo perfil de sua vizinhança, validando a presença de feedback espacial no processo gerador dos dados.
A análise comparativa entre a distribuição dos eventos observados (Figure 22 C) e as probabilidades preditas (Figure 22 D) indica que o modelo probit identificou as zonas de maior suscetibilidade, recuperando o padrão geográfico do fenômeno. O efeito indireto (\(0.192\); Figure 22 A) supera o efeito direto (\(0.073\); Figure 22 A), sugerindo que a alteração na probabilidade do evento local depende preponderantemente das características das vizinhanças. Entretanto, o diagnóstico dos resíduos apresentado em Figure 22 (B) evidencia uma violação do pressuposto de independência condicional. A estatística de I de Moran global aplicada aos resíduos (\(I = 0.076\)), estatisticamente significativa (\(p \approx 0\)), aponta para a persistência de autocorrelação espacial positiva não capturada pelo termo de defasagem, indicando que a especificação atual é insuficiente para filtrar a totalidade da dependência espacial latente.
1.14.2 Modelo Probit Ordenado Espacial
O Modelo Probit Ordenado Espacial é uma extensão para dados categóricos ordenados em contextos espaciais. Ele é adequado quando a variável dependente observada, \(y_i\), assume valores em categorias ordenadas, como classificações de intensidade, níveis de satisfação ou escalas de severidade, e existe interdependência espacial entre as unidades de observação.
A premissa central do modelo é que a variável categórica ordenada observada é uma manifestação censurada de uma variável latente contínua subjacente, \(y_i^*\), que representa uma propensão ou utilidade não observada. A dependência espacial é modelada diretamente no processo gerador desta variável latente.
Seguindo a estrutura autorregressiva espacial, a equação estrutural para a variável latente é especificada como [@lesage2009introduction; @wang2009baysian]:
A variável observada \(y_i\) está relacionada com sua contraparte latente através de um conjunto de limiares ordenados, \(\gamma = (\gamma_0, \gamma_1, \dots, \gamma_J, \gamma_{J+1})'\). Para uma observação \(i\) com \(J+1\) categorias possíveis (\(j = 0, 1, \dots, J\)):
\[
y_i = j \quad \text{se, e somente se,} \quad \gamma_j < y_i^* \le \gamma_{j+1}.
\]
Para identificação do modelo, fixam-se os valores \(\gamma_0 = -\infty\), \(\gamma_1 = 0\) e \(\gamma_{J+1} = \infty\). Os limiares restantes, \(\gamma_2, \dots, \gamma_J\), são parâmetros desconhecidos a serem estimados, sujeitos à restrição de ordenamento \(\gamma_2 < \gamma_3 < \dots < \gamma_J\). A variância do erro \(\epsilon_i\) é fixada em 1, conforme convenção padrão em modelos Probit.
Resolvendo a equação estrutural para o vetor latente \(\mathbf{y}^*\), obtém-se sua forma reduzida:
Esta matriz é não diagonal e seus elementos diagonais, \(\sigma_i^2 = \boldsymbol{\Omega}_{ii}\), não são constantes. Eles variam em função da posição de cada unidade \(i\) na estrutura de vizinhança definida por \(\mathbf{W}\). Consequentemente, o modelo exibe heterocedasticidade induzida espacialmente. A aplicação de um estimador Probit Ordenado padrão, que assume independência e homocedasticidade, a dados gerados por este processo resulta em estimadores inconsistentes para \(\boldsymbol{\beta}\), \(\rho\) e \(\boldsymbol{\gamma}\), comprometendo a inferência [@wang2009baysian].
A função de verossimilhança do modelo envolve o cálculo de probabilidades de uma distribuição normal multivariada restrita a ortantes definidos pelos limiares, uma tarefa computacionalmente intratável para amostras de tamanho moderado. A abordagem Bayesiana, utilizando métodos de Monte Carlo via Cadeias de Markov (MCMC) com aumento de dados (data augmentation), supera esta dificuldade e tornou-se o método padrão [@lesage2009introduction].
O algoritmo de amostragem de Gibbs itera entre os seguintes passos, amostrando de cada distribuição condicional completa:
Variável Latente (\(\mathbf{y}^*\)): Condicional aos parâmetros \((\boldsymbol{\beta}, \rho, \boldsymbol{\gamma})\) e aos dados observados \(\mathbf{y}\), cada \(y_i^*\) é amostrado de uma distribuição normal univariada truncada. O suporte de truncagem é o intervalo \((\gamma_{y_i}, \gamma_{y_i+1}]\), determinado pela categoria observada \(y_i\). A média e variância condicionais de \(y_i^*\) dependem dos valores latentes atuais das unidades vizinhas, requerendo algoritmos eficientes como o de Geweke para a amostragem.
Parâmetros de regressão e espacial (\(\boldsymbol{\beta}, \rho\)): Condicional ao vetor latente completo \(\mathbf{y}^*\), o modelo reduz-se a um modelo autorregressivo espacial (SAR) linear contínuo. Os parâmetros \(\boldsymbol{\beta}\) são amostrados de uma distribuição normal multivariada, e \(\rho\) é amostrado via um passo de Metropolis-Hastings, utilizando suas distribuições condicionais completas padrão.
Parâmetros de limiar (\(\boldsymbol{\gamma}\)): Condicional a \(\mathbf{y}^*\), os limiares \(\gamma_j\) (para \(j=2, \dots, J\)) são amostrados de distribuições uniformes em intervalos restritos. O intervalo para \(\gamma_j\) é determinado pelos valores latentes das observações nas categorias adjacentes: \[
\gamma_j \mid \mathbf{y}^*, \mathbf{y} \sim \mathcal{U}\left( \max_{\{i: y_i = j-1\}} y_i^*, \min_{\{i: y_i = j\}} y_i^* \right).
\] Para garantir uma boa mistura da cadeia de Markov, emprega-se frequentemente o algoritmo de Cowles (1996) [@tobias2024note].
A interpretação dos coeficientes \(\boldsymbol{\beta}\) no modelo Probit Ordenado Espacial não é direta. O sinal de \(\beta_k\) indica a direção do efeito da variável \(x_k\) sobre a variável latente \(y_i^*\), mas o efeito sobre as probabilidades das categorias observadas \(P(y_i = j)\) é ambíguo e depende dos limiares estimados \(\boldsymbol{\gamma}\)[@Greene2003Econometric]. Além disso, a presença do multiplicador espacial \((\mathbf{I}_n - \rho \mathbf{W})^{-1}\) implica que uma mudança em uma covariável para a unidade \(i\) gera efeitos de transbordamento (spillovers) sobre as probabilidades de todas as outras unidades.
Portanto, a análise deve concentrar-se nos efeitos marginais espaciais para cada categoria \(j\). O efeito marginal de uma mudança na covariável \(x_{rk}\) (da unidade \(r\)) sobre a probabilidade da unidade \(i\) pertencer à categoria \(j\) é dado por:
onde \(\mu_i\) é o i-ésimo elemento do vetor \((\mathbf{I}_n - \rho \mathbf{W})^{-1}\mathbf{X}\boldsymbol{\beta}\), \(\sigma_i = \sqrt{\boldsymbol{\Omega}_{ii}}\), e \(\phi(\cdot)\) é a função de densidade da normal padrão. O termo \(\left[ (\mathbf{I}_n - \rho \mathbf{W})^{-1} \beta_k \right]_{ir}\) representa o elemento \((i, r)\) da matriz de multiplicador espacial ponderada por \(\beta_k\).
Estes efeitos são decompostos em:
Efeito direto médio: O impacto médio de uma mudança em \(x_{ik}\) sobre a probabilidade da própria unidade \(i\) estar na categoria \(j\).
Efeito indireto (ou de Transbordamento) médio: O impacto médio cumulativo de uma mudança em \(x_{ik}\) sobre as probabilidades de todas as outras unidades \(r \neq i\) estarem na categoria \(j\).
Efeito total médio: A soma dos efeitos direto e indireto.
Dada a não linearidade do modelo, estes efeitos variam para cada observação. A prática padrão é reportar as médias amostrais dos efeitos diretos, indiretos e totais para cada categoria \(j\), juntamente com medidas de incerteza (como intervalos de credibilidade) obtidas a partir das amostras da cadeia MCMC.
A Tabela Table 13 apresenta os parâmetros estruturais do modelo. A covariável \(X\) exerce uma influência positiva sobre a variável latente (\(0.863\); \(IC_{95\%} [0.762, 0.963]\)), indicando que elevações nesta preditora aumentam a probabilidade de classificação nos estratos ordinais superiores. Simultaneamente, a dependência espacial é confirmada pela estimativa de \(\rho\) (\(0.437\); \(IC_{95\%} [0.331, 0.537]\)), demonstrando que o nível ordenado de uma observação é positivamente correlacionado com o status de sua vizinhança geográfica. A calibração dos limiares (thresholds), especificamente o parâmetro de corte \(y \ge 3\) (\(0.865\); \(IC_{95\%} [0.802, 0.941]\)), define as fronteiras probabilísticas que segregam as categorias mais elevadas da distribuição.
Code
#if (!require("pacman")) install.packages("pacman")pacman::p_load(spatialprobit, spdep, sf, geobr, ggplot2, viridis, kableExtra, dplyr, Matrix, patchwork, ggspatial, scales, truncnorm)# Cálculo dos Impactos (Médios)rho_medio <-mean(mod_sar_ordered$rho)beta_val <- resumo_bayesiano$Estimativa[resumo_bayesiano$Parametro =="Variável X"]impacto_total <- beta_val / (1- rho_medio)impacto_direto <- beta_val impacto_indireto <- impacto_total - impacto_diretodf_imp <-data.frame(Tipo =factor(c("direct", "indirect", "total"), levels =c("direct", "indirect", "total"),labels =c("Direto", "Indireto", "Total")),Valor =c(impacto_direto, impacto_indireto, impacto_total))# PREDIÇÃO E CLASSIFICAÇÃO sp_dados$latente_predita <-as.vector(fitted(mod_sar_ordered))#Definição dos Cortes (Breaks): O vetor 'phi' contém os limites: 0 (fixo) e o valor estimadobreaks_finais <-c(-Inf, mod_sar_ordered$phi, Inf)#Classificaçãosp_dados$cat_predita_class <-cut(sp_dados$latente_predita, breaks = breaks_finais, labels =FALSE)#if(any(is.na(sp_dados$cat_predita_class))) { sp_dados$cat_predita_class[is.na(sp_dados$cat_predita_class)] <-1}#CÁLCULO DOS RESÍDUOS GENERALIZADOS#Chesher, A. and Irish, M., 1987. Residual analysis in the grouped and censored normal linear model. Journal of Econometrics, 34(1-2), pp.33-61.#Gourieroux, C., Monfort, A., Renault, E. and Trognon, A., 1987. Generalised residuals. Journal of econometrics, 34(1-2), pp.5-32.beta_hat <- resumo_bayesiano$Estimativa[resumo_bayesiano$Parametro =="Variável X"] intercepto <- resumo_bayesiano$Estimativa[resumo_bayesiano$Parametro =="Intercepto"]rho_hat <-mean(mod_sar_ordered$rho)cuts <-c(-Inf, 0, mod_sar_ordered$phi, Inf) # Cuts: 0 é fixo no spatialprobit#y* = (I - rho*W)^-1 * (X*beta)X_mat <-model.matrix(~ x_var, data = sp_dados) betas_vec <-c(intercepto, beta_hat) # Ordem deve bater com X_mat#X * Betaxb <- X_mat %*% betas_vec#(I - rho * W)^-1I_n <- Matrix::Diagonal(nrow(sp_dados)) #IS_inv <-solve(I_n - rho_hat * W_mat) #(I - rho * W)^-1y_star_pred <-as.vector(S_inv %*% xb) #(I - rho * W)^-1 *xb#E[y* | y_obs]: mu + sigma * (pdf(a) - pdf(b)) / (cdf(b) - cdf(a))y_obs <-as.numeric(sp_dados$y_ordered)lo <- cuts[y_obs] # Limite inferior da categoria observadahi <- cuts[y_obs +1] # Limite superior da categoria observadaz_lo <- lo - y_star_predz_hi <- hi - y_star_predsafe_pnorm <-function(q) pnorm(q)safe_dnorm <-function(x) dnorm(x)diff_cdf <-safe_pnorm(z_hi) -safe_pnorm(z_lo)diff_cdf[diff_cdf <1e-10] <-1e-10diff_pdf <-safe_dnorm(z_lo) -safe_dnorm(z_hi) # Note a ordem: pdf(lo) - pdf(hi)# E[y* | y] = mu + (phi(lo) - phi(hi)) / (Phi(hi) - Phi(lo))sp_dados$y_latente_esperada <- y_star_pred + (diff_pdf / diff_cdf)# u = (I - rho*W) * E[y*|y] - X*betaA_mat <- (I_n - rho_hat * W_mat)term_spatial_removed <-as.vector(A_mat %*% sp_dados$y_latente_esperada)sp_dados$resid_generalized <- term_spatial_removed -as.vector(xb)#Teste de Moranmoran_resid <-moran.test(sp_dados$resid_generalized, lw_sp)label_moran <-paste0("Moran (Gen. Resid): ", round(moran_resid$estimate[1], 3), " (p: ", round(moran_resid$p.value, 3), ")")max_res <-max(abs(sp_dados$resid_generalized), na.rm=TRUE)# Graficostheme_map_custom <-function() {list(theme_void(),theme(legend.position ="bottom", legend.box.spacing =unit(5, "pt"),legend.title =element_text(size=9, face="bold"),plot.title =element_text(face="bold", size=12, hjust =0),plot.subtitle =element_text(size=9, color="grey30") ),annotation_scale(location ="br", width_hint =0.3),annotation_north_arrow(location ="tr", height =unit(1, "cm"), width =unit(1, "cm"),style = north_arrow_fancy_orienteering) )}#Observadog_obs <-ggplot(sp_dados) +geom_sf(aes(fill =factor(y_ordered, levels =1:3)), color ="white", lwd =0.02) +scale_fill_viridis_d(option ="viridis", name ="Observed", drop =FALSE) +labs(title ="A. Dados Observados", subtitle ="Variável Dependente Real") +theme_map_custom()#Preditog_pred <-ggplot(sp_dados) +geom_sf(aes(fill =factor(cat_predita_class, levels =1:3)), color ="white", lwd =0.02) +scale_fill_viridis_d(option ="viridis", name ="Predicted", drop =FALSE) +labs(title ="B. Predição do Modelo") +theme_map_custom()#Impactosg_imp <-ggplot(df_imp, aes(x = Tipo, y = Valor, fill = Tipo)) +geom_col(width =0.6, color ="black", alpha =0.8) +geom_text(aes(label =round(Valor, 2)), vjust =-0.5, size=4, fontface ="bold") +scale_fill_viridis_d(option ="cividis", begin =0.2, end =0.8) +labs(title ="C. Decomposição de Impactos", y ="Magnitude", x =NULL) +theme_minimal() +theme(legend.position ="none", panel.grid.minor =element_blank())#Resíduosmax_res <-max(abs(sp_dados$resid_generalized), na.rm=TRUE)g_resid <-ggplot(sp_dados) +geom_sf(aes(fill = resid_generalized), color ="white", lwd =0.02) +scale_fill_distiller(palette ="RdBu", direction =-1, limits =c(-max_res, max_res),name ="Resíduo") +labs(title ="D. Resíduos", subtitle =paste0("Autocorrelação:\n", label_moran)) +theme_map_custom()g_obs+g_pred+g_imp+g_resid
Figure 23: (A) Observado, (B) Predito, (C) Impactos e (D) Resíduos Generalizados (Estimativa do erro estrutural).
Interpretação
Os padrões observados em Figure 23 (A) e as estimativas do modelo em Figure 23 (B), demonstram a eficácia da especificação modelo probit ordinal na recuperação da estrutura espacial das categorias, replicando com fidelidade a heterogeneidade e as aglomerações regionais. A decomposição dos impactos ilustrada em Figure 23 (C) revela que a dinâmica do fenômeno é governada preponderantemente por fatores intra-regionais, uma vez que a magnitude do efeito direto (\(0.86\)) supera a do efeito indireto (\(0.67\)), embora a influência do transbordamento espacial permaneça substantiva. A validade estatística das inferências é assegurada em Figure 23 (D), onde a análise dos resíduos generalizados atesta a ausência de padrões espaciais sistemáticos; a estatística de I de Moran (\(-0.077\)) associada ao p-valor unitário (\(p=1\)) confirma que o modelo filtrou adequadamente a autocorrelação espacial, garantindo a independência estocástica dos erros.
NoteEstimativas do Modelo SAR Probit Ordenado
Para ajustar o modelo certifique-se de que \(\mathbf{y}^*\) (seja discreta), \(\mathbf{y}^* \in \{1, \dots, J\}\). Após ajustar o modelo, os resultados não serão categóricos, e sim quantitativos contínuos. A transição da escala contínua para as categorias discretas observadas \(\mathbf{y}^* \in \{1, \dots, J\}\) é determinada pelo vetor de limiares \(\boldsymbol{\gamma}\) (referenciado internamente no software como phi), onde o primeiro corte \(\gamma_1\) é restrito a zero por definição. Consequentemente, os valores ajustados para beta, rho e phi representam as médias a posteriori das distribuições dos parâmetros estimados via MCMC. Para fins de diagnóstico e inferência estatística, o objeto (modelo ajustado) armazena não apenas essas médias pontuais e os valores ajustados, mas também as cadeias completas de simulação (bdraw, pdraw, phidraw) e os metadados da matriz de pesos \(\mathbf{W}\), permitindo ao pesquisador avaliar a convergência e a incerteza associada aos parâmetros espaciais e aos cortes.
O Modelo Tobit Espacial é a extensão para processos espaciais onde a variável dependente observada é contínua, mas sujeita a censura. Esta situação ocorre frequentemente quando a variável de interesse assume um valor limite (comumente zero) para uma proporção substantiva das observações, enquanto apresenta variação contínua acima desse limite. Exemplos incluem dados de despesas, fluxos comerciais ou níveis de poluição, onde muitas unidades registram zero, mas os valores positivos são contínuos [@lesage2009introduction].
A aplicação de um modelo Tobit padrão, que assume independência entre as observações, ou de um modelo linear espacial, que ignora a censura, a dados com tais características produz estimadores viesados e inconsistentes dos parâmetros de interesse.
O modelo é formulado utilizando uma variável latente contínua não observada, \(y_i^*\), que segue um processo autorregressivo espacial. Para o Modelo Tobit Espacial Autorregressivo (SAR Tobit), a equação estrutural é [@lesage2009introduction]:
A variável observada \(y_i\) relaciona-se com sua contraparte latente através da seguinte regra de censura à esquerda no limiar zero:
\[
y_i = \max(0, y_i^*).
\]
Aqui, \(\mathbf{W}\) é a matriz de pesos espaciais, \(\rho\) o parâmetro de autocorrelação espacial, \(\mathbf{X}\) a matriz de covariáveis e \(\boldsymbol{\beta}\) o vetor de coeficientes.
A introdução da dependência espacial na variável latente tem implicações importantes na estrutura do erro na forma reduzida. Resolvendo a equação estrutural para o vetor latente \(\mathbf{y}^*\), obtém-se:
Definindo o termo de erro composto como \(\tilde{\boldsymbol{\epsilon}} = (\mathbf{I}_n - \rho \mathbf{W})^{-1}\boldsymbol{\epsilon}\), sua matriz de covariância é:
Conforme demonstrado por @mcmillen1992probit, os elementos da diagonal principal desta matriz não são constantes. Cada variância \(\tilde{\sigma}_i^2\) é uma função da localização da unidade \(i\) na rede definida por \(\mathbf{W}\). Esta heterocedasticidade induzida espacialmente na forma reduzida do modelo é uma consequência direta da dependência espacial. Em modelos não lineares como o Tobit, a violação do pressuposto de homocedasticidade leva à inconsistência do estimador de máxima verossimilhança padrão, não apenas a uma perda de eficiência [@bille2019spatial; @kelejian2017spatial].
A função de verossimilhança para o modelo Tobit Espacial envolve a probabilidade conjunta de observar os valores \(\mathbf{y}\), o que requer a integração sobre uma distribuição normal multivariada truncada, com a dimensão da integral igual ao número de observações censuradas. Este cálculo é computacionalmente intratável para amostras de tamanho moderado ou grande.
A literatura propõe várias estratégias para superar este obstáculo:
Algoritmo EM (Expectation-Maximization): @mcmillen1992probit adaptou o algoritmo EM para este contexto. O método itera entre um passo E, que imputa os valores esperados da variável latente \(y_i^*\) para as observações censuradas (condicional nos parâmetros atuais), e um passo M, que maximiza a verossimilhança de um modelo espacial linear contínuo utilizando os dados latentes completos. Embora produza estimativas consistentes, a obtenção de erros-padrão válidos é não trivial.
Abordagem Bayesiana (MCMC com Aumento de Dados): Esta é uma abordagem robusta e amplamente utilizada, detalhada por @lesage2000bayesian e @lesage2009introduction. O método emprega amostragem de Gibbs e uma estratégia de aumento de dados (data augmentation), tratando os valores latentes das observações censuradas como parâmetros a serem estimados. O algoritmo amostra sequencialmente das seguintes distribuições condicionais completas:
Os parâmetros \((\boldsymbol{\beta}, \rho, \sigma^2)\) condicionais ao vetor latente completo \(\mathbf{y}^*\). Dado \(\mathbf{y}^*\), o problema reduz-se à estimação de um modelo SAR Bayesiano padrão.
A variável latente \(\mathbf{y}^*\) condicional aos parâmetros e aos dados observados \(\mathbf{y}\). Para uma observação não censurada (\(y_i > 0\)), temos \(y_i^* = y_i\).
Para uma observação censurada (\(y_i = 0\)), amostra-se \(y_i^*\) de uma distribuição normal truncada à esquerda em zero, \(y_i^* | \cdot \sim \mathcal{N}_{(-\infty, 0]}(E[y_i^* | \cdot], \operatorname{Var}(y_i^* | \cdot))\), onde a média e a variância condicionais incorporam a dependência espacial dos vizinhos.
Esta abordagem fornece a distribuição a posteriori completa dos parâmetros, tratando adequadamente a incerteza associada aos valores censurados e à estrutura de dependência.
Métodos de Simulação (GHK): Técnicas de simulação, como o simulador GHK, podem ser empregadas para aproximar a integral da verossimilhança [@fleming2004techniques]. No entanto, o custo computacional pode tornar-se proibitivo para amostras grandes com alta proporção de censura.
Antes de uma estimação de um modelo complexo, é recomendável testar a presença de dependência espacial nos resíduos de um modelo Tobit padrão (teste de especificação). @kelejian2017spatial propõem versões generalizadas do teste I de Moran adaptadas para resíduos de modelos Tobit.
No modelo Tobit Espacial, a interpretação dos coeficientes \(\boldsymbol{\beta}\) não é direta. O efeito de uma mudança em uma covariável \(x_{ik}\) sobre o valor esperado da variável observada \(E[y_i | \mathbf{X}]\) é não linear e depende do multiplicador espacial global \((\mathbf{I}_n - \rho \mathbf{W})^{-1}\) e da probabilidade de a observação não ser censurada.
Seguindo a decomposição de @lesage2009introduction, é necessário calcular os efeitos médios diretos, indiretos (de transbordamento) e totais.
O efeito direto médio captura o impacto esperado de uma mudança em \(x_{ik}\) sobre \(y_i\), incluindo os feedbacks espaciais que retornam à unidade \(i\).
O efeito indireto médio captura o impacto esperado da mudança em \(x_{ik}\) sobre todos os outros \(y_j\) (\(j \neq i\)), ou seja, os spillovers espaciais.
O efeito total médio é a soma dos dois.
Estes efeitos são calculados a partir das derivadas parciais de \(E[\mathbf{y} | \mathbf{X}]\) em relação a \(\mathbf{x}_k\), que envolvem a matriz \((\mathbf{I}_n - \rho \mathbf{W})^{-1}\) e os termos da função de distribuição normal associados à probabilidade de censura. Como variam entre observações, a prática padrão é reportar suas médias amostrais.
Os modelos vistos até aqui (CAR, SAR, GNS e seus casos particulares) fundamentam-se na premissa de estacionariedade espacial, assumindo que a relação funcional entre a variável dependente e as variáveis explicativas permanece invariante em todo o domínio geográfico. Por exemplo, ao modelar o preço de imóveis no município de São Paulo, esses modelos pressupõem que o impacto de uma variável (como a área construída) é idêntico em todas as regiões. Contudo, em fenômenos geográficos, essa premissa é frequentemente violada, caracterizando a não estacionariedade ou heterogeneidade espacial [@brunsdon1996geographically]. Na prática, bairros periféricos, como os da Zona Leste (por exemplo, Guaianases, Jardim Ângela e São Mateus), podem apresentar uma valorização marginal menor por metro quadrado, enquanto bairros nobres, como Vila Madalena, Pinheiros, Vila Mariana, Higienópolis, Jardim Paulista e Moema, podem apresentar uma valorização superior devido a fatores de localização e infraestrutura.
@sachdeva2022do demonstram, utilizando modelagem local, que é possível decompor o preço de um imóvel em componentes estruturais e um valor intrínseco da localização (capturado pelo intercepto local), permitindo quantificar quanto se paga apenas por estar em um determinado lugar, ceteris paribus. A aplicação de modelos globais a processos espacialmente heterogêneos tende a produzir estimativas de parâmetros que representam médias espaciais enganosas, mascarando variações locais relevantes e induzindo a erros de especificação [@fotheringham2002geographically; @fotheringham2017multiscale].
Para abordar esta limitação, desenvolveram-se abordagens de modelagem local, entre as quais a Regressão Geograficamente Ponderada (GWR) e a Regressão Geograficamente Ponderada Multiescalar (MGWR).
1.15.1 Regressão Geograficamente Ponderada (GWR)
A Regressão Geograficamente Ponderada (GWR) é uma técnica de análise espacial local que estende o modelo de regressão linear clássico, permitindo que os coeficientes variem continuamente no espaço. Em vez de estimar um único conjunto de parâmetros globais \(\boldsymbol{\beta}\), a GWR estima um conjunto distinto de parâmetros \(\boldsymbol{\beta}(u_i, v_i)\) para cada localização \(i\) da amostra [@fotheringham2002geographically].
O modelo GWR para uma observação na localização \(i\), com coordenadas \((u_i, v_i)\), é expresso por:
\(y_i\) é o valor da variável dependente na localização \(i\);
\(x_{ik}\) é o valor da \(k\)-ésima variável independente na localização \(i\);
\(\beta_k(u_i, v_i)\) é o coeficiente de regressão local para a \(k\)-ésima variável independente na localização \(i\);
\(\epsilon_i\) é o termo de erro estocástico, tipicamente assumido como \(\epsilon_i \sim \mathcal{N}(0, \sigma^2)\).
A estimação dos parâmetros locais \(\hat{\boldsymbol{\beta}}(u_i, v_i)\) é realizada através do método de Mínimos Quadrados Ponderados (WLS), onde a ponderação é função da proximidade espacial. O estimador para a localização \(i\) é:
Cada elemento diagonal \(w_{ij}\) representa o peso atribuído à observação \(j\) quando o modelo é calibrado para a localização \(i\). Estes pesos são determinados por uma função kernel. Embora o kernel Gaussiano seja comum, @gollini2015gwmodel destacam a importância de experimentar diferentes funções, como o kernel Bi-quadrado ou Box-car. O kernel Bi-quadrado, por exemplo, oferece eficiência computacional e um corte claro de influência, sendo definido como:
\[
w_{ij} = \begin{cases}
\left[1 - (d_{ij}/b)^2\right]^2 & \text{se } d_{ij} < b \\
0 & \text{caso contrário}
\end{cases}
\] onde \(b > 0\) é o parâmetro de largura de banda (ver outras em [@gollini2015gwmodel]), que controla o decaimento espacial da influência. Para \(i = j\), \(d_{ii} = 0\), resultando no peso máximo \(w_{ii} = 1\). Conforme \(d_{ij}\) aumenta, \(w_{ij}\) tende assintoticamente a zero, implementando a primeira lei da Geografia de Tobler.
A seleção da largura de banda ótima \(b\) é fundamental, representando um compromisso entre viés e variância. Valores pequenos de \(b\) produzem estimativas locais de alta variância (overfitting), enquanto valores grandes introduzem viés, aproximando o modelo de uma regressão global.
A seleção da largura de banda ótima \(b\) pode ser definida de duas formas principais: Fixa (uma distância constante para todas as unidades) ou Adaptativa (um número fixo de \(N\) vizinhos mais próximos). @guo2008comparison demonstram empiricamente que, em dados com agrupamento espacial, kernels adaptativos tendem a capturar melhor a heterogeneidade local do que kernels fixos, que podem suavizar excessivamente os padrões em áreas densas e sofrer com escassez de dados em áreas dispersas.
Mais do que um parâmetro técnico de ajuste, @fotheringham2022notion argumentam que a largura de banda deve ser interpretada como um indicador da escala do processo espacial. Segundo os autores, o valor ótimo de \(b\) é determinado por três características do processo:
Variabilidade do parâmetro: Processos altamente heterogêneos exigem larguras de banda pequenas.
Dependência espacial: Processos com forte autocorrelação espacial tendem a resultar em larguras de banda menores.
Força do processo (ruído): Relações fracas ou com alto nível de erro (\(\sigma^2\)) tendem a resultar em larguras de banda maiores, pois o modelo precisa “emprestar” mais dados para reduzir a incerteza da estimativa.
A otimização de \(b\) geralmente busca minimizar critérios como a Validação Cruzada (CV) ou o Critério de Informação de Akaike corrigido (AICc) [@hurvich1998regression; @fotheringham2002geographically]:
\[
\text{AICc} = 2n \ln(\hat{\sigma}) + n \ln(2\pi) + n \frac{n + \text{tr}(\mathbf{S})}{n - 2 - \text{tr}(\mathbf{S})}.
\]
Nesta expressão, \(\text{tr}(\mathbf{S})\) é o traço da matriz chapéu (hat matrix) \(\mathbf{S}\), que mapeia os valores observados \(\mathbf{y}\) para os preditos \(\hat{\mathbf{y}}\), representando o número efetivo de parâmetros.
Na GWR a matriz \(\mathbf{S}\) é construída linha por linha, pois cada observação \(i\) possui sua própria matriz de pesos \(\mathbf{W}(i)\).
Conforme derivado por @yu2019inference, o valor predito \(\hat{y}_i\) é obtido multiplicando-se o vetor de covariáveis da observação \(i\), denotado por \(\mathbf{x}_i\) (um vetor linha), pelos parâmetros estimados localmente:
Definindo o vetor linha \(\mathbf{r}_i = \mathbf{x}_i (\mathbf{X}^\top \mathbf{W}(i) \mathbf{X})^{-1} \mathbf{X}^\top \mathbf{W}(i)\), a matriz completa \(\mathbf{S}\) de dimensão \(n \times n\) é formada pelo empilhamento destes vetores:
Assim, temos a relação matricial \(\hat{\mathbf{y}} = \mathbf{S}\mathbf{y}\). O traço desta matriz, \(\text{tr}(\mathbf{S})\), utilizado no denominador do AICc, representa a soma das influências de cada observação sobre o seu próprio valor predito, fornecendo uma medida da complexidade do modelo equivalente aos graus de liberdade em modelos lineares generalizados [@fotheringham2002geographically].
Embora a minimização do AICc ou a Validação Cruzada (CV) sejam procedimentos padrão, a literatura recente aponta limitações nestes métodos automáticos. @guo2008comparison alertam que o critério AICc tende a ser conservador, selecionando frequentemente larguras de banda maiores que suavizam excessivamente os padrões espaciais, obscurecendo heterogeneidades locais biologicamente ou socialmente relevantes em favor de um ajuste global mais estável.
Adicionalmente, @dasilva2018comparing demonstram que a função objetivo de Validação Cruzada em modelos GWR com kernels adaptativos frequentemente não é estritamente convexa, apresentando múltiplos mínimos locais. O uso de algoritmos de otimização padrão, como a Busca de Seção Áurea (Golden Section Search), pode convergir para soluções sub-ótimas, sugerindo a necessidade de algoritmos mais robustos como o Lightning Search Algorithm (ver @Shareef2015LightningSearch) ou abordagens híbridas de divisão de intervalo para garantir a identificação do mínimo global.
Alternativamente, @koc2022bandwidth propõe a substituição dos critérios clássicos por critérios de Complexidade de Informação (ICOMP). Ao penalizar não apenas o número de parâmetros, mas também a interdependência (estrutura de covariância) entre as estimativas dos parâmetros, o ICOMP demonstrou, em estudos de simulação e aplicações reais, selecionar larguras de banda que produzem modelos com maior precisão preditiva e melhor equilíbrio entre viés e variância do que o AICc ou CV.
A inferência estatística na GWR, como o cálculo de intervalos de confiança e testes de hipóteses para os parâmetros locais, requer a estimação da variância dos coeficientes locais. Reformulando a GWR como um modelo aditivo generalizado (GAM), @yu2019inference fornecem a expressão para a matriz de covariância dos estimadores:
onde \(\mathbf{C} = [\text{diag}(\mathbf{X}_j)]^{-1}\mathbf{R}_j\) e \(\mathbf{R}_j\) é a matriz de projeção específica da covariável. Isso permite o cálculo de erros-padrão locais precisos e o ajuste dos valores críticos da distribuição \(t\) para evitar falsos positivos, garantindo que a heterogeneidade espacial detectada seja estatisticamente significante e não apenas ruído aleatório.
A reformulação do modelo GWR em modelo GAM, consistiu em não olhar o GWR como uma soma de produtos entre coeficientes variáveis e covariáveis. O vetor de resposta \(\mathbf{y}\) é modelado como uma soma de funções suaves (smooth functions) mais um termo de erro:
No contexto da GWR, cada termo aditivo \(\mathbf{f}_j\) representa o componente espacial da \(j\)-ésima variável explicativa. Este termo é definido como o produto elemento a elemento entre a covariável e seu coeficiente espacialmente variável:
onde \(\mathbf{X}_j\) é o vetor \(n \times 1\) contendo as observações da \(j\)-ésima variável independente, \(\text{diag}(\mathbf{X}_j)\) é uma matriz diagonal com esses valores, e \(\boldsymbol{\beta}_j\) é o vetor \(n \times 1\) dos parâmetros locais para a variável \(j\) em todas as localizações.
A calibração do modelo gera uma matriz de projeção específica \(\mathbf{R}_j\) para cada covariável, tal que o valor ajustado para o componente \(j\) é:
\[\hat{\mathbf{f}}_j = \mathbf{R}_j \mathbf{y}\]
Combinando as definições, temos que \(\text{diag}(\mathbf{X}_j) \hat{\boldsymbol{\beta}}_j = \mathbf{R}_j \mathbf{y}\). Isolando o vetor de parâmetros estimados \(\hat{\boldsymbol{\beta}}_j\), obtemos uma expressão linear em relação a \(\mathbf{y}\):
onde definimos a matriz linear transformadora como \(\mathbf{C}_j = [\text{diag}(\mathbf{X}_j)]^{-1} \mathbf{R}_j\).
Com o estimador \(\hat{\boldsymbol{\beta}}_j\) expresso como uma combinação linear da variável resposta (\(\mathbf{C}_j \mathbf{y}\)), a derivação de sua variância torna-se direta, aplicando as propriedades de variância de operadores lineares (\(\text{Var}(\mathbf{A}\mathbf{y}) = \mathbf{A}\text{Var}(\mathbf{y})\mathbf{A}^\top\)):
Este formalismo permite a construção de estatísticas \(t\) locais (\(t_{ij} = \hat{\beta}_{ij} / SE(\hat{\beta}_{ij})\)). Contudo, a realização de testes individuais para cada localização incorre no problema de comparações múltiplas. Para mitigar o aumento da taxa de erro tipo I sem a severidade excessiva da correção de Bonferroni, @dasilva2016multiple propõem o ajuste do nível de significância \(\alpha\) baseando-se no número efetivo de parâmetros (\(\text{ENP}_j = \text{tr}(\mathbf{R}_j)\)) específico de cada covariável, garantindo que a heterogeneidade espacial detectada seja estatisticamente significativa.
Uma limitação inerente do modelo GWR é a suposição de uma única escala espacial para todos os processos, uma vez que utiliza uma largura de banda \(b\) comum a todas as variáveis independentes. Como notado por [@yang2011extension; @Yang2014FlexibleBandwidthGWR] e formalizado por @fotheringham2017multiscale, diferentes processos (ex: renda, clima, topografia) operam em escalas distintas. Esta restrição motivou o desenvolvimento da Regressão Geograficamente Ponderada Multiescalar (MGWR).
A aplicação da GWR impõe uma restrição: a suposição de que todos os processos modelados operam na mesma escala espacial. Isto decorre da estimação de uma única largura de banda ótima \(b\) para todas as covariáveis simultaneamente. Contudo, em sistemas geográficos complexos, é intuitivo e frequentemente observado que diferentes preditores influenciem a variável resposta em escalas distintas [@fotheringham2017multiscale; @Yang2014FlexibleBandwidthGWR].
Por exemplo, em um modelo de preços imobiliários, a influência da proximidade a uma centralidade metropolitana pode variar suavemente em uma escala regional (processo de larga escala), enquanto o efeito da qualidade da infraestrutura local (como pavimentação) pode mudar abruptamente entre quarteirões adjacentes (processo de escala local). A imposição de uma largura de banda única na GWR introduz viés nas estimativas de processos localmente heterogêneos (ao suavizá-los excessivamente) e aumenta a variância das estimativas de processos globalmente estáveis (ao torná-las desnecessariamente ruidosas) [@fotheringham2002geographically].
Adicionalmente, estudos demonstram que o uso de uma largura de banda única pode exacerbar problemas de multicolinearidade local e concurvidade (colinearidade funcional em modelos não paramétricos), levando a coeficientes instáveis e de difícil interpretação [@wheeler2005multicollinearity]. @oshan2020targeting evidenciam, em um estudo sobre determinantes espaciais da obesidade, que a GWR consome excessivos graus de liberdade ao forçar a modelagem local de processos que são, na verdade, globais. Isto resulta em sobreajuste e perda de parcimônia. A abordagem multiescalar, ao permitir que processos globais sejam modelados como tal (com larguras de banda tendendo ao infinito), produz modelos mais parcimoniosos, com menor AICc e diagnósticos de colinearidade mais robustos.
A MGWR relaxa a suposição de homogeneidade de escala da GWR, permitindo que cada covariável possua sua própria largura de banda ótima \(bw_j\). Isto transforma a largura de banda de um parâmetro de suavização em um indicador empírico das propriedades espaciais intrínsecas de cada relação causal investigada [@fotheringham2017multiscale].
O modelo MGWR para uma observação na localização \(i\) é formalmente especificado como:
onde a notação \(\beta_j(\cdot; bw_j)\) enfatiza que a superfície do coeficiente associado à \(j\)-ésima covariável é estimada utilizando uma função kernel com largura de banda específica \(bw_j\). O intercepto \(\beta_0\) também possui sua própria escala, \(bw_0\).
Diferentemente da GWR, que possui uma solução em forma fechada via Mínimos Quadrados Ponderados para cada localização, a MGWR não tem uma solução analítica direta devido à dependência mútua das superfícies de coeficientes estimadas com diferentes larguras de banda. A estratégia padrão de estimação reformula o problema dentro da estrutura dos Modelos Aditivos Generalizados (GAMs) [@yu2019inference].
O modelo é reescrito como uma soma de funções suaves:
onde cada termo aditivo \(\mathbf{f}_j\) é um vetor \(n \times 1\) que representa a contribuição espacialmente suave da \(j\)-ésima covariável. No contexto da MGWR, \(\mathbf{f}_j = \text{diag}(\mathbf{x}_j) \, \boldsymbol{\beta}_j\), com \(\boldsymbol{\beta}_j\) sendo o vetor de coeficientes locais para a covariável \(j\).
A estimação é realizada através de um algoritmo iterativo de back-fitting, inspirado na estimação de GAMs [@hastie1990generalized]. O procedimento, detalhado por @fotheringham2017multiscale e @yu2019inference, segue os seguintes passos:
Inicialização: As funções \(\hat{\mathbf{f}}_j^{(0)}\) são inicializadas, por exemplo, com as estimativas de um modelo de regressão linear ou de uma GWR com banda única.
Iteração (Back-fitting): Para cada covariável \(j = 0, 1, \dots, p\) na iteração \([k+1]\):
Calcula-se o resíduo parcial removendo a contribuição atual de todas as outras covariáveis: \[
\mathbf{r}_j^{[k]} = \mathbf{y} - \sum_{l < j} \hat{\mathbf{f}}_l^{[k+1]} - \sum_{l > j} \hat{\mathbf{f}}_l^{[k]}.
\]
Ajusta-se um modelo GWR univariado do resíduo parcial \(\mathbf{r}_j^{[k]}\) contra a covariável \(\mathbf{x}_j\). Nesta etapa, otimiza-se a largura de banda específica \(bw_j\) que minimiza um critério de informação (usualmente o AICc) para este submodelo.
Atualiza-se a estimativa da função: \(\hat{\mathbf{f}}_j^{[k+1]} = \text{diag}(\mathbf{x}_j) \, \hat{\boldsymbol{\beta}}_j^{[k+1]}\), onde \(\hat{\boldsymbol{\beta}}_j^{[k+1]}\) é o vetor de coeficientes obtido do modelo GWR univariado calibrado com \(bw_j^{[k+1]}\).
Convergência: O algoritmo itera até que a mudança nas estimativas dos coeficientes ou na soma dos quadrados dos resíduos entre iterações sucessivas seja inferior a um limiar pré-definido (ex: \(10^{-5}\)). @Yang2014FlexibleBandwidthGWR introduz o conceito de Score of Change (SOC) para monitorar esta convergência.
A estabilidade deste processo depende do algoritmo de otimização utilizado para encontrar cada \(bw_j\). Conforme destacado por @dasilva2018comparing, a superfície do critério de seleção (AICc ou CV) para larguras de banda adaptativos é frequentemente não convexa e multimodal. Portanto, métodos robustos como a busca exaustiva em grade (grid search) ou algoritmos heurísticos são preferíveis ao método padrão de Busca da Seção Áurea para evitar mínimos locais subóptimos.
A principal inovação da MGWR é a capacidade de interpretar as larguras de banda \(bw_j\) como métricas da escala espacial de cada processo. Baseando-se na teoria desenvolvida por @fotheringham2022notion, pode-se inferir que:
\(bw_j\) pequeno: Indica um processo localmente heterogêneo, onde a relação entre \(x_j\) e \(y\) muda rapidamente no espaço. Isto pode ser causado por alta variabilidade do parâmetro verdadeiro ou por forte dependência espacial de curto alcance.
\(bw_j\) grande (próximo de \(n\)): Indica um processo regional ou globalmente estável, onde a relação é aproximadamente constante no espaço. Quando \(bw_j \to \infty\), o coeficiente \(\beta_j\) converge para uma constante, recuperando a estacionariedade do modelo OLS.
A análise dessas escalas não deve ser estática. @lu2023uncovering demonstram, em um estudo longitudinal do mercado imobiliário, que as larguras de banda ótimas podem evoluir temporalmente, refletindo mudanças na estrutura subjacente do fenômeno (ex.: a influência de áreas verdes tornar-se mais localizada após a implementação de políticas urbanas específicas).
Para realizar inferência estatística na MGWR, é necessário estimar a variância das superfícies de coeficientes. @yu2019inference estendem o arcabouço de inferência da GWR para o caso multiescalar.
O modelo MGWR completo pode ser representado por uma única matriz de projeção (ou hat matrix) \(\mathbf{S}_{MGWR}\), tal que \(\hat{\mathbf{y}} = \mathbf{S}_{MGWR} \, \mathbf{y}\). Esta matriz é complexa de derivar analiticamente, mas pode ser entendida como o resultado da composição das operações de back-fitting. A contribuição de cada covariável é associada a uma matriz de suavização \(\mathbf{S}_j(bw_j)\).
A variância do estimador para o vetor de coeficientes da covariável \(j\), \(\hat{\boldsymbol{\beta}}_j\), é dada por:
Os erros-padrão locais para \(\hat{\beta}_j(u_i, v_i)\) são as raízes quadradas dos elementos diagonais correspondentes de \(\text{Var}(\hat{\boldsymbol{\beta}}_j)\). Estatísticas \(t\) locais podem então ser construídas para testar hipóteses pontuais (ex.: \(\beta_j(u_i, v_i) = 0\)).
Contudo, a realização de testes simultâneos em centenas ou milhares de localizações incorre no problema de comparações múltiplas. @dasilva2016multiple propõem uma correção baseada no Número Efetivo de Parâmetros (ENP) específico de cada superfície. O nível de significância \(\alpha\) é ajustado utilizando \(ENP_j = \text{tr}(\mathbf{S}_j(bw_j))\) como uma medida dos graus de liberdade consumidos pela covariável \(j\), oferecendo um controle mais adequado da taxa de erro tipo I do que a correção de Bonferroni excessivamente conservadora.
A lógica multiescalar foi estendida para incorporar explicitamente a dimensão temporal, resultando no modelo MGWR Espaço-Temporal (MGTWR) [@wu2018multiscale; @fotheringham2020]. Nesta formulação, cada covariável possui uma largura de banda espacial (\(h_S\)) e uma largura de banda temporal (\(h_T\)) específicas, definidas por um kernel espaço-temporal (ex.: produto de kernels separáveis).
O modelo MGTWR permite discriminar processos que são (1) espacialmente locais mas temporalmente estáveis (ex.: efeito de uma escola no preço da habitação); (2) espacialmente globais mas temporalmente voláteis (ex.: impacto de uma política monetária nacional).
A calibração envolve a otimização conjunta de \(h_S\) e \(h_T\) para cada termo, aumentando a complexidade computacional, mas oferecendo uma representação mais rica da dinâmica espaço-temporal.
A flexibilidade da MGWR tem facilitado sua integração com fontes de dados não tradicionais e de alta dimensão. Exemplos incluem:
Imagens de Street View e Visão Computacional: @he2022multiscale utilizaram a MGWR para modelar a relação entre características visuais extraídas do Google Street View (vegetação, manutenção de edifícios) e taxas de criminalidade em Nova York, revelando que a influência de certas características varia espacialmente em escalas diferentes.
Dados de mobilidade e redes sociais: @liu2023multiscale aplicaram a MGWR para analisar como diferentes fatores socioeconômicos, em diferentes escalas espaciais, explicam padrões de uso do transporte público derivados de dados de cartões inteligentes.
Nestes contextos, a MGWR frequentemente supera modelos tradicionais (OLS, SLM, SEM, GWR padrão) em medidas de ajuste (\(R^2\) ajustado, AICc) e capacidade explicativa, por sua aptidão em capturar a multiescalaridade inerente a processos urbanos e sociais complexos.
Code
if (!require("pacman")) install.packages("pacman")pacman::p_load(GWmodel, sf, sp, ggplot2, viridis, gridExtra, kableExtra, dplyr, ggspatial)#CALIBRAÇÃO DO MODELO MGWR mgwr_model <-gwr.multiscale(formula = Y ~ X1 + X2,data = mg_sp,kernel ="bisquare",adaptive =TRUE, criterion ="dCVR", # Critério de convergência robustothreshold =1e-5, # Tolerância para convergênciamax.iterations =100, predictor.centered =c(TRUE, TRUE) # Centralizar X1 e X2)
—— Calculate the initial bandwidths for each independent variable —— Now select an optimum bandwidth for the model: Y~1 [1] “bws0[i]<-bw.gwr(Y~1,data=regression.points,kernel=kernel,approach=approach,adaptive=adaptive,dMat=dMats[[var.dMat.indx[i]]], parallel.method=parallel.method,parallel.arg=parallel.arg)” Adaptive bandwidth (number of nearest neighbours): 534 AICc value: 5108.313 Adaptive bandwidth (number of nearest neighbours): 338 AICc value: 5024.466 Adaptive bandwidth (number of nearest neighbours): 215 AICc value: 4988.935 Adaptive bandwidth (number of nearest neighbours): 141 AICc value: 4974.096 Adaptive bandwidth (number of nearest neighbours): 93 AICc value: 4967.439 Adaptive bandwidth (number of nearest neighbours): 65 AICc value: 4969.396 Adaptive bandwidth (number of nearest neighbours): 111 AICc value: 4969.312 Adaptive bandwidth (number of nearest neighbours): 82 AICc value: 4967.451 Adaptive bandwidth (number of nearest neighbours): 100 AICc value: 4967.842 Adaptive bandwidth (number of nearest neighbours): 89 AICc value: 4967.256 Adaptive bandwidth (number of nearest neighbours): 86 AICc value: 4967.559 Adaptive bandwidth (number of nearest neighbours): 90 AICc value: 4967.335 Adaptive bandwidth (number of nearest neighbours): 87 AICc value: 4967.546 Adaptive bandwidth (number of nearest neighbours): 89 AICc value: 4967.256 Now select an optimum bandwidth for the model: Y~X1 [1] “bws0[i]<-bw.gwr(Y~X1,data=regression.points,kernel=kernel,approach=approach,adaptive=adaptive,dMat=dMats[[var.dMat.indx[i]]], parallel.method=parallel.method,parallel.arg=parallel.arg)” Adaptive bandwidth (number of nearest neighbours): 534 AICc value: 4405.382 Adaptive bandwidth (number of nearest neighbours): 338 AICc value: 4196.427 Adaptive bandwidth (number of nearest neighbours): 215 AICc value: 4092.447 Adaptive bandwidth (number of nearest neighbours): 141 AICc value: 4040.078 Adaptive bandwidth (number of nearest neighbours): 93 AICc value: 4016.505 Adaptive bandwidth (number of nearest neighbours): 65 AICc value: 4021.724 Adaptive bandwidth (number of nearest neighbours): 111 AICc value: 4022.917 Adaptive bandwidth (number of nearest neighbours): 82 AICc value: 4015.8 Adaptive bandwidth (number of nearest neighbours): 75 AICc value: 4016.762 Adaptive bandwidth (number of nearest neighbours): 86 AICc value: 4015.667 Adaptive bandwidth (number of nearest neighbours): 89 AICc value: 4015.827 Adaptive bandwidth (number of nearest neighbours): 84 AICc value: 4016.029 Adaptive bandwidth (number of nearest neighbours): 87 AICc value: 4015.536 Adaptive bandwidth (number of nearest neighbours): 88 AICc value: 4015.645 Adaptive bandwidth (number of nearest neighbours): 87 AICc value: 4015.536 Now select an optimum bandwidth for the model: Y~X2 [1] “bws0[i]<-bw.gwr(Y~X2,data=regression.points,kernel=kernel,approach=approach,adaptive=adaptive,dMat=dMats[[var.dMat.indx[i]]], parallel.method=parallel.method,parallel.arg=parallel.arg)” Adaptive bandwidth (number of nearest neighbours): 534 AICc value: 4416.663 Adaptive bandwidth (number of nearest neighbours): 338 AICc value: 4203.26 Adaptive bandwidth (number of nearest neighbours): 215 AICc value: 4094.814 Adaptive bandwidth (number of nearest neighbours): 141 AICc value: 4045.604 Adaptive bandwidth (number of nearest neighbours): 93 AICc value: 4030.648 Adaptive bandwidth (number of nearest neighbours): 65 AICc value: 4034.646 Adaptive bandwidth (number of nearest neighbours): 111 AICc value: 4033.74 Adaptive bandwidth (number of nearest neighbours): 82 AICc value: 4029.413 Adaptive bandwidth (number of nearest neighbours): 75 AICc value: 4029.958 Adaptive bandwidth (number of nearest neighbours): 86 AICc value: 4029.663 Adaptive bandwidth (number of nearest neighbours): 79 AICc value: 4029.528 Adaptive bandwidth (number of nearest neighbours): 83 AICc value: 4029.424 Adaptive bandwidth (number of nearest neighbours): 80 AICc value: 4029.383 Adaptive bandwidth (number of nearest neighbours): 80 AICc value: 4029.383 —— The end for the initial selections —— Calculate the initial beta0 from the above bandwidths. End of calculating the inital beta0. Find the optimum bandwidths for each independent variable. Iteration 1 Now select an optimum bandwidth for the variable: Intercept The newly selected bandwidth for variable: Intercept is 32 The bandwidth used in the last iteration is: 89 and the difference in bandwidths is: 57 The bandwidth for variable Intercept will be continually selected in the next iteration. Now select an optimum bandwidth for the variable: X1 The newly selected bandwidth for variable: X1 is 97 The bandwidth used in the last iteration is: 87 and the difference in bandwidths is: 10 The bandwidth for variable X1 will be continually selected in the next iteration. Now select an optimum bandwidth for the variable: X2 The newly selected bandwidth for variable: X2 is 238 The bandwidth used in the last iteration is: 80 and the difference in bandwidths is: 158 The bandwidth for variable X2 will be continually selected in the next iteration. Iteration 1 change of RSS (dCVR) is 0.0572369. Iteration 2 Now select an optimum bandwidth for the variable: Intercept The newly selected bandwidth for variable: Intercept is 32 The bandwidth used in the last iteration is: 32 and the difference in bandwidths is: 0 The bandwidth for variable Intercept seems to be converged for 1 times. It will be continually optimized in the next 4 times Now select an optimum bandwidth for the variable: X1 The newly selected bandwidth for variable: X1 is 130 The bandwidth used in the last iteration is: 97 and the difference in bandwidths is: 33 The bandwidth for variable X1 will be continually selected in the next iteration. Now select an optimum bandwidth for the variable: X2 The newly selected bandwidth for variable: X2 is 267 The bandwidth used in the last iteration is: 238 and the difference in bandwidths is: 29 The bandwidth for variable X2 will be continually selected in the next iteration. Iteration 2 change of RSS (dCVR) is 0.0819936. Iteration 3 Now select an optimum bandwidth for the variable: Intercept The newly selected bandwidth for variable: Intercept is 32 The bandwidth used in the last iteration is: 32 and the difference in bandwidths is: 0 The bandwidth for variable Intercept seems to be converged for 2 times. It will be continually optimized in the next 3 times Now select an optimum bandwidth for the variable: X1 The newly selected bandwidth for variable: X1 is 130 The bandwidth used in the last iteration is: 130 and the difference in bandwidths is: 0 The bandwidth for variable X1 seems to be converged for 1 times. It will be continually optimized in the next 4 times Now select an optimum bandwidth for the variable: X2 The newly selected bandwidth for variable: X2 is 267 The bandwidth used in the last iteration is: 267 and the difference in bandwidths is: 0 The bandwidth for variable X2 seems to be converged for 1 times. It will be continually optimized in the next 4 times Iteration 3 change of RSS (dCVR) is 0.0417213. Iteration 4 Now select an optimum bandwidth for the variable: Intercept The newly selected bandwidth for variable: Intercept is 32 The bandwidth used in the last iteration is: 32 and the difference in bandwidths is: 0 The bandwidth for variable Intercept seems to be converged for 3 times. It will be continually optimized in the next 2 times Now select an optimum bandwidth for the variable: X1 The newly selected bandwidth for variable: X1 is 130 The bandwidth used in the last iteration is: 130 and the difference in bandwidths is: 0 The bandwidth for variable X1 seems to be converged for 2 times. It will be continually optimized in the next 3 times Now select an optimum bandwidth for the variable: X2 The newly selected bandwidth for variable: X2 is 267 The bandwidth used in the last iteration is: 267 and the difference in bandwidths is: 0 The bandwidth for variable X2 seems to be converged for 2 times. It will be continually optimized in the next 3 times Iteration 4 change of RSS (dCVR) is 0.0116581. Iteration 5 Now select an optimum bandwidth for the variable: Intercept The newly selected bandwidth for variable: Intercept is 32 The bandwidth used in the last iteration is: 32 and the difference in bandwidths is: 0 The bandwidth for variable Intercept seems to be converged for 4 times. It will be continually optimized in the next 1 times Now select an optimum bandwidth for the variable: X1 The newly selected bandwidth for variable: X1 is 130 The bandwidth used in the last iteration is: 130 and the difference in bandwidths is: 0 The bandwidth for variable X1 seems to be converged for 3 times. It will be continually optimized in the next 2 times Now select an optimum bandwidth for the variable: X2 The newly selected bandwidth for variable: X2 is 267 The bandwidth used in the last iteration is: 267 and the difference in bandwidths is: 0 The bandwidth for variable X2 seems to be converged for 3 times. It will be continually optimized in the next 2 times Iteration 5 change of RSS (dCVR) is 0.00850599. Iteration 6 Now select an optimum bandwidth for the variable: Intercept The newly selected bandwidth for variable: Intercept is 32 The bandwidth used in the last iteration is: 32 and the difference in bandwidths is: 0 The bandwidth for variable Intercept seems to be converged and will be kept the same in the following iterations. Now select an optimum bandwidth for the variable: X1 The newly selected bandwidth for variable: X1 is 130 The bandwidth used in the last iteration is: 130 and the difference in bandwidths is: 0 The bandwidth for variable X1 seems to be converged for 4 times. It will be continually optimized in the next 1 times Now select an optimum bandwidth for the variable: X2 The newly selected bandwidth for variable: X2 is 267 The bandwidth used in the last iteration is: 267 and the difference in bandwidths is: 0 The bandwidth for variable X2 seems to be converged for 4 times. It will be continually optimized in the next 1 times Iteration 6 change of RSS (dCVR) is 0.00497904. Iteration 7 Now select an optimum bandwidth for the variable: X1 The newly selected bandwidth for variable: X1 is 130 The bandwidth used in the last iteration is: 130 and the difference in bandwidths is: 0 The bandwidth for variable X1 seems to be converged and will be kept the same in the following iterations. Now select an optimum bandwidth for the variable: X2 The newly selected bandwidth for variable: X2 is 267 The bandwidth used in the last iteration is: 267 and the difference in bandwidths is: 0 The bandwidth for variable X2 seems to be converged and will be kept the same in the following iterations. Iteration 7 change of RSS (dCVR) is 0.00280838. Iteration 8 Iteration 8 change of RSS (dCVR) is 0.00156492. Iteration 9 Iteration 9 change of RSS (dCVR) is 0.000868011. Iteration 10 Iteration 10 change of RSS (dCVR) is 0.000480783. Iteration 11 Iteration 11 change of RSS (dCVR) is 0.000266314. Iteration 12 Iteration 12 change of RSS (dCVR) is 0.000147614. Iteration 13 Iteration 13 change of RSS (dCVR) is 8.18955e-05. Iteration 14 Iteration 14 change of RSS (dCVR) is 4.54831e-05. Iteration 15 Iteration 15 change of RSS (dCVR) is 2.52891e-05. Iteration 16 Iteration 16 change of RSS (dCVR) is 1.4078e-05. Iteration 17 Iteration 17 change of RSS (dCVR) is 7.84706e-06.
O pacote GWmodel[@gollini2015gwmodel] é um pacote mais abrangente e usado para modelo GWR. Desenvolvido por Binbin Lu, Paul Harris, Martin Charlton, Chris Brunsdon e colaboradores, o pacote implementa tanto GWR assim como MGWR.
Principais funcionalidades
A escolha da largura de banda é crucial em modelos GW, controlando o grau de suavização espacial. O pacote oferece funções especializadas:
bw.gwr(): Seleciona a largura de banda ótima para GWR
bw.ggwr()**: Para modelos GWR generalizados (Poisson ou Binomial)
bw.gwr.lcr(): Para modelos GWR com compensação local de ridge
bw.gwpca(): Para Análise de Componentes Principais Geograficamente Ponderada
bw.gwda(): Para Análise Discriminante Geograficamente Ponderada
bw.gtwr(): Para Regressão Geográfica e Temporalmente Ponderada
bw.gwss.average(): Para estatísticas descritivas geograficamente ponderadas
Ajuste do modelo
gwr.basic(): Ajusta o modelo GWR básico, produzindo estimativas locais de coeficientes
gwr.robust(): Versões robustas resistentes a outliers
gwr.hetero(): Modelos GWR heterocedásticos
gwr.mixed()**: GWR mista (semiparamétrica)
gwr.lcr(): GWR com compensação local de ridge para colinearidade